第一次用JAVA进行爬虫,参考了很多大佬的博客,然后自己觉得JSOUP比较好理解,就用JSOUP解析搞了个小项目
jsoup中文文档参考:https://www.open-open.com/jsoup/selector-syntax.htm
后续将会再此项目中继续加入翻页爬取、连接数据库、存入数据库等功能,到时再更新。
目录
Db
存放连接数据库的代码(暂时还没开始弄,等后续再更新)
Main
程序执行的入口
Model
存放数据的属性的代码
Parse
存放解析网页的代码
Util
存放各种工具类代码
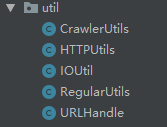
Crawler
爬虫工具类
HTTP
响应客户端工具类
IO
文件输入输出工具类类
Regular
正则表达式工具类
URL
超链接处理工具类
在此次的JAVA爬虫中,我只使用了HTTP和URL两个工具类
Jar包
这些包都可以通过搜索下载
好,废话不多说,上代码,代码注释里讲得很清楚
Main
package Main;
import model.myMovie;
import org.apache.http.ParseException;
import org.apache.http.client.HttpClient;
import org.apache.http.impl.client.HttpClientBuilder;
import util.URLHandle;
import java.io.IOException;
import java.util.List;
public class myMovieMain {
public static void main(String[] args) {
System.out.println("正在生成客户端...");
HttpClient client = HttpClientBuilder.create().build();
System.out.println("客户端生成完毕.");
String url = "https://maoyan.com/board/4";
List<myMovie> movieList = null;
//开始解析
try {
System.out.println("开始响应客户端...");
movieList = URLHandle.urlParser(client, url);
System.out.println("响应完成.");
} catch (ParseException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
System.out.println("开始输出结果...");
for(myMovie movie : movieList){
System.out.println(movie);
}
System.out.println("整个结果输出完毕,程序结束.");
}
}
myMovie
package model;
public class myMovie {
private String movieRank;//电影排名
private String movieName;//电影名
private String releaseTime;//评分
public String getMovieRank() {
return movieRank;
}
public void setMovieRank(String movieRank) {
this.movieRank = movieRank;
}
public String getMovieName() {
return movieName;
}
public void setMovieName(String movieName) {
this.movieName = movieName;
}
public String getReleaseTime() {
return releaseTime;
}
public void setReleaseTime(String releaseTime) {
this.releaseTime = releaseTime;
}
@Override
public String toString() {
return "myMovie{" +
"movieRank='" + movieRank + '\'' +
", movieName='" + movieName + '\'' +
", releaseTime='" + releaseTime + '\'' +
'}';
}
}
HTTPUtils
package util;
import org.apache.http.HttpResponse;
import org.apache.http.HttpStatus;
import org.apache.http.HttpVersion;
import org.apache.http.client.HttpClient;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.message.BasicHttpResponse;
import java.io.IOException;
public class HTTPUtils {
public static HttpResponse getHtml(HttpClient client, String url){
//获取响应文件,即HTML,采用get方法获取响应数据
HttpGet getMethod = new HttpGet(url);
HttpResponse response = new BasicHttpResponse(HttpVersion.HTTP_1_1, HttpStatus.SC_OK, "OK");
try {
//通过client执行get方法
response = client.execute(getMethod);
} catch (IOException e) {
e.printStackTrace();
} finally {
//getMethod.abort();
}
return response;
}
}
URLHandle
package util;
import model.myMovie;
import org.apache.http.HttpResponse;
import org.apache.http.client.HttpClient;
import org.apache.http.util.EntityUtils;
import parse.MovieParse;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
public class URLHandle {
public static List<myMovie> urlParser(HttpClient client, String url) throws IOException {
//创建一个接受数据的数组
List<myMovie> data = new ArrayList<>();
//获取响应资源
HttpResponse response = HTTPUtils.getHtml(client,url);
//获取响应状态码
int statusCode = response.getStatusLine().getStatusCode();
System.out.println(statusCode);
if(statusCode == 200) {//200表示成功
//获取响应实体内容,并且将其转换为utf-8形式的字符串编码
String entity = EntityUtils.toString(response.getEntity(),"utf-8");
System.out.println("开始解析...");
data = MovieParse.getData(entity);
System.out.println("URL解析完成.");
} else {
EntityUtils.consume(response.getEntity());//释放资源实体
}
System.out.println("返回数据.");
return data;
}
}
MovieParse
package parse;
import model.myMovie;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import java.util.ArrayList;
import java.util.List;
public class MovieParse {
public static List<myMovie> getData(String entity){
List<myMovie> data = new ArrayList<>();
//采用jsoup解析
Document doc = Jsoup.parse(entity);
//根据页面内容分析出需要的元素
Elements elements = doc.select("dl[class=\"board-wrapper\"]").select("dd");
for(Element element : elements) {
myMovie movie = new myMovie();
movie.setMovieRank(element.select("i.board-index").text());//class等于board-index的i标签
movie.setMovieName(element.select("p[class=\"name\"]").text());//带有class属性的p元素
movie.setReleaseTime(element.select("p[class=\"releasetime\"]").text());
data.add(movie);
}
return data;
}
}