Fashion-Mnist 数据集的评估调参以及代码的实现

1. 读取图片:
# Read image
def read_img(path):
cate = [path+x for x in os.listdir(path) if os.path.isdir(path+x)] # 获取图片和标签
imgs = []
labels = []
for idx, folder in enumerate(cate):
for im in glob.glob(folder + "/*.png"):
print("reading the images:%s"%(im))
img = io.imread(im)
img = cv2.resize(img, (w, h))
img = np.reshape(img, (w, h, c))
img = img / 255
imgs.append(img)
labels.append(formats(idx)) # 定义函数formats将标签0-9转换成一个(10, 1)的数组
return np.asarray(imgs, np.float32), np.asarray(labels, np.int32)
with tf.name_scope('read_img'):
x_train, y_train = read_img(train_path)
x_val, y_val = read_img(test_path)
def formats(idx):
x = np.zeros(10)
x[idx] = 1
return x
2. 打乱图片
def disorder(data, label):
np.random.seed(int(time.time()))
num_example = data.shape[0]
arr = np.arange(num_example)
np.random.shuffle(arr)
data = data[arr]
label = label[arr]
return(data, label)
with tf.name_scope('disorder'):
x_train, y_train = disorder(x_train, y_train)
x_val, y_val = disorder(x_val, y_val)
3. 构建神经网络
这里使用的是L-Net5
def hidden_layer(input_tensor, regularizer, avg_class, resuse):
with tf.variable_scope("C1-conv", reuse=resuse):
conv1_weights = tf.get_variable("weight", [5, 5, 1, 32],
initializer=tf.truncated_normal_initializer(stddev=0.1))
conv1_biases = tf.get_variable("bias", [32], initializer=tf.constant_initializer(0.0))
conv1 = tf.nn.conv2d(input_tensor, conv1_weights, strides=[1, 1, 1, 1],
padding="SAME", use_cudnn_on_gpu=True,)
relu1 = tf.nn.relu(tf.nn.bias_add(conv1, conv1_biases))
with tf.name_scope("S2-max_pool",):
pool1 = tf.nn.max_pool(relu1, ksize=[1, 2, 2, 1],
strides=[1, 2, 2, 1], padding="SAME")
with tf.variable_scope("C3-conv",reuse=resuse):
conv2_weights = tf.get_variable("weight", [5, 5, 32, 64],
initializer=tf.truncated_normal_initializer(stddev=0.1))
conv2_biases = tf.get_variable("bias", [64], initializer=tf.constant_initializer(0.0))
conv2 = tf.nn.conv2d(pool1, conv2_weights, strides=[1, 1, 1, 1], padding="SAME")
relu2 = tf.nn.relu(tf.nn.bias_add(conv2, conv2_biases))
with tf.name_scope("S4-max_pool",):
pool2 = tf.nn.max_pool(relu2, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding="SAME")
shape = pool2.get_shape().as_list()
nodes = shape[1] * shape[2] * shape[3]
reshaped = tf.reshape(pool2, [shape[0], nodes])
with tf.variable_scope("layer5-full1",reuse=resuse):
Full_connection1_weights = tf.get_variable("weight", [nodes, 512], initializer=tf.truncated_normal_initializer(stddev=0.1))
tf.add_to_collection("losses", regularizer(Full_connection1_weights))
Full_connection1_biases = tf.get_variable("bias", [512], initializer=tf.constant_initializer(0.1))
if avg_class ==None:
Full_1 = tf.nn.relu(tf.matmul(reshaped, Full_connection1_weights) + Full_connection1_biases)
else:
Full_1 = tf.nn.relu(tf.matmul(reshaped, avg_class.average(Full_connection1_weights)) + avg_class.average(Full_connection1_biases))
with tf.variable_scope("layer6-full2",reuse=resuse):
Full_connection2_weights = tf.get_variable("weight", [512, 10], initializer=tf.truncated_normal_initializer(stddev=0.1))
tf.add_to_collection("losses", regularizer(Full_connection2_weights))
Full_connection2_biases = tf.get_variable("bias", [10], initializer=tf.constant_initializer(0.1))
if avg_class == None:
result = tf.matmul(Full_1, Full_connection2_weights) + Full_connection2_biases
else:
result = tf.matmul(Full_1, avg_class.average(Full_connection2_weights)) + avg_class.average(Full_connection2_biases)
return result
# 设定形参
x = tf.placeholder(tf.float32, [batch_size ,28,28,1],name="x-input")
y_ = tf.placeholder(tf.float32, [None, 10], name="y-input")
# 前向传播
y = hidden_layer(x,regularizer,avg_class=None,resuse=False)
training_step = tf.Variable(0, trainable=False)
variable_averages = tf.train.ExponentialMovingAverage(0.99, training_step)
variables_averages_op = variable_averages.apply(tf.trainable_variables())
average_y = hidden_layer(x,regularizer,variable_averages,resuse=True)
with tf.name_scope('cross_entropy_mean'):
cross_entropy = tf.nn.sparse_softmax_cross_entropy_with_logits(logits=y, labels=tf.argmax(y_, 1))
cross_entropy_mean = tf.reduce_mean(cross_entropy)
tf.summary.scalar('cross_entropy_mean', cross_entropy_mean)
with tf.name_scope('loss'):
loss = cross_entropy_mean + tf.add_n(tf.get_collection('losses'))
tf.summary.scalar('loss', loss)
with tf.name_scope('learning_rate'):
learning_rate = tf.train.exponential_decay(learning_rate,
training_step, 55000 /batch_size , learning_rate_decay, staircase=True)
tf.summary.scalar('learning_rate', learning_rate)
train_step = tf.train.GradientDescentOptimizer(learning_rate).minimize(loss, global_step=training_step)
with tf.control_dependencies([train_step, variables_averages_op]):
train_op = tf.no_op(name='train')
crorent_predicition = tf.equal(tf.arg_max(average_y,1),tf.argmax(y_,1))
with tf.name_scope('accuracy'):
accuracy = tf.reduce_mean(tf.cast(crorent_predicition,tf.float32))
tf.summary.scalar('accuracy', accuracy)
4. 设置超参数
优化器超参数
Learning Rate
学习率是一个比较重要的超参数。即便是将别人构建的模型用于自己的数据集,也可能需要常识多个不同的学习率。如何选择正确的学习率?学习率太小,会导致收敛太慢,需要很多的epoch才能达到最优点;而太大会导致越过最优点。比较常见的做法是从0.1开始,然后尝试0.01···,不断倍率减小进行尝试。
如果训练误差在缓慢 减小,并且训练完成后仍在减小,可以尝试增大学习率。
如果训练误差在增加,不妨试试减小学习率。
比较好的做法是使学习率能够自适应调整大小。(Learning_rate_decay)
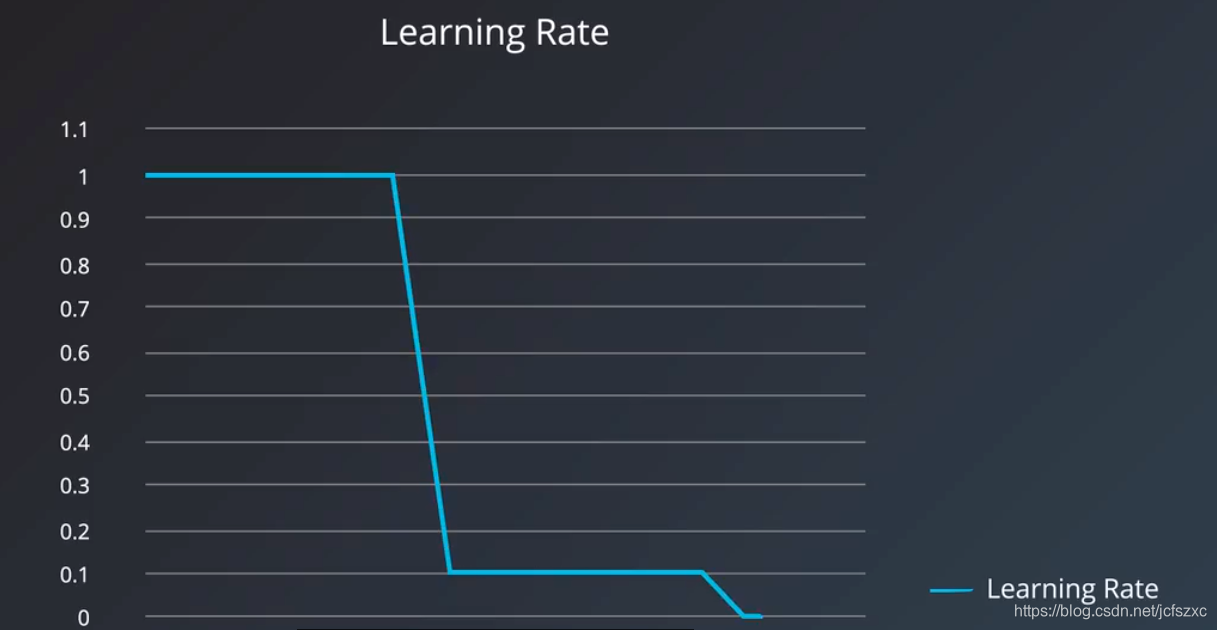
Learning Rate Decay
倍数下降

指数下降
Batch Size
Batch_size的大小对训练过程中的资源要求有影响,也会影响训练速度和迭代次数。较大的batch会使训练过程中矩阵运算加快,但是也需要更多的内存计算空间,遇到内存不足或者Tensorflow错误,可通过减小batch大小来解决。较小的batch会使计算有更多的噪声,有助于防止训练过程陷入局部最优,但是运算缓慢。选择batch需要根据数据集大小和任务进行尝试,通常用32作为初始选择,或者其他的2指数。
Epoch or Max Steps
要选择正确的epoch,我们关注的指标应该为验证误差。直观的方法是尝试不同的epoch,只要验证误差还在降低,就继续迭代。不过我们通常使用一种早期停止的技术,来确定何时停止训练模型。它的原理是监督验证误差,并在验证误差停止下降时停止训练。不过在定义停止触发器时,可以稍微灵活一点,尽管整体呈下降趋势,但验证误差往往会来回波动,因此我们不能在第一次看到验证误差开始增高时就停止训练,而是如果验证误差在最后10步或者20步内没有任何改进的情况下停止训练。
如果epoch数量太少,网络就没有足够的时间学会合适的参数;epoch数量太多则有可能导致网络对训练数据过拟合。
模型超参数
隐藏单元的数量和架构是衡量模型学习能力的主要标准。如果模型的学习能力太多,模型会出现过拟合,结果只会适应训练集而泛化能力弱。如果发现模型出现过拟合,也就是训练准确度远高于验证准确度,你可以尝试减少隐藏单元数量,当然也可以使用正则化技术。如Dropout或者L2正则化。因此就隐藏单元数量来说,不是越多越好,稍微超过理想数量不成问题,但是如果过多,会出现过拟合问题,所以你的模型无法训练,就要对它进行删减或者增添。对于第一个隐藏层,通常是将其设为大于输入层数量的一个数。
5. 批次读取
def next_batches(x_train, y_train, batch_size):
with tf.name_scope('disorder'):
x_train, y_train = disorder(x_train, y_train)
return x_train[:batch_size], y_train[:batch_size]
6. 创建会话
saver = tf.train.Saver() # 保存
merged = tf.summary.merge_all() # 用tensorboard来观察,参数在训练时的变化
with tf.Session() as sess: # 创建会话
tf.global_variables_initializer().run()
writer = tf.summary.FileWriter("log/",sess.graph) # tensorboard 保存路径。
for i in range(max_steps):
if i % 100 == 0:
x_val_a, y_val_a = next_batches(x_val, y_val, batch_size=batch_size)
reshaped_x2 = np.reshape(x_val_a, (batch_size,28, 28, 1))
validate_feed = {x: reshaped_x2, y_: y_val_a}
validate_accuracy = sess.run(accuracy, feed_dict=validate_feed)
print("After %d trainging step(s) ,validation accuracy"
"using average model is %g%%" % (i, validate_accuracy * 100))
y_array = sess.run(y, feed_dict=validate_feed)
y_array = 1 / (1 + np.exp(-y_array))
auc = metrics.roc_auc_score(y_val_a, y_array, average='macro')
fpr, tpr, thresholds = metrics.roc_curve(y_val_a.ravel(),y_array.ravel())
# auc = metrics.auc(fpr, tpr)
# 用plt画roc曲线
plt.plot(fpr, tpr, c = 'green', lw = 6, alpha = 0.7, label = 'AUC=%.3f' % auc)
plt.plot((0, 1), (0, 1), c = '#808080', lw = 1, ls = '--', alpha = 0.7)
plt.xlim((-0.01, 1.02))
plt.ylim((-0.01, 1.02))
plt.xticks(np.arange(0, 1.1, 0.1))
plt.yticks(np.arange(0, 1.1, 0.1))
plt.xlabel('False Positive Rate', fontsize=13)
plt.ylabel('True Positive Rate', fontsize=13)
plt.grid(b=True, ls=':')
plt.legend(loc='lower right', fancybox=True, framealpha=0.8, fontsize=12)
plt.title('ROC', fontsize=17)
plt.show()
x_train_a, y_train_a = next_batches(x_train, y_train, batch_size=batch_size)
reshaped_xs = np.reshape(x_train_a, (batch_size ,28,28,1))
summary,_ = sess.run([merged,train_op], feed_dict={x: reshaped_xs, y_: y_train_a})
writer.add_summary(summary,i)
saver.save(sess,save_path)
7. 观察参数变化
在终端输入
tensorboard --logdir=log
点击网址,即可进入 tensorboard
8. 其他
github代码地址: https://github.com/jcfszxc/tempfile/tree/master/Fashion-Mnist
数据集下载链接:https://www.lanzous.com/i3s30va
欢迎加入集美大学人工智能协会QQ群:283266234