源文件
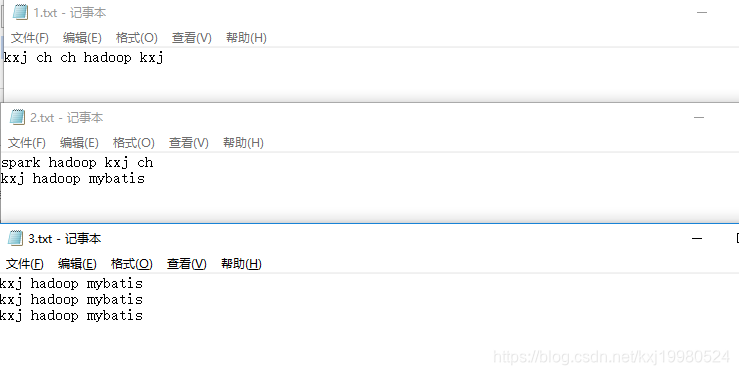
结果 这种结果是倒排索引,就是根据值后面跟一系列这个值在各个文件中出现的次数.
正排索引就是以文件名为索引,后面跟每个文件里所出现的词这种叫正排索引

分两次处理,多job串联
package com.buba.mapreduce.index;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.lib.input.FileSplit;
import java.io.IOException;
public class OneIndexMapper extends Mapper<LongWritable, Text,Text, IntWritable> {
Text k = new Text();
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//1.获取一行
String line = value.toString();
//2.截取
String[] fields = line.split(" ");
//3.获取文件名称
FileSplit fileSplit = (FileSplit)context.getInputSplit();
//文件名称
String name = fileSplit.getPath().getName();
//4.拼接
for(int i = 0; i<fields.length; i++){
k.set(fields[i]+"--"+name);
//5.输出
context.write(k,new IntWritable(1));
}
}
}
package com.buba.mapreduce.index;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class OneIndexReducer extends Reducer<Text, IntWritable,Text,IntWritable> {
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
//累加求和
int count = 0;
for(IntWritable value:values){
count += value.get();
}
//写出去
context.write(key,new IntWritable(count));
}
}
public static void main(String[] args)throws Exception {
//1.获取job信息
Configuration configuration = new Configuration();
Job job = Job.getInstance(configuration);
//2.获取jar的存储路径
job.setJarByClass(OneIndexDriver.class);
//3.关联map和reduce的class类
job.setMapperClass(OneIndexMapper.class);
job.setReducerClass(OneIndexReducer.class);
//4.设置map阶段输出key和value类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
//5.设置最后输入数据的key和value的类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
//6.设置输入数据的路径和输出数据的路径
FileInputFormat.setInputPaths(job,new Path(args[0]));
FileOutputFormat.setOutputPath(job,new Path(args[1]));
//7.提交
boolean b = job.waitForCompletion(true);
System.exit(b?0:1);
}
第一次执行完成这种结果,然后以它为原数据进行第二次jon工作
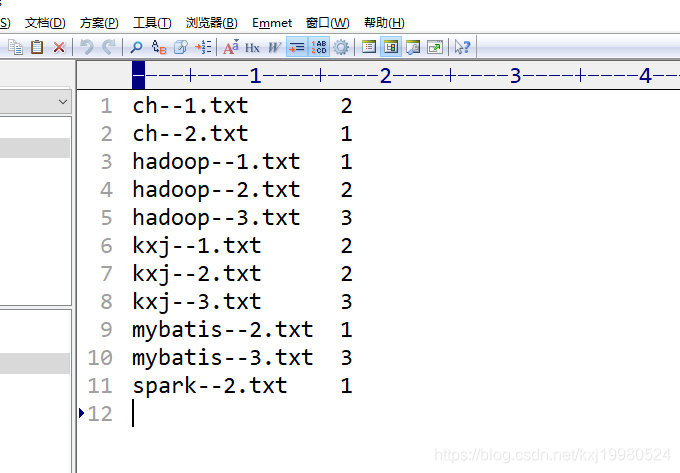
package com.buba.mapreduce.index;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class TwoIndexMapper extends Mapper<LongWritable, Text,Text,Text> {
Text k = new Text();
Text v = new Text();
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String line = value.toString();
String[] fields = line.split("--");
k.set(fields[0]);
v.set(fields[1]);
context.write(k,v);
}
}
package com.buba.mapreduce.index;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class TwoIndexReducer extends Reducer<Text,Text,Text, NullWritable> {
Text text = new Text();
@Override
protected void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException {
String k = key.toString()+"\t";
for(Text text:values){
k += text;
k +="\t";
}
text.set(k);
context.write(text,NullWritable.get());
}
}
package com.buba.mapreduce.index;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class TwoIndexDriver {
public static void main(String[] args)throws Exception {
//1.获取job信息
Configuration configuration = new Configuration();
Job job = Job.getInstance(configuration);
//2.获取jar的存储路径
job.setJarByClass(TwoIndexDriver.class);
//3.关联map和reduce的class类
job.setMapperClass(TwoIndexMapper.class);
job.setReducerClass(TwoIndexReducer.class);
//4.设置map阶段输出key和value类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
//5.设置最后输入数据的key和value的类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(NullWritable.class);
//6.设置输入数据的路径和输出数据的路径
FileInputFormat.setInputPaths(job,new Path(args[0]));
FileOutputFormat.setOutputPath(job,new Path(args[1]));
//7.提交
boolean b = job.waitForCompletion(true);
System.exit(b?0:1);
}
}
