出现背景
随着业务的发展,系统规模也会变得越来越大,各微服务间的调用关系也变越来越错综复杂。通常一个由客户端发起的请求在后端系统中会经过多个不同的微服务调用来协同产生最后的请求结果,在复杂的微服务架构系统中,几乎每一个前端请求都会形成一条复杂的分布式服务调用链路,在每条链路中任何一个依赖服务出现延迟过高或错误的时候都有可能引起请求最后的失败。
所以,对于每个请求,全链路调用的跟踪可以帮助我们快速发现错误以及监控分析每条请求链路上的性能瓶颈。
简单示例
之前文章创建了两个服务,user-service是服务提供者,user-consumer-feign是基于feign的服务消费者。
- 在两个服务中加入依赖

- 启动服务,通过user-consumer-feign服务调用user-service服务,查看日志
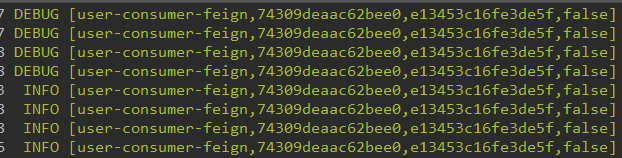

- 解释
- 第一个值:应用的名称;
- 第二个值:Trace ID,用来标识一条请求链路;
- 第三个值:Span ID,标识一个基本的工作单元;
- 第四个值:表示是否要将该信息输出到Zipkin等服务中来收集和展示;
- 在一次服务请求链路的调用过程中,会保持并传递同一个Trace ID,从而将整个分布于不同微服务进程中的请求跟踪信息串联起来。
跟踪原理
两个关键点:
- 当请求发送到分布式系统的入口端点时,只需要服务跟踪框架为该请求创建一个唯一的跟踪标识(Trace ID),同时在分布式系统内部流传的时候,框架始终保持传递该唯一标识,直到返回给请求方为止。
- 为统计各处理单元的时间延迟,当请求到达各个服务组件时,或是处理逻辑到达某个状态时,也通过一个唯一标识来标记它的开始、具体过程以及结束(Span ID)。
引入spring-cloud-starter-sleuth依赖后,会自动为当前应用构建起各通信通道的跟踪机制:
- 通过RabbitMQ、Kafka等传递的请求;
- 通过Zuul代理传递的请求;
- 通过RestTemplate发起的请求。
sleuth会在请求的Header中增加实现跟踪需要的重要信息:
- X-B3-TraceId:请求链路标识
- X-B3-SpanId:工作单元标识
- X-B3-ParentSpanId:上一个工作单元标识
- X-B3-Sampled:是否被抽样输出,1输出,0不输出
- X-Span-Name:工作单元名称
查看更多跟踪信息:
![]()
抽样收集
通过Trace ID和Span ID已经实现了对分布式系统中的请求跟踪,而记录的跟踪信息最终会被分析系统收集起来,并用来实现对分布式系统的监控和分析功能。
在高并发的分布式系统运行时,大量的请求调用会产生海量的跟踪日志信息,如果收集过多的跟踪信息将会对整个分布式系统的性能造成一定的影响,同时保存大量的日志信息也需要不少的存储开销,所以Sleuth中采用了抽样收集的方式。
Sleuth会使用PercentageBasedSampler实现的抽样策略,以请求百分比的方式配置和收集跟踪信息:
![]()
与Logstash整合
由于日志文件都离散地存储在各个服务实例的文件系统之上,仅仅通过查看日志文件来分析请求链路依然是一件相当麻烦的的事,所以需要一些工具来帮助集中收集、存储和搜索这些跟踪信息。比如ELK平台,ELK平台主要由三个开源工具组成:
- ElasticSearch:是一个开源分布式搜索引擎;
- Logstash:对日志进行收集、过滤,并将其存储供以后使用;
- Kibana:为Logstash和ElasticSearch提供日志分析友好的Web界面。
由于Spring Boot应用默认使用logback来记录日志,而Logstash自身也有对logback日志工具的支持工具,所以可以直接通过在logback的配置中增加对Logstash的Appender,就能将日志转换成以JSON的格式存储和输出。