
1.冒泡排序
冒泡排序的思想就是:该排序算法意在从后往前像气泡一样,依次冒出数组中值小的元素;或者从前往后依次冒出数组中值大的元素。
一般冒泡排序的写法
//假设排序arr[] = { 1, 3, 4, 2, 6, 7, 8, 0 };
void BubbleSort(int arr[],int len)
{
int i = 0;
int tmp = 0;
for (i = 0; i < len - 1; i++)//确定排序趟数
{
int j = 0;
for (j = 0; j < len - 1 - i; j++)//确定比较次数
{
if (arr[j]>arr[j + 1])
{
//交换
tmp = arr[j];
arr[j] = arr[j + 1];
arr[j + 1] = tmp;
}
}
}
}
优化一
假设我们现在排序ar[]={1,2,3,4,5,6,7,8,10,9}这组数据,按照上面的排序方式,第一趟排序后将10和9交换已经有序,接下来的8趟排序就是多余的,什么也没做。所以我们可以在交换的地方加一个标记,如果那一趟排序没有交换元素,说明这组数据已经有序,不用再继续下去。
代码实现:
void BubbleSort(int arr[], int len)
{
int i = 0;
int tmp = 0;
for (i = 0; i < len - 1; i++)//确定排序趟数
{
int j = 0;
int flag = 0;
for (j = 0; j < len - 1 - i; j++)//确定比较次数
{
if (arr[j]>arr[j + 1])
{
//交换
tmp = arr[j];
arr[j] = arr[j + 1];
arr[j + 1] = tmp;
flag = 1;//加入标记
}
}
if (flag == 0)//如果没有交换过元素,则已经有序
{
return;
}
}
}
优化二
优化一仅仅适用于连片有序而整体无序的数据(例如:1, 2,3 ,4 ,7,6,5)。但是对于前面大部分是无序而后边小半部分有序的数据(1,2,5,7,4,3,6,8,9,10)排序效率也不可观,对于种类型数据,我们可以继续优化。既我们可以记下最后一次交换的位置,后边没有交换,必然是有序的,然后下一次排序从第一个比较到上次记录的位置结束即可。
代码实现:
void BubbleSort(int arr[], int len)
{
int i = 0;
int tmp = 0;
int flag = 0;
int pos = 0;//用来记录最后一次交换的位置
int k = len - 1;
for (i = 0; i < len - 1; i++)//确定排序趟数
{
pos = 0;
int j = 0;
flag = 0;
for (j = 0; j < k; j++)//确定比较次数
{
if (arr[j]>arr[j + 1])
{
//交换
tmp = arr[j];
arr[j] = arr[j + 1];
arr[j + 1] = tmp;
flag = 1;//加入标记
pos = j;//交换元素,记录最后一次交换的位置
}
}
if (flag == 0)//如果没有交换过元素,则已经有序
{
return;
}
k = pos;//下一次比较到记录位置即可
}
}
优化三
优化二的效率有很大的提升,还有一种优化方法可以继续提高效率。大致思想就是一次排序可以确定两个值,正向扫描找到最大值交换到最后,反向扫描找到最小值交换到最前面。例如:排序数据1,2,3,4,5,6,0
代码实现:
void BubbleSort(int arr[], int len)
{
int i = 0;
int j = 0;
int n = 0;//同时找最大值的最小需要两个下标遍历
int flag = 0;
int pos = 0;//用来记录最后一次交换的位置
int k = len - 1;
for (i = 0; i < len - 1; i++)//确定排序趟数
{
pos = 0;
flag = 0;
//正向寻找最大值
for (j = n; j < k; j++)//确定比较次数
{
if (arr[j]>arr[j + 1])
{
//交换
int tmp = arr[j];
arr[j] = arr[j + 1];
arr[j + 1] = tmp;
flag = 1;//加入标记
pos = j;//交换元素,记录最后一次交换的位置
}
}
if (flag == 0)//如果没有交换过元素,则已经有序,直接结束
{
return;
}
k = pos;//下一次比较到记录位置即可
//反向寻找最小值
for (j = k; j > n; j--)
{
int tmp = arr[j];
arr[j] = arr[j - 1];
arr[j - 1] = tmp;
flag = 1;
}
n++;
if (flag == 0)//如果没有交换过元素,则已经有序,直接结束
{
return;
}
}
}
2.选择排序
它的工作原理是每一次从待排序的数据元素中选出最小(或最大)的一个元素,存放在序列的起始位置,然后,再从剩余未排序元素中继续寻找最小(大)元素,然后放到已排序序列的末尾。以此类推,直到全部待排序的数据元素排完。
代码实现
void SelectSortOP(int *array, int size)
{
//最小值下标
int minpos = 0;
//最大值下标
int maxpos = 0;
int left = 0;
int right = size - 1;
int j = 0;
//循环size-1次
while (left < right)
{
maxpos = left;
minpos = left;
//确定最大值下标以及最小值下标
for (j = left; j <= right; j++)
{
if (array[j]>array[maxpos])
{
maxpos = j;
}
if (array[j] < array[minpos])
{
minpos = j;
}
}
//将最大值插到最后
if (maxpos != right)
{
swap(&array[maxpos], &array[right]);
}
//防止minpos在最大值要插入的位置
if (minpos == right)
{
minpos = maxpos;
}
//将最小值插到最前面
if (minpos != left)
{
swap(&array[minpos], &array[left]);
}
left++;
right--;
}
}
3.直接插入排序
void insert_sort(vector<int>& arr)
{
int len = arr.size();
int i = 1;
for (; i < len; ++i)
{
int key = arr[i];
int j = i - 1;
while (j>=0 && arr[j] > key)
{
arr[j + 1] = arr[j];
j--;
}
arr[j + 1] = key;
}
}
4.希尔排序(基于直接排序)
先取一个小于n的整数d1作为第一个增量,把文件的全部记录分成d1个组。所有距离为dl的倍数的记录放在同一个组中。先在各组内进行直接插人排序;然后,取第二个增量d2<d1重复上述的分组和排序,直至所取的增量dt=1(dt<dt-l<…<d2<d1),即所有记录放在同一组中进行直接插入排序为止。

(1)初始增量为3,该数组分为三组分别进行排序。(初始增量值原则上可以任意设置(0<gap<n),没有限制)
(2)将增量改为2,该数组分为2组分别进行排序。
(3)将增量改为1,该数组整体进行排序。
void shell_sort(vector<int>& arr)
{
int len = arr.size();
int gap;
int i, j;
for (gap = 3; gap > 0; gap--)
{
for (i = 0; i < gap; i++)
{
for (j = i + gap; j < len; j += gap)
{
if (arr[j]<arr[j - gap])
{
//进行直接插入排序
int key = arr[j];
int tmp = j - gap;
while (tmp>=0 && arr[tmp]>key)
{
arr[tmp + gap] = arr[tmp];
tmp -= gap;
}
arr[tmp+gap] = key;
}
}
}
}
}
常见排序算法一般按平均时间复杂度分为两类:
O(n^2):冒泡排序、选择排序、插入排序
O(nlogn):归并排序、快速排序、堆排序
简单排序时间复杂度一般为O(n^2),如冒泡排序、选择排序、插入排序等
高级排序时间复杂度一般为O(nlogn),如归并排序、快速排序、堆排序。
两类算法随着排序集合越大,效率差异越大,在数量规模1W以内的排序,两类算法都可以控制在毫秒级别内完成,但当数量规模达到10W以上后,简单排序往往需要以几秒、分甚至小时才能完成排序;而高级排序仍可以在很短时间内完成排序。
今天所讲的希尔排序是从插入排序进化而来的排序算法,也属于高级排序,只不过时间复杂度为O(n1.5),略逊于其他几种高级排序,但也远远优于O(n2)的简单排序了。希尔排序没有明显的短板,不像归并排序需要大量的辅助空间,也不像快速排序在最坏的情况下和平均情况下执行效率差别比较大,且代码简单,易于实现。
一般在面对中等规模数量的排序时,可以优先使用希尔排序,当发现执行效率不理想时,再改用其他高级排序。
5.归并排序
void _MergeSort(int* a, int left, int right, int* tmp)
{
if (left >= right)
return;
//注意:+的优先级 高于 >>
int mid = left + ((right - left) >> 1);
_MergeSort(a, left, mid, tmp);
_MergeSort(a, mid + 1, right, tmp);
int begin1 = left, end1 = mid;
int begin2 = mid + 1, end2 = right;
int index = left;
while (begin1 <= end1 && begin2 <= end2)
{
if (a[begin1] < a[begin2])
tmp[index++] = a[begin1++];
//注意:else 一定不能省略啊...........
else
tmp[index++] = a[begin2++];
}
while (begin1 <= end1)
tmp[index++] = a[begin1++];
while (begin2 <= end2)
tmp[index++] = a[begin2++];
memcpy(a + left, tmp + left, sizeof(int)*(right - left + 1));
}
void MergeSort(int* a, int n)
{
int* tmp = (int*)malloc(sizeof(int)*n);
_MergeSort(a, 0, n - 1, tmp);
}
int main()
{
int a[5] = { 4, 5, 2, 3, 1 };
MergeSort(a, 5);
return 0;
}
6.快速排序
关于快速排序,由于它的时间复杂度在O(N*logN)效率较高,经常使用。该算法的基本思想:
1. 先从数列中取出一个数作为基准数。
2. 分区过程,将比这个数大的全放到它右边,小于或等于它的全放到它的左边。
3. 再对左右区间重复第二步,直到各区间只有一个数。
MoreWindows对快速排序作了进一步的说明:挖坑填数+分治法
以一个数组作为示例,取区间第一个数为基准数。
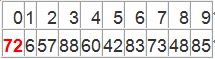
初始时,i = 0; j = 9; X = a[i] = 72
由于已经将a[0]中的数保存到X中,可以理解成在数组a[0]上挖了个坑,可以将其它数据填充到这来。
从j开始向前找一个比X小或等于X的数。当j=8,符合条件,将a[8]挖出再填到上一个坑a[0]中。a[0]=a[8]; i++; 这样一个坑a[0]就被搞定了,但又形成了一个新坑a[8],这怎么办呢?
简单,再找数字来填a[8]这个坑。这次从i开始向后找一个大于X的数,当i=3,符合条件,将a[3]挖出再填到上一个坑中a[8]=a[3]; j–; 数组变为:
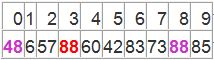
i = 3; j =7; X=72
再重复上面的步骤,先从后向前找,再从前向后找。
从j开始向前找,当j=5,符合条件,将a[5]挖出填到上一个坑中,a[3] = a[5]; i++;
从i开始向后找,当i=5时,由于i==j退出。此时,i = j = 5,而a[5]刚好又是上次挖的坑,因此将X填入a[5]。数组变为:
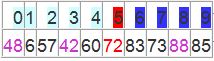
可以看出a[5]前面的数字都小于它,a[5]后面的数字都大于它。因此再对a[0…4]和a[6…9]这二个子区间重复上述步骤就可以了。
对挖坑填数进行总结:
1. i =L; j =R; 将基准数挖出形成第一个坑a[i]。
2. j–由后向前找比它小的数,找到后挖出此数填前一个坑a[i]中。
3. i++由前向后找比它大的数,找到后也挖出此数填到前一个坑a[j]中。
4. 再重复执行2,3二步,直到i==j,将基准数填入a[i]中。
照着这个总结很容易实现挖坑填数的代码:
分治:
void quick_sort1(int s[], int l, int r)
{
if (l < r)
{
int i = AdjustArray(s, l, r);//先成挖坑填数法调整s[]
quick_sort1(s, l, i - 1); // 递归调用
quick_sort1(s, i + 1, r);
}
挖坑填数:
int AdjustArray(int s[], int l, int r) //返回调整后基准数的位置
{
int i = l, j = r;
int x = s[l]; //s[l]即s[i]就是第一个坑
while (i < j)
{
// 从右向左找小于x的数来填s[i]
while(i < j && s[j] >= x)
j--;
if(i < j)
{
s[i] = s[j]; //将s[j]填到s[i]中,s[j]就形成了一个新的坑
i++;
}
// 从左向右找大于或等于x的数来填s[j]
while(i < j && s[i] < x)
i++;
if(i < j)
{
s[j] = s[i]; //将s[i]填到s[j]中,s[i]就形成了一个新的坑
j--;
}
}
//退出时,i等于j。将x填到这个坑中。
s[i] = x;
return i;
}
快速排序的时间复杂度:
在最优的情况下,快速排序算法的时间复杂度为O(nlogn);
在最坏的情况下,待排序的序列为正序或者逆序,每次划分只得到一个比上一次划分少一个记录的子序列,注意另一个为空。如果递归树画出来,它就是一棵斜树。此时需要执行n‐1次递归调用,且第i次划分需要经过n‐i次关键字的比较才能找到第i个记录,也就是枢轴的位置,因此比较次数为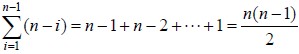 ,最终其时间复杂度为O(n2)。
,最终其时间复杂度为O(n2)。