参考:https://blog.csdn.net/AC_hell/article/details/52875927
一、安装第三方库及配置
1.1 安装插件
pip install whoosh django-haystack jieba
- haystack是django的开源搜索框架,该框架支持Solr,Elasticsearch,Whoosh, *Xapian*搜索引擎,不用更改代码,直接切换引擎,减少代码量。
- 搜索引擎使用Whoosh,这是一个由纯Python实现的全文搜索引擎,没有二进制文件等,比较小巧,配置比较简单,当然性能自然略低。
- 中文分词Jieba,由于Whoosh自带的是英文分词,对中文的分词支持不是太好,故用jieba替换whoosh的分词组件。
其他:Python 2.7 or 3.4.4, Django 1.8.3或者以上,Debian 4.2.6_3
1.2 settings中添加 Haystack 到Django的 INSTALLED_APPS
INSTALLED_APPS = [
'django.contrib.admin',
'django.contrib.auth',
'django.contrib.contenttypes',
'django.contrib.sessions',
'django.contrib.messages',
'django.contrib.staticfiles',
# haystack要放在应用的上面
'haystack',
'blog',
'account',
'article',
]
1.3 settings中增加搜索引擎配置
import os
HAYSTACK_CONNECTIONS = {
'default': {
'ENGINE': 'haystack.backends.whoosh_backend.WhooshEngine',
'PATH': os.path.join(os.path.dirname(__file__), 'whoosh_index'),
},
}
ENGINE为使用的引擎必须要有,如果引擎是Whoosh,则PATH必须要填写,其为Whoosh 索引文件的存放文件夹。
其他引擎的配置见官方文档
二、创建索引
2.1 新建search_indexes.py文件
如果你想针对某个app例如article做全文检索,则必须在article的目录下面建立search_indexes.py文件,且文件名不能修改。内容如下:

import datetime from haystack import indexes from .models import ArticlePost class ArticlePostIndex(indexes.SearchIndex, indexes.Indexable): # 类名必须为需要检索的Model_name+Index,这里需要检索ArticlePost,所以创建ArticlePostIndex类 text = indexes.CharField(document=True, use_template=True) # 创建一个text字段 author = indexes.CharField(model_attr='author') # 创建一个author字段 title = indexes.CharField(model_attr='title') # 创建一个pub_date字段 # body = indexes.CharField(model_attr='body') def get_model(self): # 重载get_model方法,必须要有! # 返回这个model return ArticlePost def index_queryset(self, using=None): # 重载index_..函数 """Used when the entire index for model is updated.""" return self.get_model().objects.filter(updated__lte=datetime.datetime.now())
索引,就像书的目录一样,可以快速的导航查找内容。
每个索引里面必须有且只能有一个字段为 document=True,这代表haystack 和搜索引擎将使用此字段的内容作为索引进行检索(primary field)。其他的字段只是附属的属性,方便调用,并不作为检索数据。
如果使用一个字段设置了document=True,则一般约定此字段名为text,这是在SearchIndex类里面一贯的命名,以防止后台混乱,当然名字你也可以随便改,不过不建议改。
并且,haystack提供了use_template=True在text字段,这样就允许我们使用数据模板去建立搜索引擎索引的文件,说得通俗点就是索引里面需要存放一些什么东西,例如 ArticlePost的 title 字段,
这样我们可以通过 title 内容来检索ArticlePost数据了,举个例子,假如你搜索 python ,那么就可以检索出title含有 python 的ArticlePost了,怎么样是不是很简单?
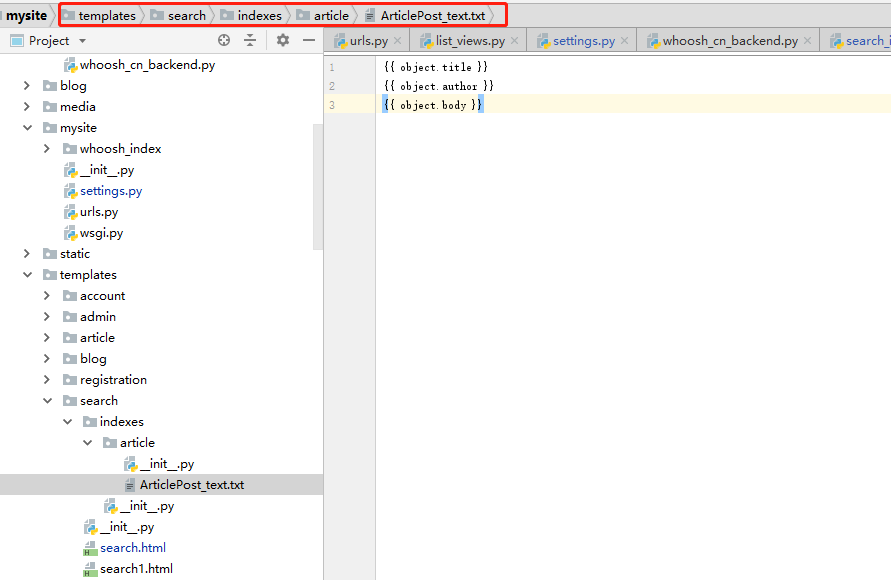
2.2 新建数据模板路径ArticlePost_text.txt
数据模板的路径为templates/search/indexes/article/ArticlePost_text.txt,注意文件的命名格式,一定要是model_text.txt,其内容为:
{{ object.title }}
{{ object.author }}
{{ object.body }}
这个数据模板的作用是对ArticlePost.title,、ArticlePost.authorArticlePost.body这三个字段建立索引,当检索的时候会对这三个字段做全文检索匹配。
2.3 添加url路由
l(r'search/$', SearchView(), name='haystack_search'),
from django.conf.urls import url from . import views, list_views from haystack.views import SearchView urlpatterns=[ url(r'^article-column/$', views.article_column, name='article_column'),
...
... # SearchView()视图函数,默认使用的HTML模板路径为templates/search/search.html url(r'search/$', SearchView(), name='haystack_search'), ]
2.4 新建search.html模板文件
templates/search/search.html,内容为:
{% extends 'base.html' %} {% block title %}文章列表{% endblock %} {% block content %} <div class="col-md-9"> <div class="row text-center vertical-middle-sm"> <h1>搜索结果</h1> </div> {# 如果存在搜索关键字 #} {% if query %} {% for result in page.object_list %}<div class="media"> <a href="{{ result.object.get_absolute_url }}" class="list-group-item active"> {% if result.object.avatar %} <div class="media-left"> <img src="{{ result.object.avatar.url }}" alt="avatar" style="max-width: 100px; border-radius: 20px"> </div> {% endif %} <div class="media-body"> <h4 class="list-group-item-heading">{{ result.object.title }}</h4> <p class="list-group-item-text">作者:{{ result.object.author }}</p> <p class="list-group-item-text">概要:{{ result.object.body|slice:'60'}}</p> </div> </a> </div> {% empty %} <h3>没有找到相关文章</h3> {% endfor %} {% endif %} {# {% include 'paginator.html' %}#}
{# 分页插件,下一页和上一页记得要带上q={{ query }}参数,否则单击下一页时会丢失搜索参数q,而显示出来全部的文章的第二页#} <div class="pagination"> <span class="step-links"> {% if page.has_previous %} <a href="?q={{ query }}&page={{ page.previous_page_number }}">上一页</a> {% endif %} <span class="current"> Page{{ page.number }} of {{ page.paginator.num_pages }} </span> {% if page.has_next %} <a href="?q={{ query }}&page={{ page.next_page_number }}">下一页</a> {% endif %} </span> </div></div> <div class="col-md-3"> <p class="text-center">广告位招租</p> <a href="#"><img src="https://dm30webimages.lynkco.com.cn/LynkCoPortal/Content/images/chenxing2/03yushou/pc/4.jpg" width="260px"></a></div> {% endblock %}
注意一下,<a href="?q={{ query }}&page={{ page.next_page_number }}">下一页</a>,http://127.0.0.1:8000/article/search/?page=2,
此时只有page=2参数,代表的是全部文章的第二页
分页也可以在settings中配置
#设置每页显示的数目,默认为20,可以自己修改
HAYSTACK_SEARCH_RESULTS_PER_PAGE = 5
