dstream.foreachRDD是一个功能强大的原语,允许将数据发送到外部系统。但是,了解如何正确有效地使用此原语非常重要。
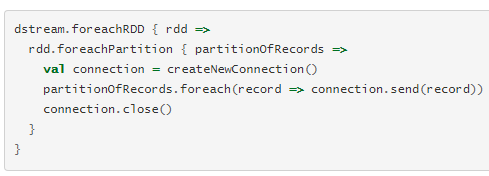
通常将数据写入外部系统需要创建连接对象(例如,与远程服务器的TCP连接)并使用它将数据发送到远程系统。为此,开发人员可能无意中尝试在Spark驱动程序中创建连接对象,然后尝试在Spark工作程序中使用它来保存RDD中的记录。

详情请见官方文档:
https://spark.apache.org/docs/2.0.1/streaming-programming-guide.html
Spark基于RDD进行编程,RDD的数据不能改变,如果擅长foreachPartition底层的数据可能改变,做到的方式foreachPartition操作一个数据结构,RDD里面一条条数据,但是一条条的记录是可以改变的spark也可以运行在动态数据源上。(就像数组的数据不变,但是指向的索引可以改变)
ps:
1.最好使用foreachPartition函数来遍历RDD,在每个work上创建数据库的连接
2.插入数据库最好是批量插入
3.确保能够处理异常(比如写入失败丢失数据,将异常保存在哪都是要注意到的)
from pyspark import SparkContext
from pyspark import SparkConf
from pyspark.streaming import StreamingContext
from pyspark.streaming.kafka import KafkaUtils, TopicAndPartition
from odps import ODPS
# 初始化阿里云配置
access_id = ""
secret_access_key = ""
project = "" # 开发态
# project = ""#生产态
endpoint = "http://service.odps.aliyun.com/api"
table = "" # 表名
# 初始化odps参数
o = ODPS(access_id, secret_access_key, project, endpoint)
# 获取表数据
t = o.get_table(table)
records = []
def start():
sconf = SparkConf()
sconf.set('spark.cores.max', 5)
sc = SparkContext(appName='SparkStreamingKafkaDirect', conf=sconf)
ssc = StreamingContext(sc, 6)
brokers = ""
topic = 'realtime'
start = 70000
partition = 0
user_data = KafkaUtils.createDirectStream(ssc, [topic], kafkaParams={"metadata.broker.list": brokers})
# fromOffsets 设置从起始偏移量消费
# user_data = KafkaUtils.createDirectStream(ssc,[topic],kafkaParams={"metadata.broker.list":brokers},fromOffsets={TopicAndPartition(topic,partition):long(start)})
user_fields = user_data.map(lambda line: line[1].split(' '))
user_data.foreachRDD(offset) # 存储offset信息
user_fields.pprint()
user_fields.foreachRDD(lambda rdd: rdd.foreachPartition(echo)) # 返回元组
# user_fields.saveAsTextFiles("/user/hdfs/source/log/kafkaSs/qwer") # 保存到hdfs中,前缀+时间戳
ssc.start()
ssc.awaitTermination()
offsetRanges = []
def offset(rdd):
global offsetRanges
offsetRanges = rdd.offsetRanges()
def echo(rdd):
# name = rdd[0]
# ids = rdd[1]
global records
try:
for record in rdd:
records.append([record[0], record[1]])
# if len(records) == 10000:
with t.open_writer() as writer:
writer.write(records)
records = []
except IndexError as e:
print('except:', e)
if __name__ == '__main__':
start()