原创不易,转载前请注明博主的链接地址:Blessy_Zhu https://blog.csdn.net/weixin_42555080
本次代码的环境:
运行平台: Windows
Python版本: Python3.x
IDE: PyCharm
一、 前言
在机器学习笔记(二)-感知机一文中已经介绍了,如下图所示:线性分类有硬分类和软分类两中,这篇文章介绍其中软分类的代表模型:判别式模型:逻辑回归(LR:Logistic Regression)。

通过上图可以看到对于软分类问题来说,它又分为概率生成式模型和概率判别式模型。
- 对于判别式来说,它实际上是对P(y|x)进行建模,并且直接求出P(y|x)的值,然后根据p值选择最终y是为0或者为1。如下公式所示:
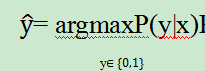
- 对于概率生成式模型来说,它不是直接求得P(y|x)而是借助贝叶斯公式
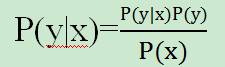
通过先验p(y)和似然P(x|y)去判断大小。也就是说:他并不是直接求得p的值,而是判断P(y=0|x)和P(y=1|x)的大小关系。根据y值和P(x)无关,所以实际上P(y|x)就是正比于P(x,y)的联合概率分布
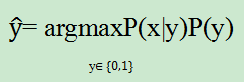
已经了解了什么是生成式和判别式,接下来就正式开始学习线性回归LR
二、 LR核心思想及实现细节
LR的核心思想就是利用Sigmoid Function,将全部实数都压缩到(0,1)的区间上。
2.1 Sigmoid介绍
首先,还是来认识一下sigmoid函数:该函数具有如下的特性:当x趋近于负无穷时,y趋近于0;当x趋近于正无穷时,y趋近于1;当x= 0时,y=0.5.
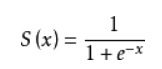
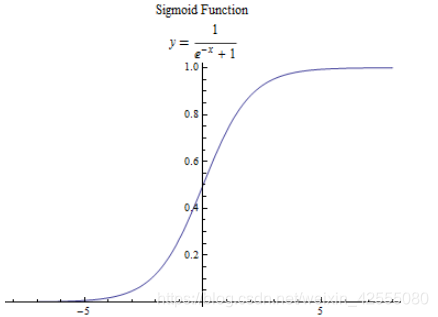
接下来,通过激活函数Sigmoid的映射就可以做到:
2.2 LR介绍
logistic回归又称logistic回归分析,是一种广义的线性回归分析模型,常用于数据挖掘,疾病自动诊断,经济预测等领域。例如,探讨引发疾病的危险因素,并根据危险因素预测疾病发生的概率等。以胃癌病情分析为例,选择两组人群,一组是胃癌组,一组是非胃癌组,两组人群必定具有不同的体征与生活方式等。因此因变量就为是否胃癌,值为“是”或“否”,自变量就可以包括很多了,如年龄、性别、饮食习惯、幽门螺杆菌感染等。自变量既可以是连续的,也可以是分类的。然后通过logistic回归分析,可以得到自变量的权重,从而可以大致了解到底哪些因素是胃癌的危险因素。同时根据该权值可以根据危险因素预测一个人患癌症的可能性。
接下来按照下图这个思路,将WTX映射到Sigmoid函数上去。

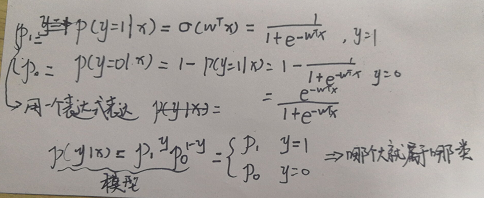
然后根据最大似然估计MLE,求得w值

求得w后,将WX带入到Sigmoid函数中,就可以求得概率。根据概率进行分类。这样就可以实现最终的分类了。
三、 LR的Python实现
3.1 获取并展示数据
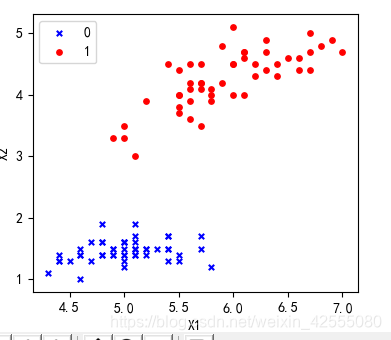
这里使用的是Iris数据集,首先数据进行展示:
from sklearn.datasets import load_iris
import matplotlib.pyplot as plt
import numpy as np
iris = load_iris()
data = iris.data
target = iris.target
#print data[:10]
#print target[10:]
X = data[0:100,[0,2]]
y = target[0:100]
print X[:5]
print y[-5:]
label = np.array(y)
index_0 = np.where(label==0)
plt.scatter(X[index_0,0],X[index_0,1],marker='x',color = 'b',label = '0',s = 15)
index_1 =np.where(label==1)
plt.scatter(X[index_1,0],X[index_1,1],marker='o',color = 'r',label = '1',s = 15)
plt.xlabel('X1')
plt.ylabel('X2')
plt.legend(loc = 'upper left')
plt.show()
3.2 编写LR模型的类
import numpy as np
class logistic(object):
def __init__(self):
self.W = None
def train(self,X,y,learn_rate = 0.01,num_iters = 5000):
num_train,num_feature = X.shape
#init the weight
self.W = 0.001*np.random.randn(num_feature,1).reshape((-1,1))
loss = []
for i in range(num_iters):
error,dW = self.compute_loss(X,y)
self.W += -learn_rate*dW
loss.append(error)
if i%200==0:
print 'i=%d,error=%f' %(i,error)
return loss
def compute_loss(self,X,y):
num_train = X.shape[0]
h = self.output(X)
loss = -np.sum((y*np.log(h) + (1-y)*np.log((1-h))))
loss = loss / num_train
dW = X.T.dot((h-y)) / num_train
return loss,dW
def output(self,X):
g = np.dot(X,self.W)
return self.sigmod(g)
def sigmod(self,X):
return 1/(1+np.exp(-X))
def predict(self,X_test):
h = self.output(X_test)
y_pred = np.where(h>=0.5,1,0)
return y_pred
3.3 训练测试一下,并且可视化跟踪的损失loss
import matplotlib.pyplot as plt
y = y.reshape((-1,1))
#add the x0=1
one = np.ones((X.shape[0],1))
X_train = np.hstack((one,X))
classify = logistic()
loss = classify.train(X_train,y)
print classify.W
plt.plot(loss)
plt.xlabel('Iteration number')
plt.ylabel('Loss value')
plt.show()

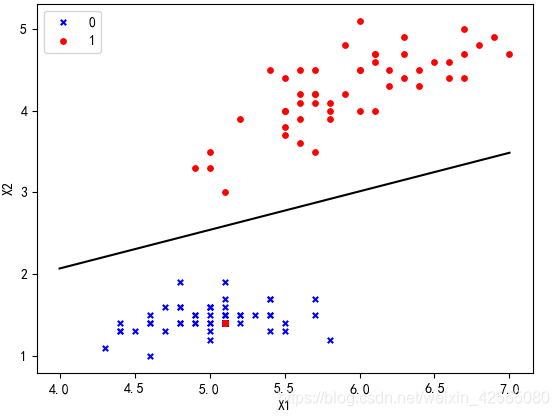
3.4 可视化“决策边界”
label = np.array(y)
index_0 = np.where(label==0)
plt.scatter(X[index_0,0],X[index_0,1],marker='x',color = 'b',label = '0',s = 15)
index_1 =np.where(label==1)
plt.scatter(X[index_1,0],X[index_1,1],marker='o',color = 'r',label = '1',s = 15)
#show the decision boundary
x1 = np.arange(4,7.5,0.5)
x2 = (- classify.W[0] - classify.W[1]*x1) / classify.W[2]
plt.plot(x1,x2,color = 'black')
plt.xlabel('X1')
plt.ylabel('X2')
plt.legend(loc = 'upper left')
plt.show()
四 总结
本篇内容主要介绍了LR逻辑回归分析,并对LR模型进行验证。这篇文章就到这里了,欢迎大佬们多批评指正,也欢迎大家积极评论多多交流。

参考文章
1 Logistic回归
2 机器学习:逻辑回归与Python代码实现
3 Logistic Regression(逻辑回归)原理及公式推导
4 机器学习:逻辑回归与Python代码实现
5 逻辑回归(Logistic Regression)
6 逻辑回归(logistic regression)的本质——极大似然估计