- Mnist是个手写数字的数据集,四个文件如下,可以去官网下到:
- Training set images: train-images-idx3-ubyte.gz (9.9 MB, 解压后 47 MB, 包含 60,000 个样本)
- Training set labels: train-labels-idx1-ubyte.gz (29 KB, 解压后 60 KB, 包含 60,000 个标签)
- Test set images: t10k-images-idx3-ubyte.gz (1.6 MB, 解压后 7.8 MB, 包含 10,000 个样本)
- Test set labels: t10k-labels-idx1-ubyte.gz (5KB, 解压后 10 KB, 包含 10,000 个标签)
它们的数据存储形式都类似,具体这里有描述(拉到最后面):http://yann.lecun.com/exdb/mnist/
首先看看train的label数据,如下

数据以大端存储,以下为我在linux下用hexdump -x train-labels.idx1-ubyte 读取的部分数据

Linux这里是以小端存储的,所以显示出来就会有差别,看这规律应该是两个字节为单位,这两个字节互换了位置,例如0x0801互换后就为0x0108,而60000的16进制表示就为0xea60,互换后为0x60ea,这就是前八个字节的内容,对应上图第一行中的前四组数据,后面每个字节保存一个label,label为0-9,所以后面几个label为5、0、4、1、9、2
再看看train的image数据,如下

以下为linux读取出来的前几个数据

前八个字节类似,不多说了,后面两个1c就是上上个图里的两个28,后面每个字节保存一个像素点的灰度数据,0为白,255为黑,row-wise好像是按行记录的意思,我估计时,像素点从左到右,从上到下的记录。
接下来尝试读取这些数据保存到python变量中,读取代码如下
import os
import struct
import numpy as np
def load_mnist(path, kind='train'):
"""Load MNIST data from `path`"""
#os.path.join can combine the string into a path
labels_path = os.path.join(path, '%s-labels.idx1-ubyte' % kind)
images_path = os.path.join(path, '%s-images.idx3-ubyte' % kind)
with open(labels_path, 'rb') as lbpath:
magic, n = struct.unpack('>II', lbpath.read(8))
labels = np.fromfile(lbpath, dtype=np.uint8)
with open(images_path, 'rb') as imgpath:
magic, num, rows, cols = struct.unpack('>IIII', imgpath.read(16))
images = np.fromfile(imgpath, dtype=np.uint8).reshape(len(labels), 784)
return images, labels
读取出来的labels以list的形式保存了label,我把它前几个打啦出来,如下
>>> import myload_mnist
>>> images,labels=myload_mnist.load_mnist('/home/otagan/Downloads')#加载数据
>>> print labels[0]
5
>>> print labels[1]
0
>>> print labels[2]
4
>>> print labels[3]
1
>>> print labels[4]
9
>>> print labels[5]
2
可以看到,和之前我们用命令行看到的结果一致,
再来看看images,读取出来之后为二维矩阵,60000行,每行有784个数据,我们打出前面几个看看是否与label相对应。代码如下
import myload_mnist #就是之前写的加载数据的代码
images,labels=myload_mnist.load_mnist('/home/otagan/Downloads')#加载数据,目录自己改
from PIL import Image
import numpy as np
for i in range(0,7): #打出前七个看看
#np.reshape把784个数据的行向量转换为28*28的矩阵,np.array将其转换为数组
im_data = np.array(np.reshape(images[i],(28,28)),dtype=np.int8)
print(im_data)
img = Image.fromarray(im_data, 'L')
img.save('%d.jpg'%i) #保存图片
上述load_mnist.py和这个保存图片的代码都放在同一目录下执行,理应执行完目录下会有七张图片,用eog命令显示如下


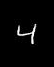
![]()

![]()
![]()
可见,是与label对应的。
在centos中,用Image.open打开图片 255为白色,0为黑色
再来看看《神经网络与深度学习》例程里读取出来的数据格式:
了解教程里的mnist.pkl.gz的数据格式,看它代码注释足以
Load_data()函数返回来的三个数据:training_data, validation_data, test_data
Training_data包含了两个记录(entry,我也不知道是不是这么翻),第一个记录为图片信息,图片信息有5w条,每条代表一张图片,是一维的,包含784个像素点的数据,而第二个记录,为5w个label,即对应图片的数字。Validation_data和test_data类似,以下为一些测试。
>>> import mnist_loader
>>> training_data, validation_data, test_data=mnist_loader.load_data()
>>> print len(training_data)
2
>>> print len(training_data[0])
50000
>>> print len(training_data[0][0])
784
>>> print len(training_data[1])
50000
打出部分图片数据如下:

这里可以看出,数据是float类型,而不是mnist本来的整数,作为对比,我把mnist官网下到数据集也打出来一部分:

容易发现,教程里的数据就是把原先的0-255的整数数据转换为0-1的float类型,例如第一个非零数3,3/255=0.0117
再看看label
>>> print training_data[1][0]
5
这个没什么好说的,没做什么处理。
再看看Load_data_wrapper()函数:
tr_d, va_d, te_d = load_data() #load_data读取数据,没啥好说的
#这里相当于把50000个图片数据矩阵转制了
training_inputs = [np.reshape(x, (784, 1)) for x in tr_d[0]]
#这里用到了vectorized_result()函数,后面有代码,就是把原本只有一个数字的label转为一个
#10行一列的矩阵,用对应行的1代表label值,这应该是为了后面方便神经网络
training_results = [vectorized_result(y) for y in tr_d[1]]
#合成数据
training_data = zip(training_inputs, training_results)
#后面两个类似
validation_inputs = [np.reshape(x, (784, 1)) for x in va_d[0]]
validation_data = zip(validation_inputs, va_d[1])
test_inputs = [np.reshape(x, (784, 1)) for x in te_d[0]]
test_data = zip(test_inputs, te_d[1])
return (training_data, validation_data, test_data)
def vectorized_result(j):
e = np.zeros((10, 1)) #生成一个十行一列的矩阵
e[j] = 1.0 #相应位赋1
return e
我们可以打出来看看
>>> a=np.array(training_data)
>>> print len(a[1])
2
>>> print len(a[0])
2
>>> print len(a)
50000
>>> print a[0][1]#a[0][0]保存了784*1的图像数据,a[0][1]保存了10*1的label数据
[[0.]
[0.]
[0.]
[0.]
[0.]
[1.]
[0.]
[0.]
[0.]
[0.]]
以上。