一、上节回顾
为什么要有多进程?
为了解决多个进程之间的切换
为什么要有多线程?
为了解决减少进程之间切换的开销
并发与并行
并发是指系统具有处理多任务(动作)的能力(CPU的切换),比如你可以一边听音乐一边写博客
并行是指系统具有同时处理多个任务(动作)的能力,多核CPU
并行是并发的一个子集
同步与异步
当进程执行到一个IO操作(等待外部数据)时,如果选择等待,则是属于同步;如果选择暂时跳过,等到数据接收完毕再进行处理,则属于异步。socket里面的recv和accept就属于同步,打电话也是同步,发短信则属于异步。
二、GIL
python3.6下串行和多线程的执行时间比较
串行:执行时间51秒几


def add(): sum=0 for i in xrange(10000000): sum+=i print("sum",sum) def mul(): sum2=1 for i in xrange(1,100000): sum2*=i print("sum2",sum2) start=time.time() add() mul() print("cost time %s"%(time.time()-start))
多线程:执行时间50秒几
def add(): sum=0 for i in xrange(10000000): sum+=i print("sum",sum) def mul(): sum2=1 for i in xrange(1,100000): sum2*=i print("sum2",sum2) import threading,time start=time.time() t1=threading.Thread(target=add) t2=threading.Thread(target=mul) l=[] l.append(t1) l.append(t2) for t in l: t.start() for t in l: #没有这一块代码,最后一句马上就执行了 t.join() print("cost time %s"%(time.time()-start))
我擦,时间竟如此接近,我的电脑可是四核啊,为何多线程也这么慢,那我要你多线程有何用?没错,事实就是如此,而且这两段代码放到2.7.中,你会发现,串行的更快。这是为什么呢?这就得跟你说说GIL的问题了。
什么是GIL
GIL全称是“全局解释器锁”,它其实算是Python解释器的BUG(不是Python这门语言的BUG,python完全可以不依赖于GIL),GIL的存在使得无论你启多少个线程,有多少个cpu,同一时刻只有一个线程会被CPU执行。
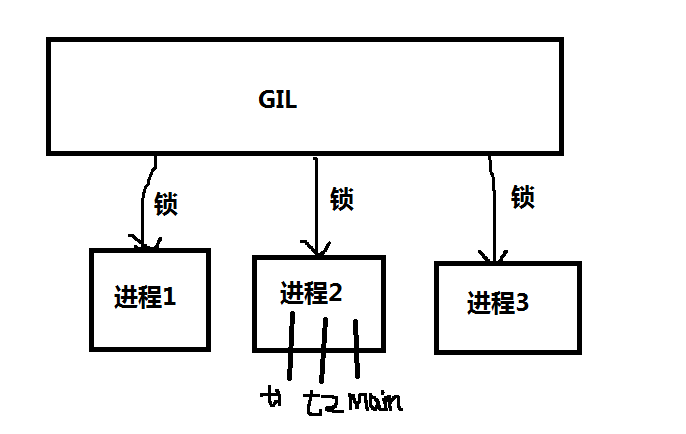
python多线程机制原理
python多线程机制是用C实现的真实系统中线程,这些线程都由操作系统管理,代替python解释器去执行线程
GIL特性
并行执行是禁止的
会存在一个"全局解释器锁"
保证同一时刻只有一个线程被解释器执行(也就是cpu)
简化了底层实现细节,用户无需关心底层如何实现
GIL行为
当前执行的线程持有GIL(线程执行模型)
遇到I/O就释放锁(read、write、send、recv等等),给另外一个线程执行机会
问题:如果遇到计算密集型的线程,一直占用CPU,其他线程是不是就没有机会执行?
不是的,为了避免这种情况,解释器还会周期性的check并执行线程调度
解释器周期性check
check需要完成以下三件事:
复位tick计数器
在主线程中,检查有没有需要处理的信号
让当前执行线程释放(Release)GIL,让其他线程获取(acquire)GIL并执行
而解释器check的周期,默认是100个tick。解释器的tick并不是基于时间的,每个tick大致相当于一条汇编指令的执行时间(tick_check图片)
从解释器的check行为中可以看到,只有主线程中会处理信号,子线程中都不处理信号。所以python多线程程序,会给人一种无法处理Ctrl+C的假象,因为大部分情况下主线程被block住了,无法处理SIGINT信号。
注意python中并没有实现线程调度,python的多线程调度完全依赖于操作系统。所以python多线程编程中没有线程优先级等概念。
GIL的实现
GIL实现图
python的GIL并不是简单的用lock实现的,GIL是用signal实现的。
线程获取(acquire)GIL前,先检查有没有被free,如果没有,就sleep等待signal
更多内容请查看
http://www.dabeaz.com/python/UnderstandingGIL.pdf
http://www.dabeaz.com/python/GIL.pdf
二、同步锁
刚刚给你展示了GIL对计算任务速度的影响,现在给你展示一下GIL对计算任务的值的影响
一个进程下可以启动多个线程,多个线程共享父进程的内存空间,也就意味着每个线程可以访问同一份数据,此时,如果2个线程同时要修改同一份数据,会出现什么状况?
#没有IO阻塞的情况下,结果没有问题 import threading import time def sub(): global num num-=1 print("OK") num=100 l=[] for i in range(100): t=threading.Thread(target=sub) t.start() l.append(t) for t in l: t.join() print num #结果是0,因为在没有IO阻塞的情况下,每个线程处理的时间很充足,小于CPU轮询的时间
#有IO阻塞的情况下,结果就不太理想 import threading import time def sub(): global num temp = num #d多次赋值也会影响最后的结果 time.sleep(0.01) #阻塞的时长影响最后的结果 num=temp-1 num=100 l=[] for i in range(100): t=threading.Thread(target=sub) t.start() l.append(t) for t in l: t.join() print num #结果是0,1,4,7,都有可能
我擦,为什么有IO阻塞的情况下,得出的数值会不一致?
很简单,假设你有A,B两个线程,此时都 要对num 进行减1操作, 由于2个线程是并发同时运行的,所以2个线程很有可能同时拿走了num=100这个初始变量交给cpu去运算,当A线程去处完的结果是99,但此时B线程运算完的结果也是99,两个线程同时CPU运算的结果再赋值给num变量后,结果就都是99。那怎么办呢? 很简单,每个线程在要修改公共数据时,为了避免自己在还没改完的时候别人也来修改此数据,可以给这个数据加一把锁, 这样其它线程想修改此数据时就必须等待你修改完毕并把锁释放掉后才能再访问此数据。
如何解决上面的问题?用同步锁
import threading import time def sub(): global num lock.acquire() #声明我拿到锁了,独占该数据 temp = num time.sleep(0.01) num=temp-1 lock.release() #释放锁,让其他线程去处理该数据 num=100 l=[] lock=threading.Lock() #生成一把锁 for i in range(100): t=threading.Thread(target=sub) t.start() l.append(t) for t in l: t.join() print num #结果是0
有人可能会有疑问,既然Python已经有一个GIL来保证同一时间只能有一个线程来执行了,为什么这里还需要lock? 注意啦,这里的lock是用户级的lock,跟那个GIL没关系 ,具体通过下图来看一下大家就明白了。
同时修改数据图
那你又问了, 既然用户程序已经自己有锁了,那为什么Cpython还需要GIL呢?加入GIL的主要原因是为了降低程序的开发的复杂度,比如现在的你写python不需要关心内存回收的问题,因为Python解释器帮你自动定期进行内存回收,你可以理解为python解释器里有一个独立的线程,每过一段时间它wake up做一次全局轮询看看哪些内存数据是可以被清空的,此时你自己的程序里的线程和py解释器自己的线程是并发运行的,假设你的线程删除了一个变量,py解释器的垃圾回收线程在清空这个变量的过程中的clearing时刻,可能一个其它线程正好又重新给这个还没来及得清空的内存空间赋值了,结果就有可能把新赋值的数据删除了。为了解决类似的问题,python解释器简单粗暴的加了锁,即当一个线程运行时,其它人都不能动。 这可以说是Python早期版本的遗留问题。
你可以简单理解为:GIL是为了保证线程安全,用户锁是为了保证数据安全
OK,上面的问题是解决了,但是你有没有发现上面的代码,加上锁之后就变成了串行了,而且该在哪里加锁,哪里释放锁,都需要自己考虑清楚,这就是同步锁的副作用。而且很有可能会出现死锁,在线程间共享多个资源的时候,如果两个线程分别占有一部分资源并且同时等待对方的资源,就会造成死锁,因为系统判断这部分资源都正在使用,所有这两个线程在无外力作用下将一直等待下去。这么讲,大家也应该不明白,那就看下面死锁的例子。
三、死锁现象
import threading import time class MyThread(threading.Thread): def actionA(self): lockA.acquire() print(self.name,"gotA",time.ctime()) time.sleep(3) lockB.acquire() print(self.name, "gotB", time.ctime()) lockB.release() lockA.release() def actionB(self): lockB.acquire() print(self.name,"gotB",time.ctime()) time.sleep(2) lockA.acquire() print(self.name, "gotA", time.ctime()) lockA.release() lockB.release() def run(self): self.actionA() self.actionB() if __name__=="__main__": lockA=threading.Lock() lockB=threading.Lock() threads=[] for i in range(5): t=MyThread() t.start() threads.append(t) for i in threads: i.join() print("ending...")
假设线程1首先夺得了A锁,那么直到它执行完actionA之前,其他线程根本动都不能动。一旦线程1执行完actionA释放A锁,线程2(假设是它)开始执行actionA,马上抢占了A锁,线程1执行继续actionB,到这一步看起来都很美好,但是接下来就要打架了。线程1在执行actionB抢占B锁后,睡了2秒继续往下走,突然发现A锁被霸占了?因为线程2在actionA里面拿着A锁呢。线程没有人的这种互助互让意识,而且该程序设计的时候,A锁是在执行完actionA后才会释放的,不会在中途释放,所以,这两线程就卡在这里了。
那怎么搞定这个问题啊老铁?
四、递归锁
递归锁的出现就是为了解决死锁问题的,那什么是递归锁?
递归锁顾名思义,锁中锁,说白了就是大锁里面还有小锁。递归锁内部维护了一个计数器,初始值为0,每次上锁加1(acquire),释放锁减1(release),只要count>0,外部没人能拿到。
import threading import time class MyThread(threading.Thread): def actionA(self): r_lock.acquire() #count=1 print(self.name,"gotA",time.ctime()) time.sleep(2) r_lock.acquire() #count=2 print(self.name, "gotB",time.ctime()) time.sleep(1) r_lock.release() #count=1 r_lock.release() #count=0 def actionB(self): r_lock.acquire() #count=1 print(self.name,"gotB",time.ctime()) time.sleep(2) r_lock.acquire() #count=2 print(self.name, "gotA", time.ctime()) time.sleep(1) r_lock.release() #count=1 r_lock.release() #count=0 def run(self): self.actionA() self.actionB() if __name__=="__main__": r_lock=threading.RLock() threads=[] for i in range(5): t=MyThread() t.start() threads.append(t) for i in threads: i.join() print("ending...")
结果:
Thread-1 gotA Tue Apr 24 16:10:25 2018 Thread-1 gotB Tue Apr 24 16:10:27 2018 Thread-1 gotB Tue Apr 24 16:10:28 2018 Thread-1 gotA Tue Apr 24 16:10:30 2018 Thread-3 gotA Tue Apr 24 16:10:31 2018 Thread-3 gotB Tue Apr 24 16:10:33 2018 Thread-3 gotB Tue Apr 24 16:10:34 2018 Thread-3 gotA Tue Apr 24 16:10:36 2018 Thread-5 gotA Tue Apr 24 16:10:37 2018 Thread-5 gotB Tue Apr 24 16:10:39 2018 Thread-5 gotB Tue Apr 24 16:10:40 2018 Thread-5 gotA Tue Apr 24 16:10:42 2018 Thread-4 gotA Tue Apr 24 16:10:43 2018 Thread-4 gotB Tue Apr 24 16:10:45 2018 Thread-4 gotB Tue Apr 24 16:10:46 2018 Thread-4 gotA Tue Apr 24 16:10:48 2018 Thread-2 gotA Tue Apr 24 16:10:49 2018 Thread-2 gotB Tue Apr 24 16:10:51 2018 Thread-2 gotB Tue Apr 24 16:10:52 2018 Thread-2 gotA Tue Apr 24 16:10:54 2018 ending...
五、同步条件(Event)
通过设置标志位,通知另一个线程该执行操作
self.wait() 阻塞住
self.set() 设置标志位
self.clean() 清除标志位
import threading,time class Boss(threading.Thread): def run(self): print("某总:今晚OP要紧急变更修复漏洞!") print(event.isSet()) #标志位还没设定,所以是False event.set() #此时设定标志位,跳到Worker time.sleep(5) print("某总:变更完成,可以下班了各位!") print(event.isSet()) #此时还没设定,因为Worker清除了 event.set() class Worker(threading.Thread): def run(self): event.wait() #一直在这里等着一旦event被设定,等同于pass print("杨老细:正扑街呢噶!") time.sleep(1) event.clear() #把标志位清除了,就回到Boss event.wait() #继续等待,直到下一次标志位被设定再执行下面的print print("杨老细:擦,做到凌晨5点,又无补休!") if __name__=="__main__": event=threading.Event() threads=[] for i in range(5): threads.append(Worker()) threads.append(Boss()) for t in threads: t.start() #结果是Boss先打印,因为Worker在等待。但实际的启动顺序是Worker在前,Boss在后。 for t in threads: t.join() print("ending...")
这个Event也不常用,了解即可。
六、信号量(Semaphore)
信号量是用来控制线程并发数的,它允许一定数量的线程同时更改数据,BoundedSemaphore或Semaphore管理一个内置的计数 器,每当调用acquire()时减1,调release()时加1。计数器不能小于0,当计数器为0时,acquire()将阻塞线程至同步锁定状态,直到其他线程调用release(),类似于停车位的概念。BoundedSemaphore与Semaphore的唯一区别在于前者将在调用release()时检查计数器的值是否超过了计数器的初始值,如果超过了将抛出一个异常。
import threading,time class myThread(threading.Thread): def run(self): if semaphore.acquire(): print(self.name) semaphore.release() if __name__=="__main__": semaphore=threading.Semaphore() thrs=[] for i in range(100): thrs.append(myThread()) for t in thrs: t.start()
同样地,了解即可
七、队列(queue)---多线程利器
使用多线程删除列表中的元素
import threading,time l=[1,2,3,4] def pri(): while l: a=l[-1] print(a) try: l.remove(a) except Exception as e: print("----",a,e) t1=threading.Thread(target=pri,args=()) t1.start() t2=threading.Thread(target=pri,args=()) t2.start()
试了好几次,有时会出现下面这种结果这是由于两个线程同时操作一个数据导致的。这其实也跟列表这种数据结构有关,因为它本身是不安全的。
4 4 3 ---- 4 list.remove(x): x not in list 3 2 1 ---- 3 list.remove(x): x not in list
队列在两个线程进行数据交互的过程表现非常优秀,有效地保证数据的安全,先来介绍一下queue的用法
创建一个“队列”对象 import queue q = queue.Queue(maxsize = 10) queue.Queue类即是一个队列的同步实现。队列长度可为无限或者有限,可通过Queue的构造函数的可选参数maxsize来设定队列长度,如果maxsize小于1就表示队列长度无限。 将一个值放入队列中 q.put(10) 调用队列对象的put()方法在队尾插入一个项目。put()有两个参数,第一个item为必需的,为插入项目的值;第二个block为可选参数,默认为1。如果队列当前为空且block为1,put()方法就使调用线程暂停,直到空出一个数据单元,即阻塞住。如果block为0,put方法将引发Full异常。 将一个值从队列中取出 q.get() 调用队列对象的get()方法从队头"删除"并返回一个项目。可选参数为block,默认为True。如果队列为空且block为True, get()就使调用线程暂停,即阻塞住,直至有项目可用。如果队列为空且block为False,队列将引发Empty异常。 Python3 queue模块有三种队列及构造函数: 1、FIFO队列先进先出 class queue.Queue(maxsize) 2、LIFO类似于堆,即先进后出 class queue.LifoQueue(maxsize) 3、还有一种是优先级队列,级别越低越先出来 class queue.PriorityQueue(maxsize) 此包中的常用方法(q = queue.Queue()): q.qsize() 返回队列的大小 q.empty() 如果队列为空,返回True,反之False q.full() 如果队列满了,返回True,反之False q.full 与 maxsize 大小对应 q.get([block[, timeout]]) 获取队列,timeout等待时间 q.get_nowait() 相当q.get(False),非阻塞 q.put(item) 写入队列,timeout等待时间 q.put_nowait(item) 相当q.put(item, False) q.task_done() 在完成一项工作之后,q.task_done()函数向任务已经完成的队列发送一个信号 q.join() 实际上意味着等到队列为空,再执行别的操作
先进先出
import queue q=queue.Queue(3) q.put(12) q.put("hello") q.put({"name":"yuan"}) #q.put_nowait(56) #不阻塞,满了就报错 print(q.qsize()) #3 print(q.empty()) #False print(q.full()) #True while 1: data=q.get() print(data) print("--------")
先进后出
import queue q=queue.LifoQueue(3) q.put(12) q.put("hello") q.put({"name":"yuan"}) while 1: data=q.get() print(data) print("--------")
优先级,数值越小的先出
import queue q=queue.PriorityQueue(3) q.put([1,12]) q.put([0,"hello"]) q.put([-1,{"name":"yuan"}]) while 1: data=q.get() print(data) print("--------") #结果: # [-1, {'name': 'yuan'}] # -------- # [0, 'hello'] # -------- # [1, 12] # --------
八、生产者消费者模型
为什么要使用生产者和消费者模式
在线程世界里,生产者就是生产数据的线程,消费者就是消费数据的线程。在多线程开发当中,如果生产者处理速度很快,而消费者处理速度很慢,那么生产者就必须等待消费者处理完,才能继续生产数据。同样的道理,如果消费者的处理能力大于生产者,那么消费者就必须等待生产者。为了解决这个问题于是引入了生产者和消费者模式
什么是生产者消费者模式
生产者消费者模式是通过一个容器来解决生产者和消费者的强耦合问题。生产者和消费者彼此之间不直接通讯,而通过阻塞队列来进行通讯,所以生产者生产完数据之后不用等待消费者处理,直接扔给阻塞队列,消费者不找生产者要数据,而是直接从阻塞队列里取,阻塞队列就相当于一个缓冲区,平衡了生产者和消费者的处理能力。
***线程之间共用一个queue
一个简单的生产包子的生产者消费者例子
import time,random import queue,threading q=queue.Queue() def Producer(name): count=0 while count <10: print("making......") time.sleep(5) q.put(count) print("%s has produced bread%s"%(name,count)) count +=1 #q.task_done() q.join() #等待队列发来吃完的信号 print("OK") def Comsumer(name): count =0 while count <10: time.sleep(random.randrange(4))#随机睡几秒 data = q.get() print("eating...") time.sleep(4) q.task_done() #告诉队列我吃完了 print("%s has eat bread%s"%(name,data)) count +=1 p1 = threading.Thread(target=Producer,args=("食神",)) c1 = threading.Thread(target=Comsumer,args=("杨老细",)) c2 = threading.Thread(target=Comsumer,args=("梁老板",)) p1.start() c1.start() c2.start()
join和task_done方法必须成对出现,而且join的一方必须等待task_done一方执行完毕才能够执行,生产者和消费者都可以使用join和task_done方法