交叉验证(Cross Validation)和网格搜索(Grid Search)是机器学习两大法宝,前者用于检验模型的好坏,后者用于模型的调参。
就比如说,你要知道一辆车的好坏,我们需要一个客观公正的评价方法,不然车厂说自己的车好,顾客说这个车坏,我们就无法得到一辆车客观的好坏。在机器学习领域中,我们经常使用一种叫做交叉验证的方法来帮助我们判断模型好坏,那么我们接下来就探讨什么是交叉验证以及怎么使用。
1 K折交叉验证 Cross Validation
-
交叉验证(Cross-validation)主要用于建模应用中,在给定的建模样本中,拿出大部分样本进行建模,
留小部分样本用刚建立的模型进行预报,并求这小部分样本的预报误差,记录他们的平方加和。 -
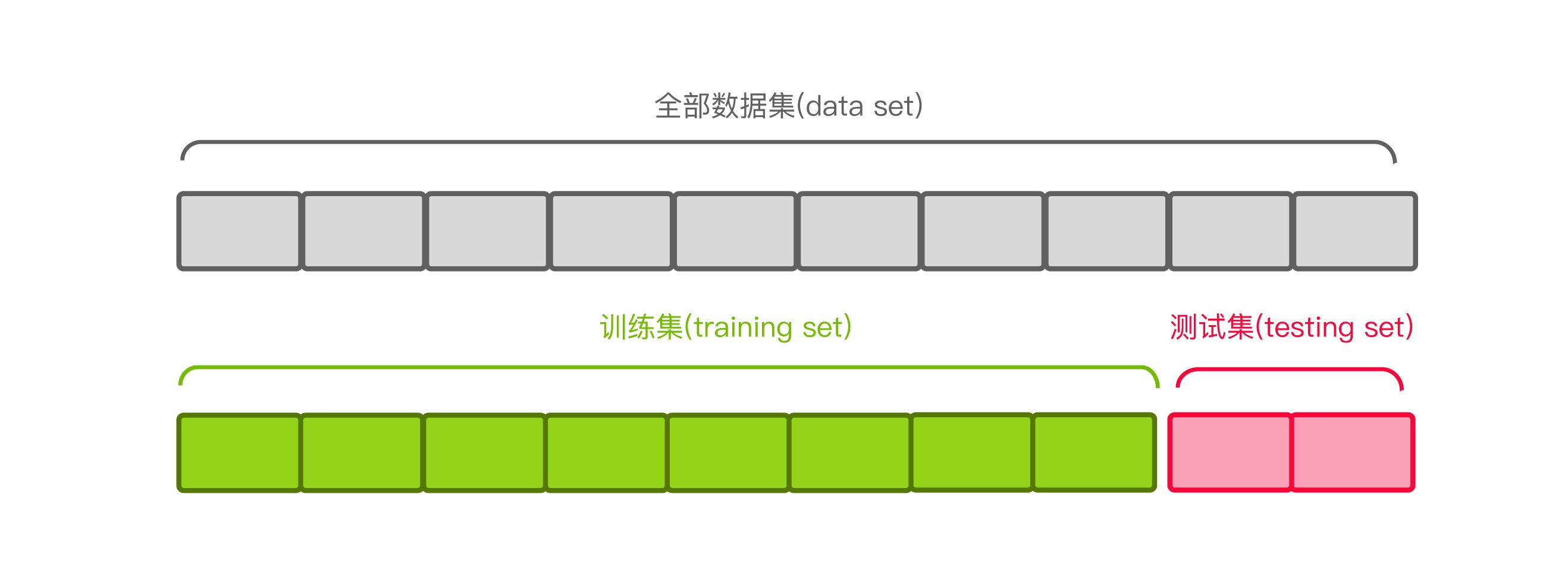
正如下图所示, 交叉验证(Cross Validation)会把一份数据随机分成三个部分:训练集(training set)、验证集(validation set)、测试集(test set), 下面以高考为例,理解不同的数据集.
- 训练集用来训练模型,
就是我们平时做的作业,用于训练自己的能力; - 验证集用于模型的选择,
就是我们的月考、模拟考,用于检验和反馈自己的能力; - 测试集用于最终对学习方法的评估,
就是我们的高考,绝对保密,用于最终告诉你的能力水平(分数);
- 训练集用来训练模型,
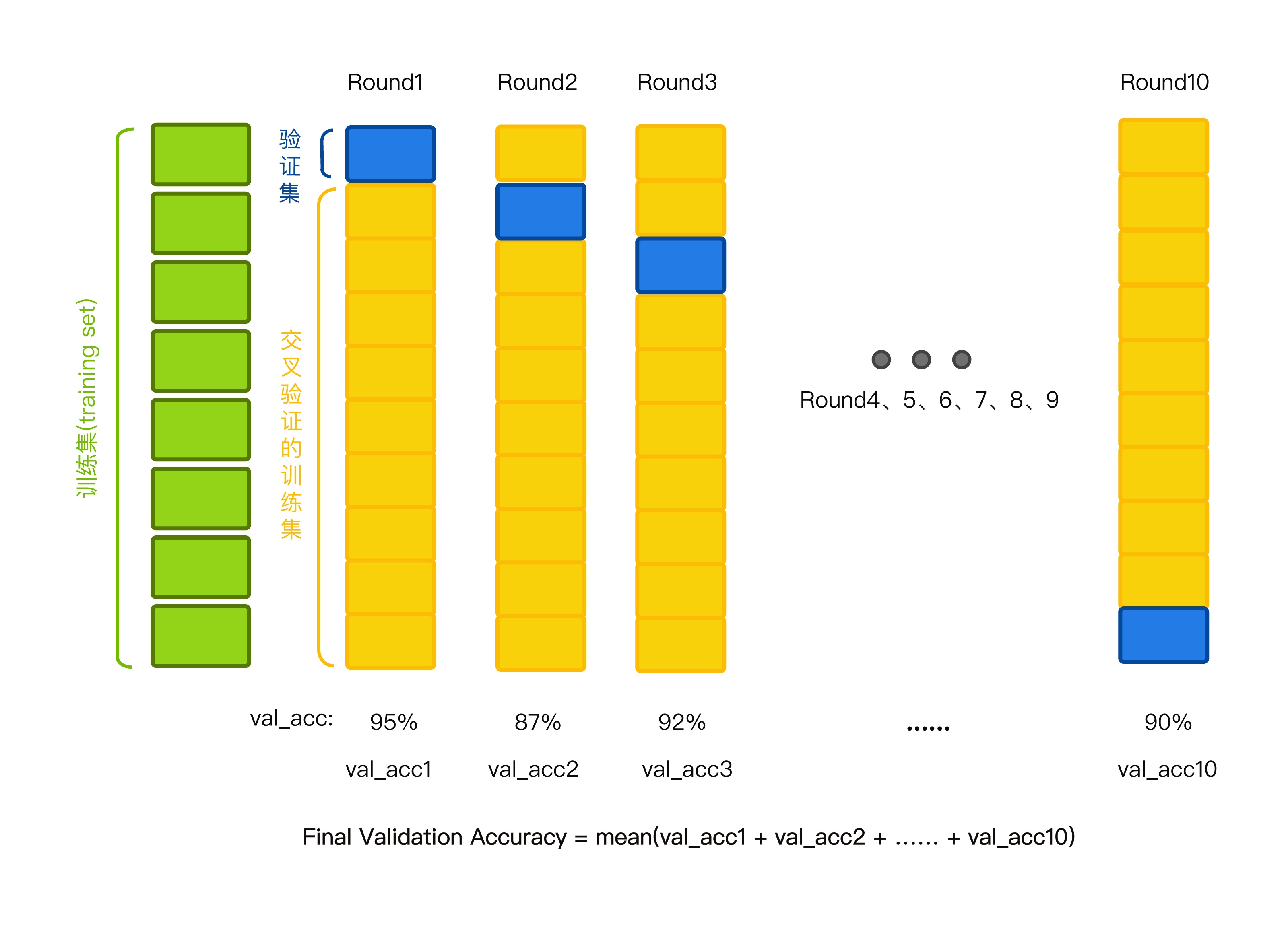
首先将一份数据按照 8:2 划分出训练集和测试集。下图描述的就是K折交叉验证(K=10), 我们又称为十折交叉验证。
2 K折交叉验证工作原理 Cross Validation
注:测试集就像我们说的高考题,是绝对保密不参与训练过程的,用于最后检验(模型)能力好坏的。
-
用第 2-10 份数据作为训练集训练模型,用第 1 份数据作为验证集;
-
用第 1 和 3-10 份数据作为训练集训练模型,用第 2 份数据作为验证集;
-
用第 1-2 和 4-10 份数据作为训练集训练模型,用第 3 份数据作为验证集;
...... -
以此类推,用第 1-9 份数据作为训练集训练模型,用第 10 份数据作为验证集;
10 个验证分数的平均分数是模型的最终验证分数。(记住是验证集的平均分数)
3 网格搜索算法
网格搜索法算法就是通过交叉验证的方法去寻找最优的模型参数。
详细点说就是模型的每个参数有很多个候选值,我们每个参数组合做一次交叉验证,最后得出交叉验证分数最高的,就是我们的最优参数。
4 项目案例: 鸢尾花检测模型更新
- 用网格搜索和k折交叉验证优化逻辑回归
"""
逻辑回归(处理鸢尾花数据集)
"""
import numpy as np
from sklearn import datasets
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
from sklearn.model_selection import GridSearchCV
import matplotlib.pyplot as plt
from time import time
import warnings
warnings.filterwarnings('ignore')
iris = datasets.load_iris()
# 因为花瓣的相关系数比较高,所以分类效果比较好,所以我们就用花瓣宽度当作X
X = iris['data'][:, 3:]
# 把分类结果拿出来
y = iris['target']
# 我们把数据分成训练集和测试集
x_train, x_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
# 交叉验证的准备
param_grid = {"tol": [1e-4, 1e-3, 1e-2],
"C": [0.4, 0.6, 0.8]}
######################
# 用以上的数据做逻辑回归#
######################
log_reg = LogisticRegression(multi_class='ovr', solver='sag')
grid_search = GridSearchCV(log_reg, param_grid=param_grid, cv=3)
grid_search.fit(x_train, y_train)
print(grid_search.score(x_test, y_test))
print(grid_search.best_params_)
# 最高分数
print(grid_search.best_score_)
# 最优模型
print(grid_search.best_estimator_)
# report(grid_search.cv_results_)
####################
# 数据预测 #
####################
# 创建新的数据集去预测 创建0到3的1000个等差数列,(-1,1)就是让他在不知道多少行的情况下,变成1列,
X_new = np.linspace(0, 3, 1000).reshape(-1, 1)
# print(X_new)
# 用来预测分类的概率值,比如第一个行第一个概率最大,那么得到的y=0
y_proba = grid_search.predict_proba(X_new)
# 用来预测分类号的
y_hat = grid_search.predict(X_new)
print(y_proba)
print(y_hat)
参考链接: