本文主要介绍概念与结论,证明的细节与技巧不是本文所关心的
有穷自动机(DFA)

例1.
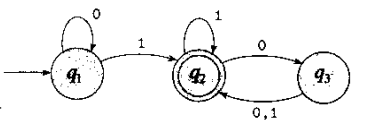
这是一个有三个状态的有穷自动机M1(双圆圈代表接受状态),当它接收到输入串,比如,1101,它会依次读入字符并按照转移函数改变状态,最终如果自动机处于接受状态,则输出为接受,否则输出拒绝。对于这个例子以及输入1101,M1最终处于\(q_2\)因此接受此输入。
语言
语言:设A是机器M所接受的全部字符串集,则称A为机器M的语言,记为\(L(M)=A\),又称M识别A。
正则语言:被一台有穷自动机识别的语言称为正则语言
正则运算:是以下的三种运算

定理1.正则语言类在正则运算下封闭
非确定型有穷自动机(NFA)
之前的讨论中可以看出,计算的每一步都按照唯一的方式跟在前一步的后面,机器在给定状态下读入一个输入字符时,我们总能知道它下一步将会是什么状态,这是确定型机器。然而在非确定型机器中,下一个状态可能存在若干种选择。
例2.
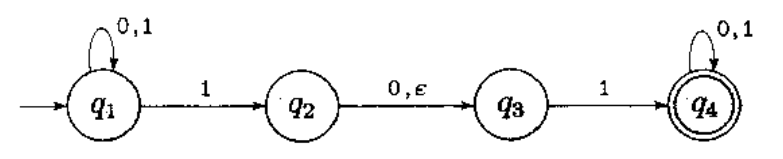
这是一台NFA,其中\(\epsilon\)是不需要读入输入字符就可能产生一个状态的变化。NFA如何进行计算?当NFA读入一个输入符号后,他将自己分裂成多个备份,并行地执行所有可能性,当下个输入符号不存在于该状态的转移函数中(即不在从状态指出的任何箭头上),那么计算机的这个备份和相关联的计算分支一块死掉。如果机器在某一个备份的末端接受了输入,则这台NFA接受输入。当箭头上有\(\epsilon\)则不接受输入,直接分裂成多个备份。
现在可以给出NFA的形式定义

等价:如果两台机器识别的语言相同,则称他们等价。
尽管NFA看起来要比DFA更加强大,但实际上,它们是等价的。
定理2.每一台NFA都与某个DFA等价
正则表达式
如同算术表达式是用来描述四则运算的那样,正则表达式是一种用来描述语言的表达式。
例3.
\((0 \cup 1)*\)代表一个由01字符组成的任意长字符串组成的语言,而\((0 \cup 1)* 0\)则代表所有由0结尾的01串组成的语言。
正则表达式的形式定义如下:

更多例子:

定理3.一个语言是正则的,当且仅当它可以由正则表达式描述
非正则语言
要理解有穷自动机的能力,就要了解它的局限性。实际上\(B=\{0^n 1^n | n>0 \}\)是一个非正则的语言。这是因为有穷自动机只能储存有穷个状态,而B中的n是任意的,有限状态机必须拥有能记住无穷种可能性的能力,才能识别B。这里要给出一种方法,用来对于像B这样的语言,证明它是无法被某个DFA识别的。实际上,上面所说其有n个0需要被DFA记住,这并不足以作为证明依据,因为有一些语言看起来需要无穷的存储来识别,但实际上却不需要用到无穷的存储。考虑\(\sum =\{0,1\}\)上的两个语言\(C=\{\omega | \omega 中的0和1相等 \}\)和\(D=\{\omega| \omega 中01和10子串出现的次数相同\}\)实际上C是非正则的,但D确是正则语言,尽管它看起来需要无穷的存储来对字串数目进行计数。
证明的有力工具是下面的泵引理

泵引理说的是:正则语言中的字符串只要长度不小于某个泵长度,就可以被"抽取",即它包含一个字串,将该字串重复任意多次得到的字符串仍然在这个语言中
例4.我们来用泵引理证明B不是正则语言:
假设B正则,则其满足泵引理,当\(|\omega \in B|>p\)时(p为泵长度),可以将它分为\(\omega = xyz\).若y只包含0,那么y重复后0比1多,当然不会属于B。若y包含0与1,那么重复后01的顺序不再是B所要求的那样0在前1在后了。若y只包含1,同理抽取后的字符串也不在B中。这导出了矛盾。
例5.我们来证明C不是正则语言,此时将会用到泵引理的性质3.
取s为\(0^p1^p\),我们来抽取s=xyz,\(|xy|<p\),那么y一定全由0构成,那么重复后显然不在C中。
上下文无关语言
上下文无关文法产生式地描述一个语言,一个文法由一组替换规则组成,先给出一个上下文无关语法的例子:
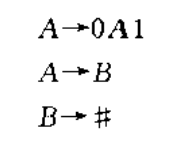
文法由一组替换规则组成,每个规则占一行,规则由一个符号和一个字符串组成,符号和字符串之间用箭头隔开。将这个符号称作变元,常用大写字母表示。而字符串由变元和终结符组成,终结符常用小写字母,数字和符号表示。第一条规则左边的变元叫做起始变元。在上面的例子中,A是起始变元,A,B是变元,0,1,#是终结符。
有了文法,就可以按照下面的规则生成语言中的每一个字符串。
1)写下起始变元
2)取一个写下的变元,找到以这个变元开始的规则,把变元替换成右边的字符串
3)重复2直到没有变元存在为止
例子中的文法生成的语言是\(\{0^n #1^n|n>0\}\)
上下文无关文法的形式定义如下:

乔姆斯基范式
乔姆斯基范式是一种简单而有用的上下文无关文法表达规范

定理4.任意上下文无关语言都可以由乔姆斯基范式的上下文无关文法生成
下推自动机(PDA)
PDA基本上就是在NFA的基础上增加了一个额外的设备称为栈,于是给NFA提供了附加的存储。
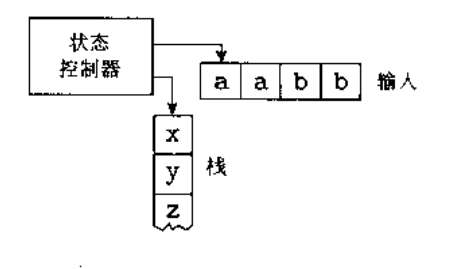
PDA能够把符号写在栈上,并可以读以及删除栈顶的符号,当写入一个符号到栈顶,栈里其它符号都会往下推一格。栈可以保存无穷的信息,这使得它可以比NFA更强大。实际上它与上下文无关文法等价。读者可以想一想PDA如何识别NFA所无法识别的语言B
定理5.一个语言是上下文无关的,当且仅当一个PDA识别它
PDA的形式定义如下

非上下文无关语言
PDA也无法识别所有语言,即非上下文无关语言是存在的。同正则语言一样,上下文无关语言也有一个泵引理,用来证明某些语言不是上下文无关的。
