从对爬虫的介绍出发,引入一个简单爬虫的技术架构,然后通过是什么、怎么做、现场演示三步骤,解释爬虫技术架构中的三个模块。最后,一套优雅精美的爬虫代码实战编写,向大家演示了实战抓取百度百科1000个页面的数据全过程
本文掌握开发轻量级爬虫——爬取不需要登录的静态网页
知识框架:
- 爬虫简介
- 简单爬虫架构:URL管理器,网页下载器(urllib2),网页解析器(BeautifulSoup)
- 完整实例:爬取百度百科Python词条相关的 1000个页面数据
一、爬虫简介
爬虫是一段自动抓取网页信息的程序,自动访问互联网并提取有价值的数据
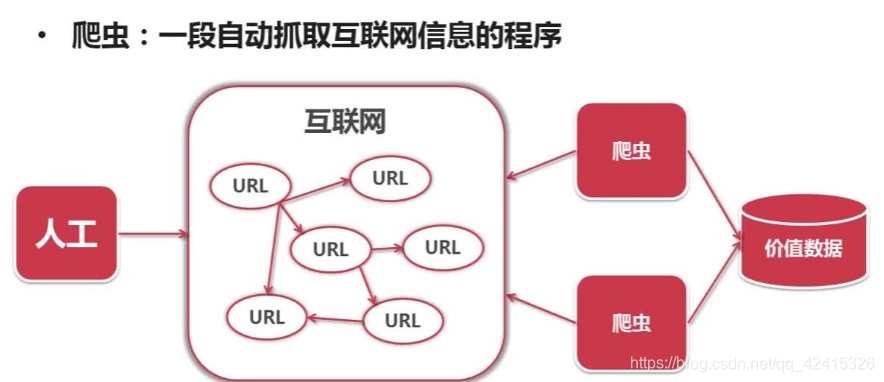
爬虫价值:爬去互联网数据并存储下来后,可以对有价值数据进行更方便的分析、学习、利用,甚至可以基于这些数据制作出相应的产品如APP等。
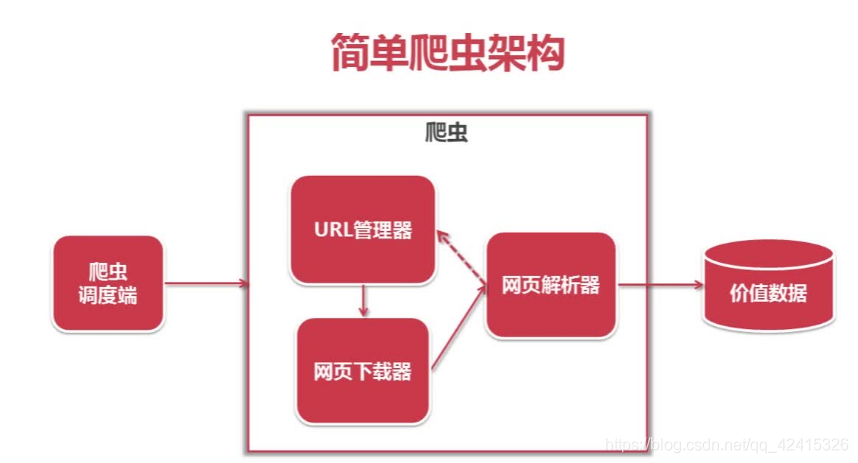
二、简单爬虫架构
首先我们来了解下架构的定义:软件架构是一个系统的草图。软件架构描述的对象是直接构成系统的抽象组件。各个组件之间的连接则明确和相对细致地描述组件之间的通讯。
这里所介绍的架构包括爬虫调度端,URL管理器,网页下载器,网页解析器
爬虫调度端:目的是开启、监控
URL管理器将URL传输给网页下载器,下载器将URL存储成字符串,并将字符串传送给解析器。解析器将有价值的数据保留,并将解析出来的URL传输给URL管理器。
三、URL管理器
URL管理器包括待爬取的URL和已爬取的URL
分成两部分的原因:防止重复抓取和循环抓取,因为一个URL可以指向很多个URL,如果在没有URL管理器时,两个URL互相指向,就会循环抓取网页。
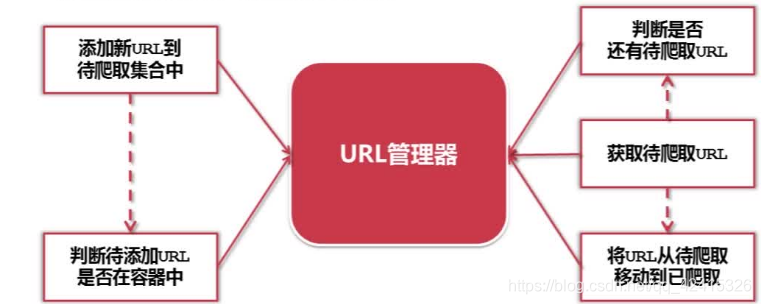
功能如下:
1.添加新的URL到待爬取集合中;
2.判断该URL是否在容器中;
3.获取待爬的URL;
4.是否还有待爬的URL;
5.爬取结束后,将URL从待爬集合转移到已爬集合
Python爬虫URL管理器的实现方式(三种)
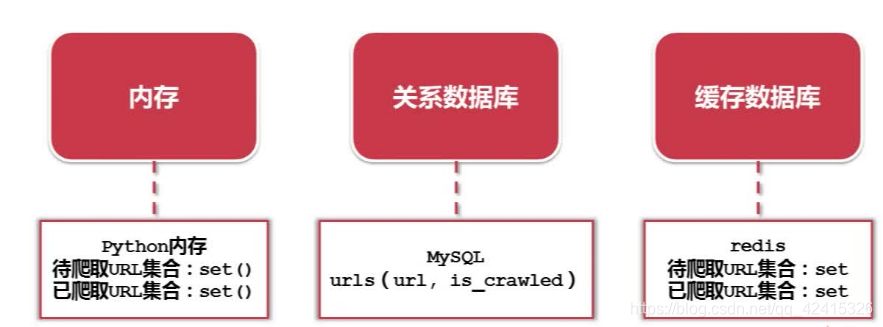
(一)将已爬取或和待爬取的URL集合存放在内存中,用Python语言的话,可以将这两个URL集合放在set()数据结构中,Python的集合(set)结构可以自动去除重复的内容,小型公司或个人使用“内存”
(二)将URL存放在关系数据库中,比如MySQL,建立一个表,有两个字段(url,is_crawled),is_crawled字段标志这个URL的状态是待爬取还是已爬取。内存不够用或想要永久保存使用“关系数据库”
(三)将URL存放在一个缓存数据库中,比如redis,本身支持set的结构,所以我们可以将待爬取的和已爬取的URL存放在set中。,大型公司使用“缓存数据库”
后续本文选用第一中内存方式
四、网页下载器
网页下载器:将互联网上URL对应的网页下载到本地的工具
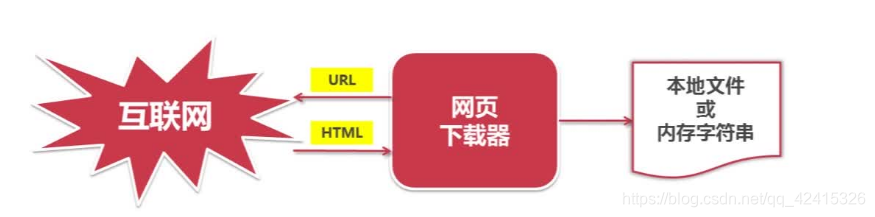
网页下载器类型:
urllib–python官方基础模块
——支持直接的url下载,或者用户输入基础数据
——支持需要登录网页的cookie处理
——支持代理访问的代理处理
补充:post是应用在响应对象中(即要求你下指令之后网页响应的信息),谷歌内可以使用postman进行查看你想要响应的对象内容是什么,post(异步加载的应用):表单的内容记一下和有两个请求头(来源和头)
from urllib.request import Request
from url.requst import urlopen

requests–第三方包(更强大)
本文我们选用官方基础模块urllib2模块作为网络下载器
urllib下载网页方法–1(最简介方法)
实现代码如下:
from urllib import request
from http import cookiejar
url = 'http://www.baidu.com'
print ("第一种方法")
response1 = request.urlopen(url)
resp1 = response1.read()
print(response1.getcode())
print(len(resp1))
#print(resp1)
2.共享处理 添加data(需要用户输入的参数)、http header(向服务器提交http信息)
实现代码如下:
from urllib import request
from http import cookiejar
url = 'http://www.baidu.com'
print("第二种方法")
request2 = request.Request(url)
request2.add_header("user-agent", "Mozilla/5.0")
response2 = request.urlopen(request2)
respl2 = response2.read()
print(response2.getcode())
3.添加特殊情景的处理器:
需要用户登录的需要cookie处理:HTTPCookieProcessor
代理访问:ProxyHandler
HTTPS加密访问:HTTPSHandler
URL相互自动跳转:HTTPRedirectHandler
实现代码如下:
from urllib import request
from http import cookiejar
print("第三种方法")
cj = cookiejar.CookieJar()
opener = request.build_opener(request.HTTPCookieProcessor(cj))
request.install_opener(opener)
response3 = request.urlopen(url)
print(response3.getcode())
print(cj)
print(response3.read())
五、网页解释器
网页解析器:从下载的网页中提取有价值的数据的工具
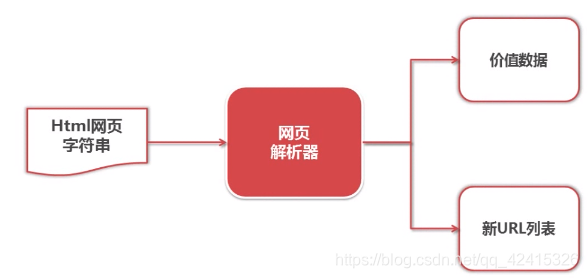
网页解析器类型:
- 使用字符串的模糊匹配(正则表达式),不适用于复杂的
- Python自带模块——html.parser
- BeautifulSoup,它既可以使用Python自带的网页解析器parser,也可以使用lxml; 功能比较强大。
- lxml为第三方插件

后三种采用的是结构化解析
结构化解析:(将一个文档看成一个对象,整个文档内容看成一棵DOM树来进行解析)
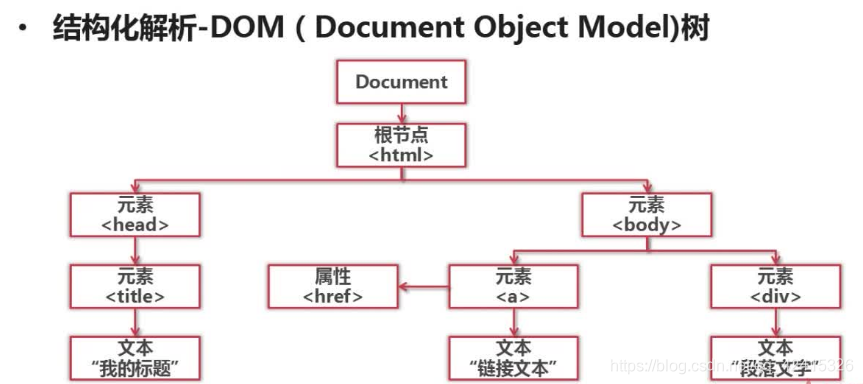
本文我们使用BeautifulSoup这一模块。
BeautifulSoup:Python第三方库,用于从HTML或XML中提取数据
官网:http://www.crummy.com/software/BeautifulSoup
安装:在已有pip的情况下在cmd中运行pip install beautifulsoup4
导入:import bs4
实际流程和方法:
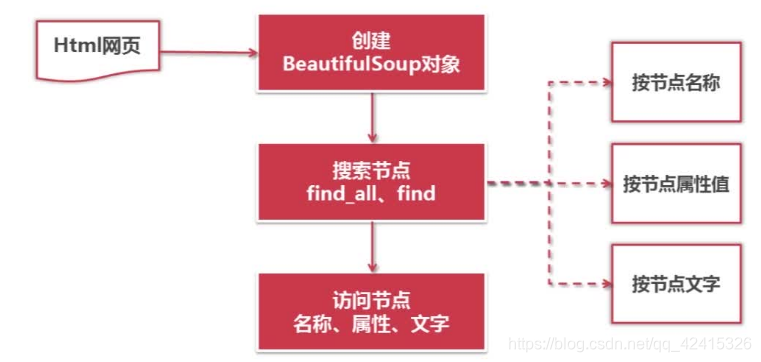
——根据下载好的HTML网页字符串可创建一个BeautifulSoup对象,创建这个DOM对象的同时就会将整个文档字符串下载成一个DOM数
——根据这个DOM数我们就可进行各种节点的搜索;搜索节点时,可按照节点名称或节点属性或节点文字进行搜索
——(find_add()方法:会搜索出所有满足要求的节点;find()方法:只会搜索出第1个满足要求的节点;这两个参数是一模一样的,这两个方法都支持正则)
——得到一个节点以后,我们就可以访问节点的名称,属性,文字
代码如下:
1. 导入模块
# -*- coding: utf-8 -*-
from bs4 import BeautifulSoup #导入网页解析器BeautifulSoup库
import re #导入正则表达式库
2.测试文本
html_doc = """
<html><head><title>The Dormouse's story</title></head>
<body>
<p class="title"><b>The Dormouse's story</b></p>
<p class="story">Once upon a time there were three little sisters; and their names were
<a href="http://example.com/elsie" class="sister" id="link1">Elsie</a>,
<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and
<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p>
<p class="story">...</p>
"""
- 创建BeautifulSoup对象
soup = BeautifulSoup(html_doc, # HTML文档字符串
'html.parser', # HTML解析器
from_encoding='utf-8' # HTML文档的编码
)
- 搜索节点(find_all,或者find)
print ('获取所有的链接')
links = soup.find_all('a')
for link in links:
print (link.name, link['href'], link.get_text()) # 访问节点内容
print ('获取Lacie的链接')
link_node = soup.find('a', href='http://example.com/lacie')
print (link_node.name, link_node['href'], link_node.get_text())
print ('正则匹配')
link_node = soup.find('a', href=re.compile(r"ill"))
print (link_node.name, link_node['href'], link_node.get_text())
print ('获取p段落文字')
link_node = soup.find('p', class_="title")
print (link_node.name, link_node.get_text())
六 、爬虫实例
轻量级爬虫实例——爬取百度百科1000个页面的数据
这里只分析爬虫架构,爬取百度百科1000个页面的数据源代码请点击查看
爬虫流程:确定目标—>分析目标—>编写代码—>执行爬虫
分析目标:URL格式,数据格式,网页编码
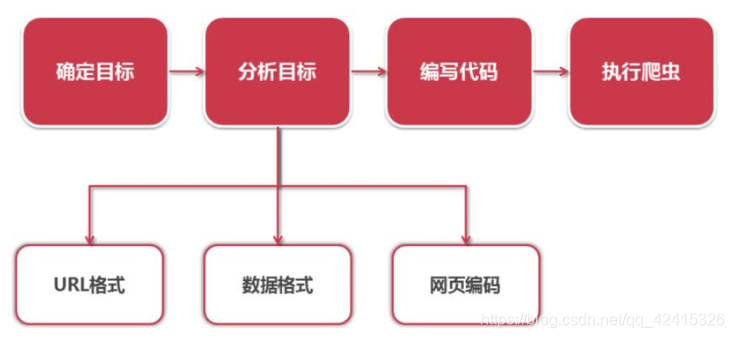
分析目标结果如下:
目标:百度百科Python词条相关词条网页———标题和简介
入口页:https://baike.baidu.com/item/Python/407313
URL格式:
——相关词条页面URL:/item/***/***
数据格式:
——标题:< dd class=“lemmaWgt-lemmaTitle-title”>< h1>***</ h1></ dd>
——简介:< div class=“para” label-module=“para”> ***</ div>
页面编码:UTF—8