一、ResNet
Deep Residual Learning for Image Recognition(深度残差学习在图像识别中的应用)
- 论文链接:https://arxiv.org/abs/1512.03385
- 论文代码:
1、https://github.com/KaimingHe/deep-residual-networks
2、https://github.com/tensorflow/models/blob/master/research/slim/nets/resnet_v1.py (tf)
二、详解
1、网络结构


在计算机视觉里,特征的“等级”随增网络深度的加深而变高,研究表明,网络的深度是实现好的效果的重要因素。然而梯度弥散/爆炸成为训练深层次的网络的障碍,导致无法收敛。
有一些方法可以弥补,如标准化初始化和中间各层归一化,使得可以收敛的网络的深度提升为原来的十倍。然而,虽然收敛了,但网络却开始退化了,即增加网络层数却导致更大的误差。
2、Shortcut connection(快捷连接)&&残差块

- 它有二层,如下表达式,其中σ代表非线性函数ReLU:
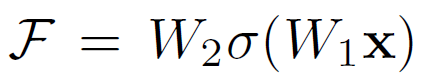
- 然后通过一个shortcut,和第2个ReLU,获得输出y:
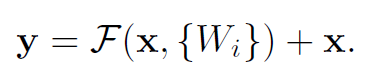
- 当需要对输入和输出维数进行变化时(如改变通道数目),可以在shortcut时对x做一个线性变换Ws,如下式,然而实验证明x已经足够了,不需要再搞个维度变换,除非需求是某个特定维度的输出,如文章开头的resnet网络结构图中的虚线,是将通道数翻倍。
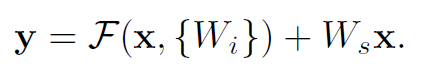
注: 实验证明,这个残差块往往需要两层以上,单单一层的残差块(y=W1x+x)并不能起到提升作用。
但是,ResNet模块并不是这么单一,文章中就提出了两种方式:

这两种结构分别针对ResNet34(左图)和ResNet50/101/152(右图),一般称整个结构为一个”building block“。其中右图又称为”bottleneck design”,目的一目了然,就是为了降低参数的数目,第一个1x1的卷积把256维channel降到64维,然后在最后通过1x1卷积恢复,整体上用的参数数目:1x1x256x64 + 3x3x64x64 + 1x1x64x256 = 69632,而不使用bottleneck的话就是两个3x3x256的卷积,参数数目: 3x3x256x256x2 = 1179648,差了16.94倍。
对于常规ResNet,可以用于34层或者更少的网络中,对于Bottleneck Design的ResNet通常用于更深的如101这样的网络中,目的是减少计算和参数量(实用目的)。
3、基于ResNet101的Faster RCNN

整个Faster RCNN的架构,其中蓝色的部分为ResNet101,可以发现conv4_x的最后的输出为RPN和RoI Pooling共享的部分,而conv5_x(共9层网络)都作用于RoI Pooling之后的一堆特征图(14 x 14 x 1024),特征图的大小维度也刚好符合原本的ResNet101中conv5_x的输入;
最后大家一定要记得最后要接一个average pooling,得到2048维特征,分别用于分类和框回归。