模型太简单时,会在训练集上拟合不足,就是说模型的复杂程度不足以描述训练集的全部特征,当模型在训练集上表现不好时,你不能期待它在新的数据集上表现更好。但是在训练集上对于太多的细节和噪声都拟合起来,就会导致模型过度复杂,这样复杂的模型对特征的变化和噪声都很敏感,这就导致模型在新数据集上的泛化能力不足。
另一方面,我们可以通过学习曲线来观察模型性能。它是模型“关于数据大小”的性能函数。通过不断地增加训练集和验证集的大小来观察模型在训练集和验证集上的误差,如下图:
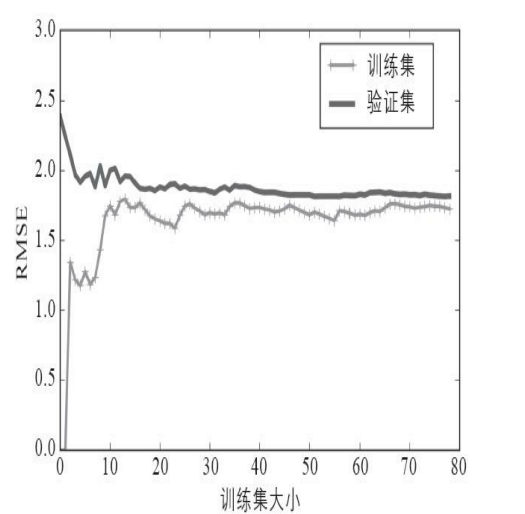
这里有一些值得注意的地方:1. 开始时只有一个实例,因此模型在训练集上完美拟合,误差为0,随着训练数据的增加,模型的对数据集的拟合能力下降,最后达到一个高值,即使增加训练数据误差也不会无限增加,因为已有的数据已经包含了足够多的特征间的关系,也就是说实例的增加不再使得训练集的复杂度增加。
2. 相反的,开始时模型在验证集上表现最糟糕,因为只经过一个实例训练的模型几乎没什么用,因此误差很高,随着训练集的增加,模型的拟合能力越来越好,因此在验证集上的表现也越来越好。最后两条曲线会比较接近,这是正确的现象。
如果模型只是对新数据的拟合能力不足,但是如果模型对训练集拟合不足,那么更多的数据也于事无补,这时应当考虑更复杂的模型,或者更好的特征。如果模型对训练集过拟合,应当增加训练数据,直到模型在训练集和验证集上的误差相当。
方差/偏差权衡
模型的泛化误差可以表示为三种截然不同的误差之和
1. 偏差 其存在是由于错误的假设,比如用线性模型去拟合二次数据模型。高偏差模型通常对训练集拟合不足。注意区分偏差和偏置项,两者是不同的概念;
2. 方差 来源于复杂模型(高自由度,比如高阶多项式)对训练数据的微小变化过于敏感,高偏差的模型往往对训练集过度拟合;
3. 不可避免的误差 比如系统测量误差,传输过程损坏的数据等等,这时能做的就是清理数据。