这里爬取的都是静态的数据,也没有设计到跨页爬取,也没有用到正则表达式,这就是一个简单的爬取
第一份
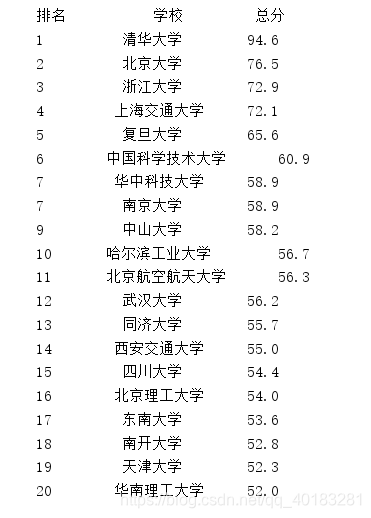
爬取最好大学网的排名
# coding=gbk
import requests
from bs4 import BeautifulSoup
import bs4
def getHtmlText(url):
try:
r = requests.get(url)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except:
return ""
def fillList(ulist,html):
soup=BeautifulSoup(html,'html.parser')
for tr in soup.find('tbody').children:
if isinstance(tr,bs4.element.Tag):
tds=tr('td')
ulist.append([tds[0].string,tds[1].string,tds[3].string])
def printList(ulist,num):
print("{:^10}\t{:^8}\t{:^10}".format("排名", "学校", "总分"))
for i in range(num):
u=ulist[i]
print("{:^10}\t{:^10}\t{:^10}".format(u[0], u[1], u[2]))
#print("{:^10}\t{:^6}\t{:^10}".format(u[0],u[1],u[3]))# 按照顺序跑
def main():
info=[]
url="http://www.zuihaodaxue.com/zuihaodaxuepaiming2019.html"
html=getHtmlText(url)
fillList(info,html)
printList(info,20)
main()
看看源码观察如何提取

这里的排版有些问题,又兴趣的可以改一改,嘿嘿
第二份
电影的排名与评分
# coding=gbk
import requests
from bs4 import BeautifulSoup
import bs4
def getHtmlText(url):
try:
r = requests.get(url)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except:
return ""
def fillprintList(html):
soup=BeautifulSoup(html,'html.parser')
for dd in soup.find('dl', class_='board-wrapper').children:
#对dl标签的内容做一个循环遍历
if isinstance(dd,bs4.element.Tag):
#判断选取循环出来的dd标签中的内容
top=dd.find('i',class_='integer').string
#最重要的还是要用到的标签的选择
top1 = dd.find('i', class_='fraction').string
time=dd.find('p',class_='releasetime').string
dds=dd.find('a').get('title')
num=dd.find('i',class_='board-index').string
print("排名",num, '\n', "电影",dds, '\n', "评分",top,top1, '\n',time)
def main():
url="https://maoyan.com/board"
html=getHtmlText(url)
fillprintList(html)
main()

首先先看看html的架构,然后根据html的标签节点来选取要爬取的内容
