版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/qq_39424143/article/details/89334158
Oracle复(五)
序列 索引
序列:
- 序列:按照一定的规则自动增减数字的一种数据库对象。
* 创建序列
create sequences 序列名
[increment by n] 每次加n
[start with n ] 从n开始
[maxvalue n] 最大值
[minvalue n] 最小值
[cycle || nocycle] 表示到最大值之后是否继续生产序列
* 使用序列:
* NEXTVAL:
序列返回的下一个值
SELECT sequence_name.NEXTVAL FROM DUAL
* CURRVAL:
序列返回的当前值
SELECT sequence_name.CURRVAL FROM DUAL
eg:
create sequence test
start with 10 increment by 1;
insert into stu values(stu.nextval,'Tom')
select * from stu;
* 修改序列:
ALTER SEQUENCE sequence_name
[INCREMENT BY n]
[{MAXVALUE n| NOMAXVALUE}]
[{MINVALUE n| NOMINVALUE}]
[{CYCLE | NOCYCLE}]
* cache 10 :
缓存中序列值的个数为10
* 删除序列:
drop sequence 序列名;
- 伪列rowid:
伪列
系统自动生成的表示每一个数据库记录的物理地址唯一的
好处:可以快速定位到记录上
组成: 数据对象编号6位 + 相关文件编号3位 + 块编号6位 + 行编号3位
索引
- 索引是一种数据结构,可以通过该结构迅速地 访问表中的数据
* 分类:
* 单列索引 :一个列上
* 复合索引:多个列上
* 创建索引:
* 自动创建
建表的时候使用了 primary key 或者 unique 数据可自己创建索引
* 手动创建:
CREATE INDEX index_name ON table_name(column_name)
CREATE UNIQUE INDEX index_name ON table_name(column_name)
* 命名规范:
* idx_表名_列名
实例:
单列索引
create index idx_emp_ename on emp(ename)
复合索引:
create index idx_emp_ename on emp(ename,job)
* 删除索引:
drop index 索引名
-
B+树索引
- B+树索引就是通常使用的“传统”索引,是数 据库中最常使用的一类索引结构。其实现与二 叉查找树很相似。
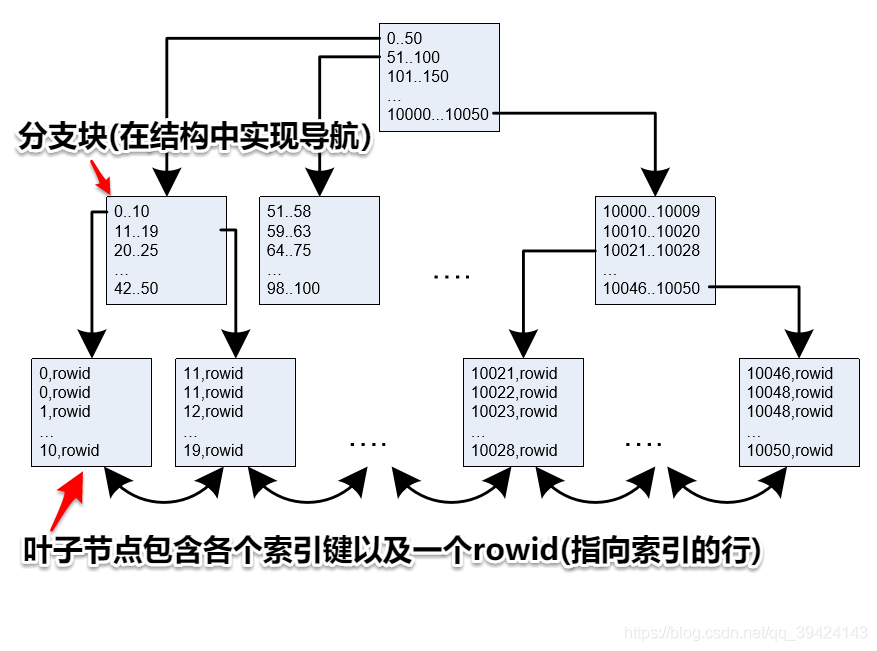
* B+树的特点之一是:所有叶子块都应该在树的同一层 上。这一层称为索引的高度(height)换句话说,索引是高度平衡的
* B+ 树索引中不存在非惟一性条目。在一个非惟一性索引中,Oracle 会把 rowid 作为一个额外的列追加到键上,使得键惟一
- 添加索引的作用:
* 优点:
执行速率会加快
* 缺点:
占用空间
降低DML操作的效率