其他面试题类型汇总:
Java校招极大几率出的面试题(含答案)----汇总
几率大的网络安全面试题(含答案)
几率大的多线程面试题(含答案)
几率大的源码底层原理,杂食面试题(含答案)
几率大的Redis面试题(含答案)
几率大的linux命令面试题(含答案)
几率大的杂乱+操作系统面试题(含答案)
几率大的SSM框架面试题(含答案)
几率大的数据库(MySQL)面试题(含答案)
几率大的JVM面试题(含答案)
几率大的现场手撕算法面试题(含答案)
临时抱佛脚必备系列(含答案)
本文的面试题如下:
Bean的生命周期
手写常用的几个单例模式(懒汉模式和饿汉模式,线程安全等)
各种排序的时间复杂度,堆排序和快排
简单工厂模式、抽象工厂模式、工厂方法模式的区别。
泛型的T,E,?和空的区别
秒杀系统如何设计?高并发下会出现什么问题?
分页和分段有什么区别(内存管理)
操作系统中进程调度策略有哪几种?
虚拟内存是什么
页面置换算法
面向对象的特征
解决 java 集群的 session 共享的解决方案
了解元注解吗?
LinkedList是双向链表还是单向?,他有个get方法,时间复杂度是多少
深拷贝和浅拷贝是什么?有什么区别
String底层原理,StringBuilder和StringBuffer的区别?使用场景
java集合类的初始容量大小和扩容大小
Bean的生命周期
- 创建阶段(Created): 分配存储空间,构造对象,初始化
- 应用阶段(In Use): 对象至少被一个强引用持有着。
- 不可见阶段(Invisible): 该对象不再被任何强引用所持有。
- 不可达阶段(Unreachable):
- 收集阶段(Collected): 如果该对象已经重写了finalize()方法,则会去执行该方法的终端操作。
- 终结阶段(Finalized): 等待垃圾回收器对该对象空间进行回收。
- 对象空间重分配阶段(De-allocated): 所占用的内存空间进行回收或者再分配了
手写常用的几个单例模式(懒汉模式和饿汉模式,线程安全等)
构造方法定义为私有方法
提供一个静态方法,
饿汉式(静态常量):在类装载的时候就完成实例化。避免了线程同步问题
public class Singleton {
private final static Singleton INSTANCE = new Singleton();final修饰的静态实例
private Singleton(){} 私有化构造器
public static Singleton getInstance(){ 提供一个静态的方法返回实例
return INSTANCE;
}
}
饿汉式(静态代码块)
public class Singleton {
private static Singleton instance;
static {
instance = new Singleton();
}
private Singleton() {}
public static Singleton getInstance() {
return instance;
}
}
双重检查: 优点:线程安全;延迟加载;效率较高。
public class Singleton {
private static volatile Singleton singleton; volatile类型的
private Singleton() {}
public static Singleton getInstance() {
if (singleton == null) {
synchronized (Singleton.class) {
if (singleton == null) {
singleton = new Singleton();
}
}
}
return singleton;
}
}
静态内部类: JVM帮助我们保证了线程的安全性
public class Singleton {
private Singleton() {}
private static class SingletonInstance {
private static final Singleton INSTANCE = new Singleton();
}
public static Singleton getInstance() {
return SingletonInstance.INSTANCE;
}
}
枚举[推荐用]: 避免多线程同步问题, 还能防止反序列化重新创建新的对象。
public enum Singleton {
INSTANCE;
public void whateverMethod() {
}
}
各种排序的时间复杂度,堆排序和快排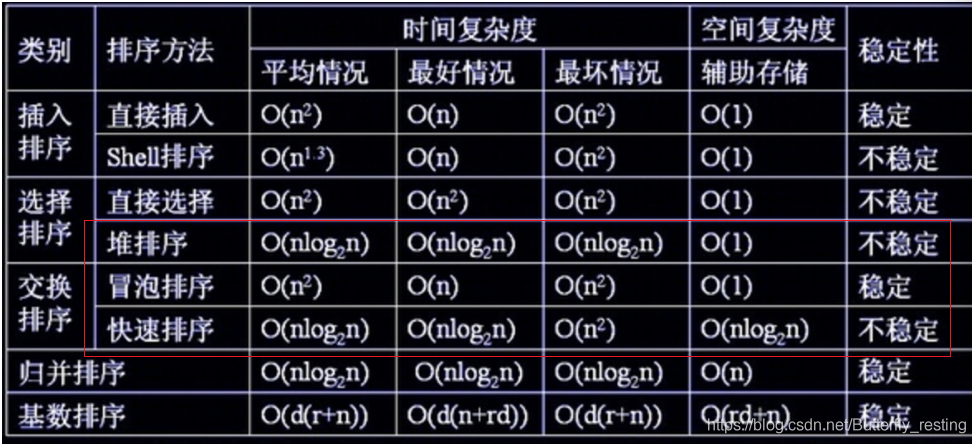
堆排序和快排的实现思路
完全二叉树即是:若设二叉树的深度为h,除第 h 层外,其它各层 (1~h-1) 的结点数都达到最大个数,第 h 层所有的结点都连续集中在最左边,这就是完全二叉树。
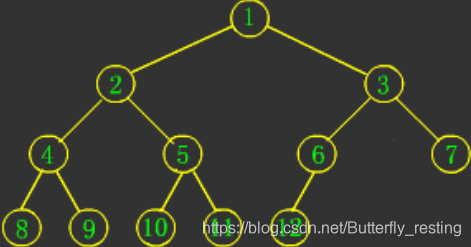
堆是一个完全二叉树。堆满足两个性质: 堆的每一个父节点数值都大于(或小于)其子节点,堆的每个左子树和右子树也是一个堆。
堆分为最小堆和最大堆。最大堆就是每个父节点的数值要大于孩子节点,最小堆就是每个父节点的数值要小于孩子节点。排序要求从小到大的话,我们需要建立最大堆,反之建立最小堆
平衡二叉树: 它是一 棵空树或它的左右两个子树的高度差的绝对值不超过1,并且左右两个子树都是一棵平衡二叉树。
满二叉树: 除了叶结点外每一个结点都有左右子叶且叶子结点都处在最底层的二叉树。( 满二叉树一定是完全二叉树,完全二叉树不一定是满二叉树。)
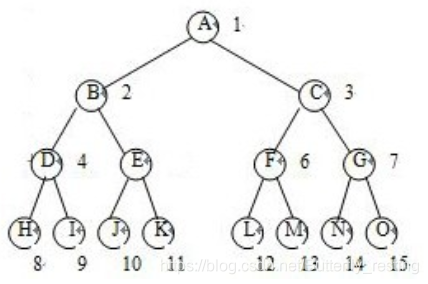
二叉搜索树: 它或者是一棵空树,或者是具有下列性质的二叉树: 若它的左子树不空,则左子树上所有结点的值均小于它的根结点的值; 若它的右子树不空,则右子树上所有结点的值均大于它的根结点的值; 它的左、右子树也分别为二叉排序树。 搜索,插入,删除的复杂度等于树高,O(log(n)).
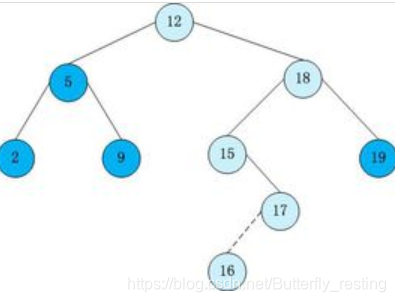
红黑树: 是一种自平衡二叉搜索树, 都是在进行插入和删除操作时通过特定操作保持二叉查找树的平衡,从而获得较高的查找性能。
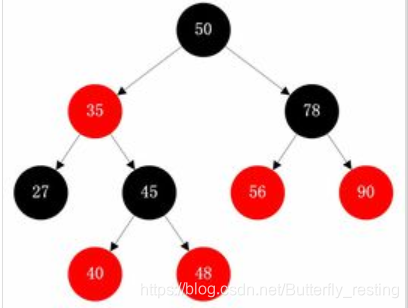
B树: 概括来说是一个节点可以拥有多于2个子节点的二叉查找树。
B+树: 是对B树的一种变形树,它与B树的差异在于所有的叶子结点和相连的节点使用链表相连,便于区间查找和遍历。
哈弗曼树: 给定n个权值作为n个叶子结点,构造一棵二叉树,若该树的带权路径长度达到最小,称这样的二叉树为最优二叉树。 哈夫曼树是带权路径长度最短的树,权值较大的结点离根较近。
简单工厂模式、抽象工厂模式、工厂方法模式的区别。
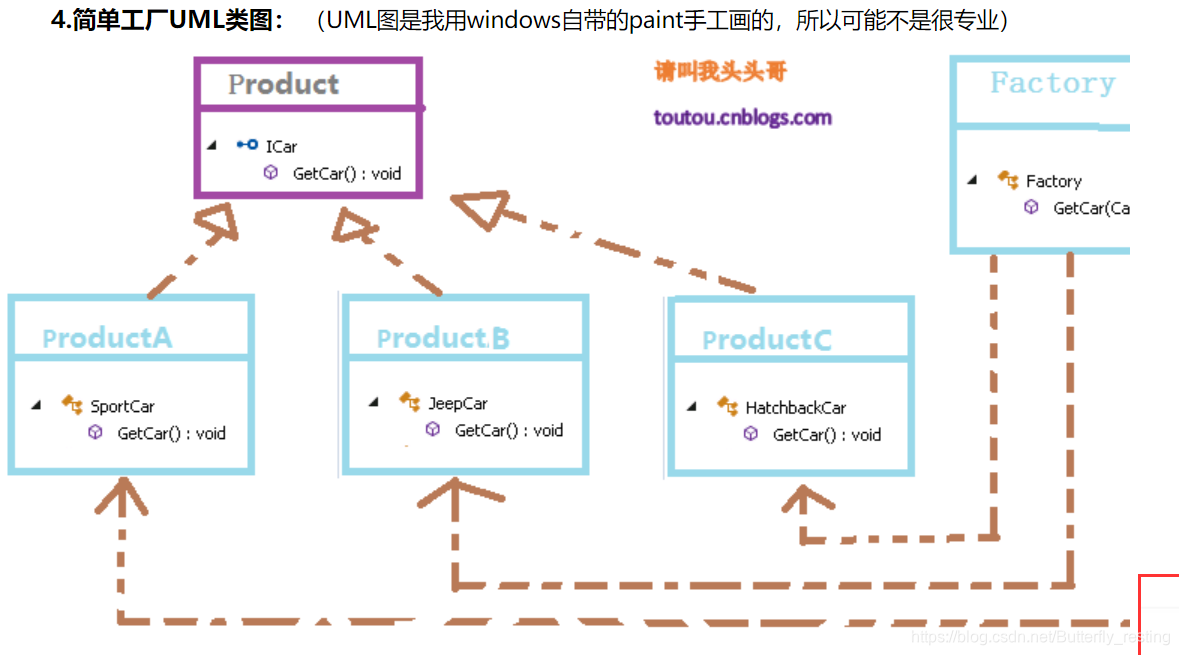
简单工厂模式, 又叫做静态工厂方法,是由一个工厂对象决定创建出哪一种产品类的实例。
*
缺点:很明显工厂类集中了所有实例的创建逻辑,容易违反GRASPR的高内聚的责任分配原则
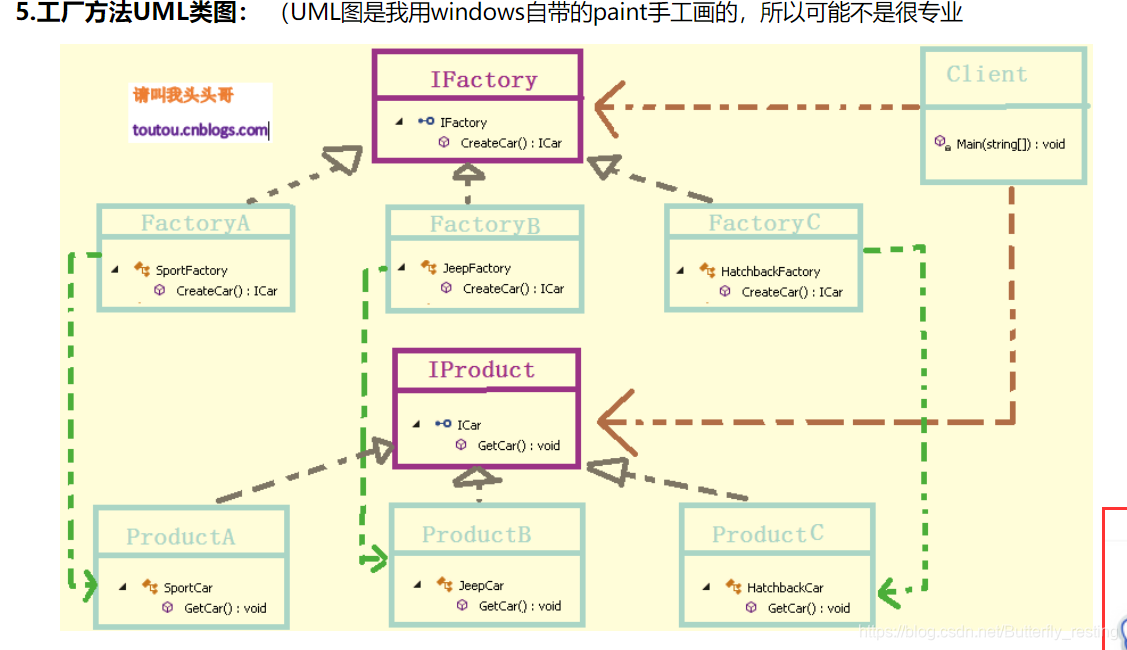
工厂方法模式:核心的工厂类不再负责所有的产品的创建,而是将具体创建的工作交给子类去做。该核心类成为一个抽象工厂角色,仅负责给出具体工厂子类必须实现的接口。
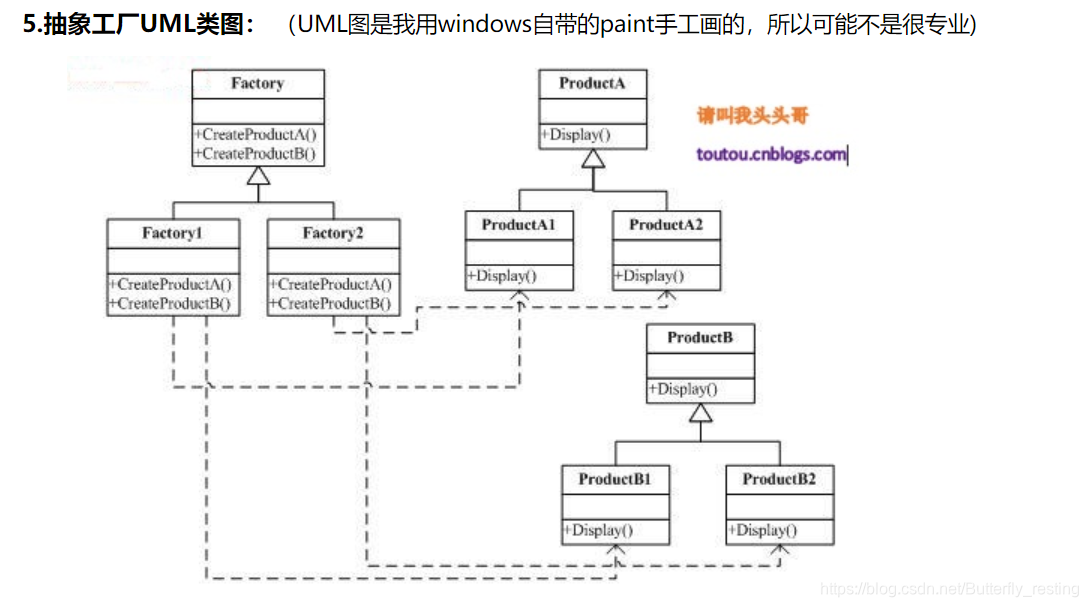
抽象工厂模式: 为创建一组相关或相互依赖的对象提供一个接口,而且无需指定他们的具体类
泛型的T,E,?和空的区别
泛型的好处就是:省去了强制转换,可以在编译时候检查类型安全,可以用在类,方法,接口上。
使用大写字母A,B,C,D…X,Y,Z定义的,就都是泛型,把T换成A也一样,这里T只是名字上的意义而已
? 表示不确定的java类型
T (type) 表示具体的一个java类型
K V (key value) 分别代表java键值中的Key Value
E (element) 代表Element

泛型的限定:
? extends E:接收E类型或者E的子类型。
? super E:接收E类型或者E的父类型
1)E,T,K,V等表示固定泛型类型参数需要声明,而通配符?不需要定义可以直接使用,表示泛型的类型参数。
秒杀系统如何设计?高并发下会出现什么问题?
架构设计:
1)将请求拦截在系统上游,降低下游压力:秒杀系统特点是并发量极大,但实际秒杀成功的请求数量却很少,所以如果不在前端拦截很可能造成数据库读写锁冲突,甚至导致死锁,最终请求超时。
2)充分利用缓存(redis):利用缓存可极大提高系统读写速度。
3)消息中间件(ActiveMQ、Kafka等):消息队列可以削峰,将拦截大量并发请求,这也是一个异步处理过程
(消息队列作用:解耦 削峰 异步操作)
前端设计方案:
页面静态化:将活动页面上的所有可以静态的元素全部静态化
禁止重复提交:用户提交之后按钮置灰,禁止重复提交
用户限流:在某一时间段内只允许用户提交一次请求,比如可以采取IP限流
后端设计方案:
网关层:
限制uid(UserID)访问频率: 针对某些恶意攻击或其它插件,在服务端控制层需要针对同一个访问uid,限制访问频率。
服务层:
采用消息队列缓存请求:先把这些请求都写到消息队列缓存一下
利用缓存应对读请求:对典型的读多写少业务,大部分请求是查询请求。 利用缓存分担数据库压力。
操作系统中进程调度策略有哪几种?
FCFS(先来先服务,队列实现,非抢占的)
SJF(最短作业优先调度算法)
优先级调度算法(可以是抢占的,也可以是非抢占的)
时间片轮转调度算法(可抢占的)
多级队列调度算法
多级反馈队列调度算法。
虚拟内存是什么
虚拟内存的基本思想是:每个进程拥有独立的地址空间,这个空间被分为大小相等的多个块,称为页(Page),每个页都是一段连续的地址。这些页被映射到物理内存,但并不是所有的页都必须在内存中才能运行程序。页面置换算法。
页面置换算法
FIFO先进先出算法LRU(Least recently use)
最近最少使用算法LFU(Least frequently use)
最少使用次数算法OPT(Optimal replacement)
最优置换算法
面向对象的特征
1)抽象:抽象是将一类对象的共同特征总结出来构造类的过程
2)继承:继承是从已有类得到继承信息创建新类的过程。
3)封装:通常认为封装是把数据和操作数据的方法绑定起来,对数据的访问只能通过已定义的接口。
解决 java 集群的 session 共享的解决方案
1.客户端 cookie 加密。
2.集群中,各个应用服务器提供了 session 复制的功能
3.session 的持久化,使用数据库来保存 session。
4.使用共享存储来保存 session。
5.使用 memcached 来保存 session
了解元注解吗?
元注解是指注解的注解,包括
@Retention 注解的保留策略(如仅存在于源码)
@Target 注解的作用目标
@Document 注解包含在javadoc中
@Inherited四种。注解可以被继承
LinkedList是双向链表还是单向?,他有个get方法,时间复杂度是多少
双向链表 O(n)
get(int index):返回此列表中指定位置处的元素。
public E get(int index) {
checkElementIndex(index);
return node(index).item;
}
private void checkElementIndex(int index) {
if (!isElementIndex(index))
throw new IndexOutOfBoundsException(outOfBoundsMsg(index));
}
先将index与长度size的一半比较,如果index<size/2,就只从位置0往后遍历到位置index处,而如果index>size/2,就只从位置size往前遍历到位置index处。这样可以减少一部分不必要的遍历
Node<E> node(int index) {
// assert isElementIndex(index);
if (index < (size >> 1)) {
Node<E> x = first;
for (int i = 0; i < index; i++)
x = x.next;
return x;
} else {
Node<E> x = last;
for (int i = size - 1; i > index; i--)
x = x.prev;
return x;
}
}
深拷贝和浅拷贝是什么?有什么区别
https://www.2cto.com/kf/201401/273852.html
实现对象拷贝的类,必须实现Cloneable接口,并覆写clone()方法
创建一个指向对象的引用变量的拷贝,地址值是相同的,那么它们肯定是同一个对象, 这就叫做引用拷贝。
创建了新的对象, 而不是把原对象的地址赋给了一个新的引用变量,这就叫做对象拷贝
深拷贝和浅拷贝都是对象拷贝
浅拷贝
被复制对象的所有变量都含有与原来的对象相同的值,而所有的对其他对象的引用仍然指向原来的对象。即对象的浅拷贝会对“主”对象进行拷贝,但不会复制主对象里面的对象。 简而言之,浅拷贝仅仅复制所考虑的对象,而不复制它所引用的对象。
深拷贝
深拷贝是一个整个独立的对象拷贝,深拷贝会拷贝所有的属性,并拷贝属性指向的动态分配的内存。当对象和它所引用的对象一起拷贝时即发生深拷贝。深拷贝相比于浅拷贝速度较慢并且花销较大。 简而言之,深拷贝把要复制的对象所引用的对象都复制了一遍。
1) 利用序列化实现深拷贝
2) 重写clone()方法将引用对象改为深复制
3) 彻底深拷贝,几乎是不可能实现的
String底层原理,StringBuilder和StringBuffer的区别?
使用场景
1)String类是final类,也即意味着String类不能被继承,并且它的成员方法都默认为private final方法,没有提供对应的SetXXX方法,所以String是不可变类。 底层是通过char数组来保存字符串的,至于提供的修改String字符串的方法,比如sub操、concat还是replace操作都不是在原有的字符串上进行的,而是重新生成了一个新的字符串对象。也就是说进行这些操作后,最原始的字符串并没有被改变。
特别的:
1)String str1 = “hello world”;String str3 = “hello
world”;System.out.println(str1==str3);//true运行期间字面常量"hello world"被存储在运行时常量池(当然只保存了一份)先在运行时常量池查找是否存在相同的字面常量,如果存在,则直接将引用指向已经存在的字面常量;否则在运行时常量池开辟一个空间来存储该字面常量,并将引用指向该字面常量。
2)通过new关键字来生成对象是在堆区进行的,创建出的一定是不同的对象,即使字符串的内容是相同的
3)对于String拼接,如string += “hello”,会new出一个StringBuilder对象,然后进行append操作,最后通过toString方法返回String对象。
4)StringBuilder和StringBuffer的区别?
a)拥有的成员属性以及成员方法基本相同,区别是StringBuffer是线程安全的
b)执行效率:StringBuilder > StringBuffer > String,特殊情况:String str = “hello”+ "world"的效率就比 StringBuilder st = new StringBuilder().append(“hello”).append(“world”)要高。
使用场景:
当字符串相加操作或者改动较少的情况下,建议使用 String str="hello"这种形式;
当字符串相加操作较多的情况下,建议使用StringBuilder,如果采用了多线程,则使用StringBuffer
java集合类的初始容量大小和扩容大小
ArrayList默认初始容量为10, 按原数组长度的1.5倍扩容
Vector默认初始容量为10, 按原数组长度的2倍扩容
Stack默认容量是10 按原数组长度的2倍扩容
CopyOnWriteArrayList默认容量是0,从0开始 扩容机制,每次+1
LinkedList是用双链表实现的。对容量没有要求,也不需要扩容
HashMap默认容量是16 扩容到原数组的两倍
ConcurrentHashMap,同上。Hashtable默认容量是11, 扩容到原数组的两倍+1
TreeMap由红黑树实现,容量方面没有限制