版权声明:本文为博主原创文章,如需转载,请注明出处: https://blog.csdn.net/MASILEJFOAISEGJIAE/article/details/89317964
温馨提示:运行前,要先开启Hadoop和YARN:./start-all.sh
运行SparkPi程序(Client模式)
进入spark目录,执行SparkPi程序(Client模式)
/home/hadoop/app/spark-2.1.0-bin-2.6.0-cdh5.7.0/bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master yarn \
--executor-memory 1G \
--num-executors 1 \
--num-executors 1 \
/home/hadoop/app/spark-2.1.0-bin-2.6.0-cdh5.7.0/examples/jars/spark-examples_2.11-2.1.0.jar \
4
结果报错:
Exception in thread "main" java.lang.Exception: When running with master 'yarn' either HADOOP_CONF_DIR or YARN_CONF_DIR must be set in the environment.
错误原因:如果想运行在YARN之上,就必须要设置HADOOP_CONF_DIR 或者是YARN_CONF_DIR
解决方法:控制台中执行
export HADOOP_CONF_DIR=/home/hadoop/app/hadoop-2.6.0-cdh5.7.0/etc/hadoop
客户端模式输出结果,会在控制台展示
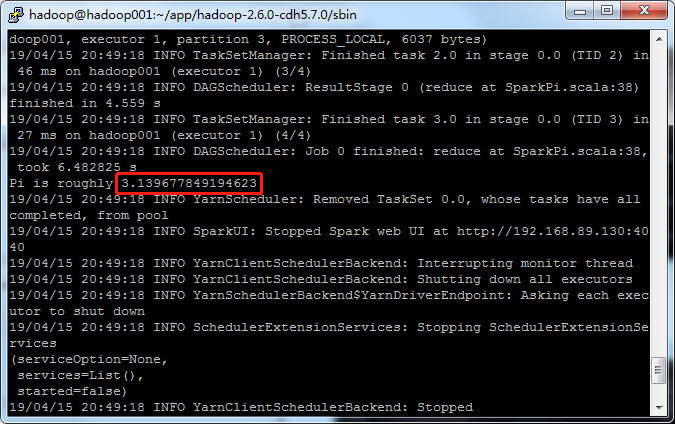
运行SparkPi程序(Cluster模式)
执行Cluster模式的命令,只需要将--master的参数变为yarn-cluster
/home/hadoop/app/spark-2.1.0-bin-2.6.0-cdh5.7.0/bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master yarn-cluster \
--executor-memory 1G \
--num-executors 1 \
--num-executors 1 \
/home/hadoop/app/spark-2.1.0-bin-2.6.0-cdh5.7.0/examples/jars/spark-examples_2.11-2.1.0.jar \
4
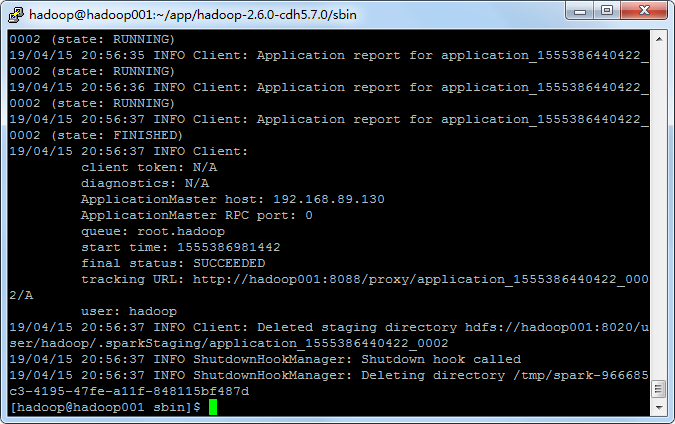
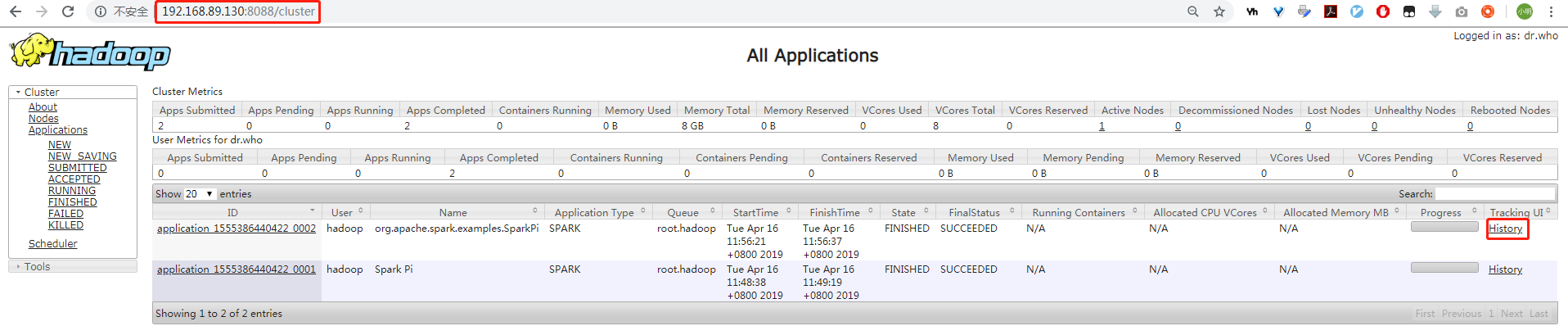
使用cluster模式,控制台上面是没有输出结果的。
法一:使用yarn logs -applicationId application_1555386440422_0002
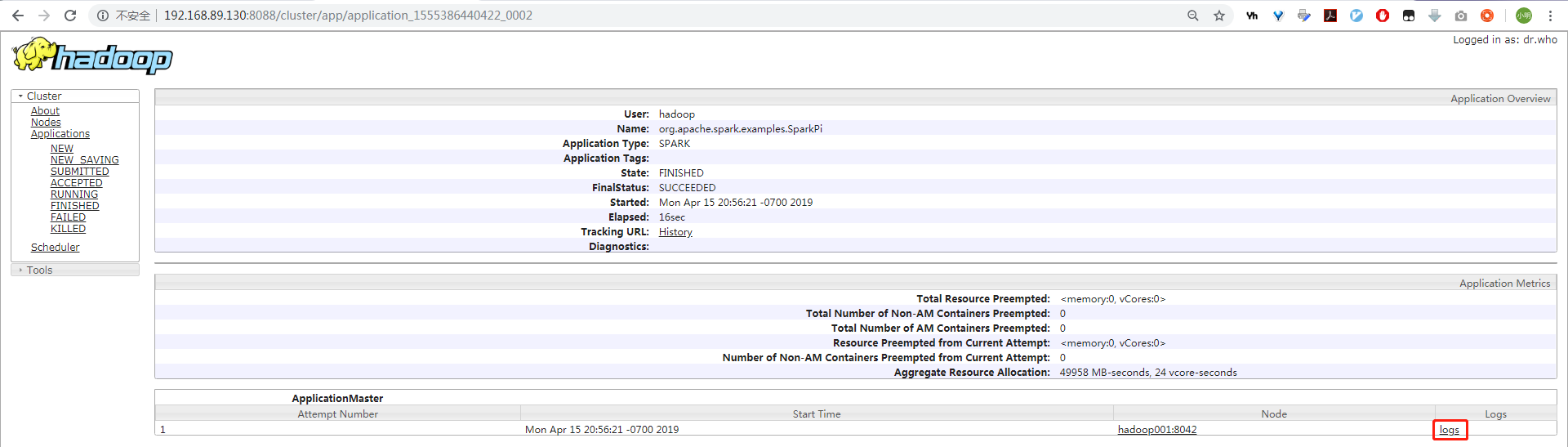
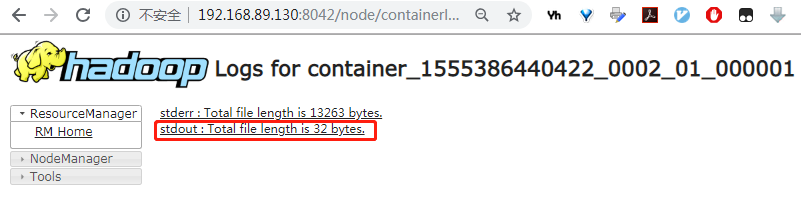
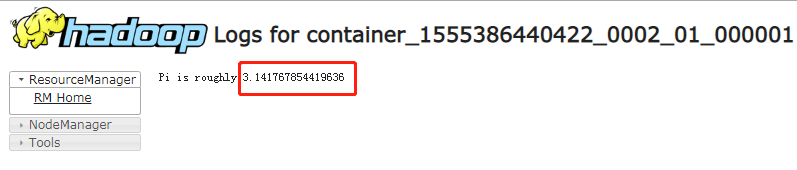
法二:网页上看: