set
我是看着紫书学的 ,但是紫书太深了,我这个菜鸡看不懂啊,就百度了一些大佬的博客,这篇文章还是算是总结吧。。。哦哦,还参考了学长的《算法进阶》
这是紫书上题目的连接,我特意找了一个样例可以复制的
tolower
把字母转换成小写,非字母字符不做处理
度娘解释
可以尝试一下的代码
# include <bits/stdc++.h>
using namespace std;
int main()
{
string a;
getline(cin,a);
cout<<a<<endl;
for(int i=0;i<a.length();i++){
a[i]=tolower(a[i]);
}
cout<<a;
return 0;
}
isalpha
判断字符ch是否为英文字母,若为英文字母,返回非0(小写字母为2,大写字母为1)。若不是字母,返回0。
度娘解释
可以尝试一下的代码
# include <bits/stdc++.h>
using namespace std;
int main()
{
string a;
getline(cin,a);
for(int i=0;i<a.length();i++){
if(isalpha(a[i])) cout<<a[i];
else cout<<"*";
}
return 0;
}
sprintf
字符串格式化命令,主要功能是把格式化的数据写入某个字符串中
原型:int sprintf(char *str, const char *format, …)
度娘解释
可以尝试一下的代码
# include <bits/stdc++.h>
using namespace std;
int main()
{
char str[256]={ 0};
char dataa[]="1024";
int data=97;
double datad=98;
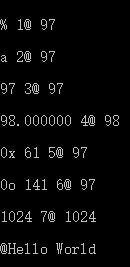
//1. str变成百分比符号
sprintf(str,"%%",data);
cout<<endl;
cout<<str<<" 1@ "<<data<<endl;
//2. 将整数转化为对应的ASCII字元
sprintf(str,"%c",data);
cout<<endl;
cout<<str[0]<<" 2@ "<<data<<endl;
//3. 将data转换为字符串
sprintf(str,"%d",data);
cout<<endl;
cout<<str<<" 3@ "<<data<<endl;
我的手机 2019/3/17 22:50:31
//4. 将datad转化为浮点数
sprintf(str,"%f",datad);
cout<<endl;
cout<<str<<" 4@ "<<datad<<endl;
//5. 获取data的是十六进制 %x转换成小写的十六进制 %X转化成大写的十六进制
sprintf(str,"0x %X",data);
cout<<endl;
cout<<str<<" 5@ "<<data<<endl;
//6. 获取data的八进制
sprintf(str,"0o %o",data);
cout<<endl;
cout<<str<<" 6@ "<<data
我的手机 2019/3/17 22:50:47
//7.
sprintf(str,"%s",dataa);
cout<<endl;
cout<<str<<" 7@ "<<dataa<<endl;
const char *s1="Hello";
const char *s2="World";
sprintf(str,"%s %s",s1,s2);
cout<<endl;
cout<<"@"<<str<<endl;
return 0;
}
运行的结果:
sscanf
读取格式化的字符串中的数据。将参数str的字符串根据参数format字符串来转换并格式化数据,转换后的结果存于对应的参数内。
原型: int sscanf(const char *str, const char *format, …)。
度娘解释
可以尝试一下的代码
# include <bits/stdc++.h>
using namespace std;
int main()
{
char buf[512]={0 };
//一般用法
sscanf("123456 ","%s",buf);
cout<<endl;
printf("%s* @1 \n",buf);
//取指定长度的字符串
sscanf("123456 ","%4s",buf);
cout<<endl;
printf("%s* @2 \n",buf);
//取到指定字符为止的字符串
sscanf("123456 abcdef","%[^ ]",buf);
cout<<endl;
printf("%s* @3 \n",buf);
//取仅包含只当字符集的字符串
sscanf("123456abcdefABCDEF","%[1-9a-z]",buf);
cout<<endl;
printf("%s* @4 \n",buf);
//取到指定字符集为止的字符串 类似于@3 ^别忘记
sscanf("123456abcdefABCDEF","%[^a-b]",buf);
cout<<endl;
printf("%s* @5 \n",buf);
// //取到“”和“”之间的字符串 *别忘记
// sscanf("123456/abcdef\ABCDEF","%*[^/]/%[^\]",buf);
// cout<<endl;
// printf("%s* @6 \n",buf);
//这种用法我还没有搞得很明白,持续更新ing
//取到“”和“”之间的字符串 *别忘记
sscanf("123456/abcdef#ABCDEF","%*[^/]/%[^#]",buf);
cout<<endl;
printf("%s* @6 \n",buf);
//给定一个字符串“hello, world”,仅保留“world”
sscanf("hello, world","%*s%s",buf);
cout<<endl;
printf("%s* @7 \n",buf);
return 0;
}
运行的结果:

insert
插入操作 会按照顺序排好
可以参考这个大佬的blog
# include <bits/stdc++.h>
using namespace std;
set<string> dict;
set<string>::iterator it;
int main()
{
string s,buf;
while(cin>>s){
//cout<<" "<<"@"<<s<<endl;
for(int i=0;i<s.length();i++){
if(isalpha(s[i])) s[i]=tolower(s[i]);
else s[i]=' ';
}
stringstream ss(s);
while(ss>>buf) dict.insert(buf);
// for(it=dict.begin();it!=dict.end();it++) cout<<(*it)<<endl;
// cout<<endl;
}
for(set<string>::iterator it=dict.begin();it!=dict.end();++it)
cout<<*it<<endl;
return 0;
}
注释那一段的运行结果:可以说明插入的时候是按字典顺序插入的。。。

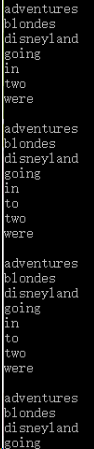




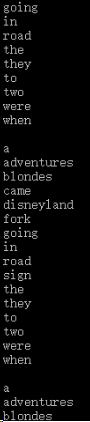


其实吧,它是连起来的,水品有限,写的不好,将就着看吧
最终的运行结果:

本人菜鸡一个,关于算法还在学习,所以blog中的内容大部分是总结各位大佬的,如果有侵权要求删除或者出处注明不全的,非常抱歉,欢迎站内私信啊。。。