一.概念介绍:
1.机器学习:机器学习算法来建立模型,当有新的数据过来,通过模型能够进行预测。
2.特征(features)和标签(labels):
特征:数据的属性,通过这些特征可以代表数据的特点,例如Excel的字段列名,也叫做解释变量或自变量。标签:对数据的预测结果,也叫做因变量。
3.训练数据(train)和测试数据(tset):
训练数据:用于机器学习算法,之后形成我们的机器学习模型。测试数据:用于验证模型的准确率。随机从数据集中抽取80%的数据成为训练数据集,剩下的20%数据用于测试数据集。
4.机器学习包sklearn
二.线性回归:
1.3种线性相关性:正线性相关,负线性相关,不是线性相关。
2.协方差 : 两个变量的相关性程度。
A)协方差的2个功能:统计量的正负反映两个变量的相关性方向:协方差<0,负线性相关;协方差>0,正线性相关。统计量数值大小表示两个变量的相关性程度。
B)协方差公式:
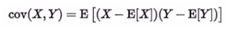
C)协方差被变量的变化幅度所影响了。
3.相关系数r
A)相关系数r是准化后的协方差,它消除了两个变量变化幅度的影响。
B)计算公式:r = x和y的协方差 / (x的标准差 * y的标准差)
C)相关系数r的2个功能:统计量的正负反映两个变量的相关性方向:3个极值(-1,0,1)。统计量数值大小表示两个变量的相关性程度:0-0.3 弱相关,0.3-0.6 中等程度相关,0.6-1 强相关,r的绝对值越大,表示两个变量相关性越强。
4.相关系数矩阵:用于表示各个变量相互之间的相关系数。有多个变量时,相关系数矩阵可以让我们一眼就能够确定任何两个变量之间的相关关系。
5.线性回归的本质: 得到一条最佳拟合线
最佳拟合线:散点图上绘制一条直线,使这条直线尽量的接近每一个数据点。
回归方程: y=a + b x
最小二乘法:求最佳拟合线的方法。公式:误差平方和SSE=Σ(实际值 - 预测值)²
6.评估模型:决定系数R平方(r-squared score)
A) 误差平方和会因为数据点多少而影响评价的结果,所以有评估指标:决定系数R平方
B) 误差平方和=总波动中有多少没有被回归线所描述,有多少百分比的y波动被回归线描述 = 1 - 误差平方和 / 总波动 = 决定系数R平方
C)决定系数R平方的两个功能:表示回归线拟合程度:有多少百分比的y波动被回归线描述。值大小表示模型精确度:R平方越高(越接近1),回归模型越精确。
三.逻辑回归
1.分类问题的本质:得到一个决策面
2.二分分类和逻辑回归
二分分类是指分类结果标签只有2个。二分分类问题使用逻辑回归算法。逻辑回归虽然名字里带回归,但其实不是回归算法,而是分类算法。
3.逻辑回归的核心:逻辑函数
A)逻辑函数是S形曲线,y值是从0到1变化,和垂直轴相交在0.5处的地方。通过逻辑函数可以把y的值控制在0到1之间。
B)逻辑函数的公式:
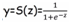
,其中括号里面的参数Z就是回归函数 z = a + bx
C)逻辑回归之所以叫回归,是因为它的逻辑函数参数Z是一个回归函数。
4.逻辑函数值
逻辑函数值y表示:当分类结果的标签等于1时,x对应的概率值。
5.评估模型:正确率
正确率=正确分类人数 / 数据总数
泰坦尼克号生存率预测
1.提出问题
什么样的人在泰坦尼克号中更容易存活?
2.理解数据
2.1 采集数据
从Kaggle泰坦尼克号项目页面下载数据:https://www.kaggle.com/c/titanic
2.2 导入数据
# 忽略警告提示
import warnings
warnings.filterwarnings('ignore')
#导入处理数据包
import numpy as np
import pandas as pd
#导入数据
#训练数据集
train = pd.read_csv("./train.csv")
#测试数据集
test = pd.read_csv("./test.csv")
#这里要记住训练数据集有891条数据,方便后面从中拆分出测试数据集用于提交Kaggle结果
print ('训练数据集:',train.shape,'测试数据集:',test.shape)
#合并数据集,方便同时对两个数据集进行清洗
full = train.append( test , ignore_index = True )
print ('合并后的数据集:',full.shape)
合并后的数据集: (1309, 12)2.3 查看数据集信息
#查看数据
full.head()
'''
describe只能查看数据类型的描述统计信息,对于其他类型的数据不显示,
比如字符串类型姓名(name),客舱号(Cabin)
这很好理解,因为描述统计指标是计算数值,所以需要该列的数据类型是数据
'''
#获取数据类型列的描述统计信息
full.describe()# 查看每一列的数据类型,和数据总数
full.info()
'''
我们发现数据总共有1309行。
其中数据类型列:年龄(Age)、船舱号(Cabin)里面有缺失数据:
1)年龄(Age)里面数据总数是1046条,缺失了1309-1046=263,缺失率263/1309=20%
2)船票价格(Fare)里面数据总数是1308条,缺失了1条数据
字符串列:
1)登船港口(Embarked)里面数据总数是1307,只缺失了2条数据,缺失比较少
2)船舱号(Cabin)里面数据总数是295,缺失了1309-295=1014,缺失率=1014/1309=77.5%,缺失比较大
这为我们下一步数据清洗指明了方向,只有知道哪些数据缺失数据,我们才能有针对性的处理。
'''
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 1309 entries, 0 to 1308
Data columns (total 12 columns):
Age 1046 non-null float64
Cabin 295 non-null object
Embarked 1307 non-null object
Fare 1308 non-null float64
Name 1309 non-null object
Parch 1309 non-null int64
PassengerId 1309 non-null int64
Pclass 1309 non-null int64
Sex 1309 non-null object
SibSp 1309 non-null int64
Survived 891 non-null float64
Ticket 1309 non-null object
dtypes: float64(3), int64(4), object(5)
memory usage: 122.8+ KB
3.1 数据预处理
缺失值处理
'''
我们发现数据总共有1309行。
其中数据类型列:年龄(Age)、船舱号(Cabin)里面有缺失数据:
1)年龄(Age)里面数据总数是1046条,缺失了1309-1046=263,缺失率263/1309=20%
2)船票价格(Fare)里面数据总数是1308条,缺失了1条数据
对于数据类型,处理缺失值最简单的方法就是用平均数来填充缺失值
'''
print('处理前:')
full.info()
#年龄(Age)
full['Age']=full['Age'].fillna( full['Age'].mean() )
#船票价格(Fare)
full['Fare'] = full['Fare'].fillna( full['Fare'].mean() )
print('处理红后:')
full.info()
处理前:
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 1309 entries, 0 to 1308
Data columns (total 12 columns):
Age 1046 non-null float64
Cabin 295 non-null object
Embarked 1307 non-null object
Fare 1308 non-null float64
Name 1309 non-null object
Parch 1309 non-null int64
PassengerId 1309 non-null int64
Pclass 1309 non-null int64
Sex 1309 non-null object
SibSp 1309 non-null int64
Survived 891 non-null float64
Ticket 1309 non-null object
dtypes: float64(3), int64(4), object(5)
memory usage: 122.8+ KB
处理红后:
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 1309 entries, 0 to 1308
Data columns (total 12 columns):
Age 1309 non-null float64
Cabin 295 non-null object
Embarked 1307 non-null object
Fare 1309 non-null float64
Name 1309 non-null object
Parch 1309 non-null int64
PassengerId 1309 non-null int64
Pclass 1309 non-null int64
Sex 1309 non-null object
SibSp 1309 non-null int64
Survived 891 non-null float64
Ticket 1309 non-null object
dtypes: float64(3), int64(4), object(5)
memory usage: 122.8+ KB
#检查数据处理是否正常
full.head()''
总数据是1309
字符串列:
1)登船港口(Embarked)里面数据总数是1307,只缺失了2条数据,缺失比较少
2)船舱号(Cabin)里面数据总数是295,缺失了1309-295=1014,缺失率=1014/1309=77.5%,缺失比较大
'''
#登船港口(Embarked):查看里面数据长啥样
'''
出发地点:S=英国南安普顿Southampton
途径地点1:C=法国 瑟堡市Cherbourg
途径地点2:Q=爱尔兰 昆士敦Queenstown
'''
full['Embarked'].head()
0 S
1 C
2 S
3 S
4 S
Name: Embarked, dtype: object
'''
分类变量Embarked,看下最常见的类别,用其填充
'''
full['Embarked'].value_counts()
'''
从结果来看,S类别最常见。我们将缺失值填充为最频繁出现的值:
S=英国南安普顿Southampton
'''
full['Embarked'] = full['Embarked'].fillna( 'S' )
#船舱号(Cabin):查看里面数据长啥样
full['Cabin'].head()
0 NaN
1 C85
2 NaN
3 C123
4 NaN
Name: Cabin, dtype: object
#缺失数据比较多,船舱号(Cabin)缺失值填充为U,表示未知(Uknow)
full['Cabin'] = full['Cabin'].fillna( 'U' )
#检查数据处理是否正常
full.head()#查看最终缺失值处理情况,记住生成情况(Survived)这里一列是我们的标签,用来做机器学习预测的,不需要处理这一列
full.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 1309 entries, 0 to 1308
Data columns (total 12 columns):
Age 1309 non-null float64
Cabin 1309 non-null object
Embarked 1309 non-null object
Fare 1309 non-null float64
Name 1309 non-null object
Parch 1309 non-null int64
PassengerId 1309 non-null int64
Pclass 1309 non-null int64
Sex 1309 non-null object
SibSp 1309 non-null int64
Survived 891 non-null float64
Ticket 1309 non-null object
dtypes: float64(3), int64(4), object(5)
memory usage: 122.8+ KB3.2 特征提取
3.2.1数据分类
查看数据类型,分为3种数据类型。并对类别数据处理:用数值代替类别,并进行One-hot编码
'''
1.数值类型:
乘客编号(PassengerId),年龄(Age),船票价格(Fare),同代直系亲属人数(SibSp),不同代直系亲属人数(Parch)
2.时间序列:无
3.分类数据:
1)有直接类别的
乘客性别(Sex):男性male,女性female
登船港口(Embarked):出发地点S=英国南安普顿Southampton,途径地点1:C=法国 瑟堡市Cherbourg,出发地点2:Q=爱尔兰 昆士敦Queenstown
客舱等级(Pclass):1=1等舱,2=2等舱,3=3等舱
2)字符串类型:可能从这里面提取出特征来,也归到分类数据中
乘客姓名(Name)
客舱号(Cabin)
船票编号(Ticket)
'''
full.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 1309 entries, 0 to 1308
Data columns (total 12 columns):
Age 1309 non-null float64
Cabin 1309 non-null object
Embarked 1309 non-null object
Fare 1309 non-null float64
Name 1309 non-null object
Parch 1309 non-null int64
PassengerId 1309 non-null int64
Pclass 1309 non-null int64
Sex 1309 non-null object
SibSp 1309 non-null int64
Survived 891 non-null float64
Ticket 1309 non-null object
dtypes: float64(3), int64(4), object(5)
memory usage: 122.8+ KB3.2.1 分类数据:有直接类别的
- 乘客性别(Sex): 男性male,女性female
- 登船港口(Embarked):出发地点S=英国南安普顿Southampton,途径地点1:C=法国 瑟堡市Cherbourg,出发地点2:Q=爱尔兰 昆士敦Queenstown
- 客舱等级(Pclass):1=1等舱,2=2等舱,3=3等舱
性别
#查看性别数据这一列
full['Sex'].head()
0 male
1 female
2 female
3 female
4 male
Name: Sex, dtype: object
'''
将性别的值映射为数值
男(male)对应数值1,女(female)对应数值0
'''
sex_mapDict={'male':1,
'female':0}
#map函数:对Series每个数据应用自定义的函数计算
full['Sex']=full['Sex'].map(sex_mapDict)
full.head()Age Cabin Embarked Fare Name Parch PassengerId Pclass Sex SibSp Survived Ticket 0 22.0 U S 7.2500 Braund, Mr. Owen Harris 0 1 3 1 1 0.0 A/5 21171 1 38.0 C85 C 71.2833 Cumings, Mrs. John Bradley (Florence Briggs Th... 0 2 1 0 1 1.0 PC 17599 2 26.0 U S 7.9250 Heikkinen, Miss. Laina 0 3 3 0 0 1.0 STON/O2. 3101282 3 35.0 C123 S 53.1000 Futrelle, Mrs. Jacques Heath (Lily May Peel) 0 4 1 0 1 1.0 113803 4 35.0 U S 8.0500 Allen, Mr. William Henry 0 5 3 1 0 0.0 373450
登船港口(Embarked)
'''
登船港口(Embarked)的值是:
出发地点:S=英国南安普顿Southampton
途径地点1:C=法国 瑟堡市Cherbourg
途径地点2:Q=爱尔兰 昆士敦Queenstown
'''
#查看该类数据内容
full['Embarked'].head()
0 S
1 C
2 S
3 S
4 S
Name: Embarked, dtype: object
#存放提取后的特征
embarkedDf = pd.DataFrame()
'''
使用get_dummies进行one-hot编码,产生虚拟变量(dummy variables),列名前缀是Embarked
'''
embarkedDf = pd.get_dummies( full['Embarked'] , prefix='Embarked' )
embarkedDf.head()Embarked_C Embarked_Q Embarked_S 0 0 0 1 1 1 0 0 2 0 0 1 3 0 0 1 4 0 0 1
#添加one-hot编码产生的虚拟变量(dummy variables)到泰坦尼克号数据集full
full = pd.concat([full,embarkedDf],axis=1)
'''
因为已经使用登船港口(Embarked)进行了one-hot编码产生了它的虚拟变量(dummy variables)
所以这里把登船港口(Embarked)删掉
'''
full.drop('Embarked',axis=1,inplace=True)
full.head()Age Cabin Fare Name Parch PassengerId Pclass Sex SibSp Survived Ticket Embarked_C Embarked_Q Embarked_S 0 22.0 U 7.2500 Braund, Mr. Owen Harris 0 1 3 1 1 0.0 A/5 21171 0 0 1 1 38.0 C85 71.2833 Cumings, Mrs. John Bradley (Florence Briggs Th... 0 2 1 0 1 1.0 PC 17599 1 0 0 2 26.0 U 7.9250 Heikkinen, Miss. Laina 0 3 3 0 0 1.0 STON/O2. 3101282 0 0 1 3 35.0 C123 53.1000 Futrelle, Mrs. Jacques Heath (Lily May Peel) 0 4 1 0 1 1.0 113803 0 0 1 4 35.0 U 8.0500 Allen, Mr. William Henry 0 5 3 1 0 0.0 373450 0 0 1
客舱等级(Pclass)
'''
客舱等级(Pclass):
1=1等舱,2=2等舱,3=3等舱
'''
#存放提取后的特征
pclassDf = pd.DataFrame()
#使用get_dummies进行one-hot编码,列名前缀是Pclass
pclassDf = pd.get_dummies( full['Pclass'] , prefix='Pclass' )
pclassDf.head()Pclass_1 Pclass_2 Pclass_3 0 0 0 1 1 1 0 0 2 0 0 1 3 1 0 0 4 0 0 1
#添加one-hot编码产生的虚拟变量(dummy variables)到泰坦尼克号数据集full
full = pd.concat([full,pclassDf],axis=1)
#删掉客舱等级(Pclass)这一列
full.drop('Pclass',axis=1,inplace=True)
full.head()3.2.1 分类数据:字符串类型
字符串类型:可能从这里面提取出特征来,也归到分类数据中,这里数据有:
- 乘客姓名(Name)
- 客舱号(Cabin)
- 船票编号(Ticket)
从姓名中提取头衔
'''
查看姓名这一列长啥样
注意到在乘客名字(Name)中,有一个非常显著的特点:
乘客头衔每个名字当中都包含了具体的称谓或者说是头衔,将这部分信息提取出来后可以作为非常有用一个新变量,可以帮助我们进行预测。
例如:
Braund, Mr. Owen Harris
Heikkinen, Miss. Laina
Oliva y Ocana, Dona. Fermina
Peter, Master. Michael J
'''
full[ 'Name' ].head()
0 Braund, Mr. Owen Harris
1 Cumings, Mrs. John Bradley (Florence Briggs Th...
2 Heikkinen, Miss. Laina
3 Futrelle, Mrs. Jacques Heath (Lily May Peel)
4 Allen, Mr. William Henry
Name: Name, dtype: object
#练习从字符串中提取头衔,例如Mr
#split用于字符串分割,返回一个列表
#我们看到姓名中'Braund, Mr. Owen Harris',逗号前面的是“名”,逗号后面是‘头衔. 姓’
name1='Braund, Mr. Owen Harris'
'''
split用于字符串按分隔符分割,返回一个列表。这里按逗号分隔字符串
也就是字符串'Braund, Mr. Owen Harris'被按分隔符,'拆分成两部分[Braund,Mr. Owen Harris]
你可以把返回的列表打印出来瞧瞧,这里获取到列表中元素序号为1的元素,也就是获取到头衔所在的那部分,即Mr. Owen Harris这部分
'''
#Mr. Owen Harris
str1=name1.split( ',' )[1]
'''
继续对字符串Mr. Owen Harris按分隔符'.'拆分,得到这样一个列表[Mr, Owen Harris]
这里获取到列表中元素序号为0的元素,也就是获取到头衔所在的那部分Mr
'''
#Mr.
str2=str1.split( '.' )[0]
#strip() 方法用于移除字符串头尾指定的字符(默认为空格)
str3=str2.strip()
'''
定义函数:从姓名中获取头衔
'''
def getTitle(name):
str1=name.split( ',' )[1] #Mr. Owen Harris
str2=str1.split( '.' )[0]#Mr
#strip() 方法用于移除字符串头尾指定的字符(默认为空格)
str3=str2.strip()
return str3
#存放提取后的特征
titleDf = pd.DataFrame()
#map函数:对Series每个数据应用自定义的函数计算
titleDf['Title'] = full['Name'].map(getTitle)
titleDf.head() '''
定义以下几种头衔类别:
Officer政府官员
Royalty王室(皇室)
Mr已婚男士
Mrs已婚妇女
Miss年轻未婚女子
Master有技能的人/教师
'''
#姓名中头衔字符串与定义头衔类别的映射关系
title_mapDict = {
"Capt": "Officer",
"Col": "Officer",
"Major": "Officer",
"Jonkheer": "Royalty",
"Don": "Royalty",
"Sir" : "Royalty",
"Dr": "Officer",
"Rev": "Officer",
"the Countess":"Royalty",
"Dona": "Royalty",
"Mme": "Mrs",
"Mlle": "Miss",
"Ms": "Mrs",
"Mr" : "Mr",
"Mrs" : "Mrs",
"Miss" : "Miss",
"Master" : "Master",
"Lady" : "Royalty"
}
#map函数:对Series每个数据应用自定义的函数计算
titleDf['Title'] = titleDf['Title'].map(title_mapDict)
#使用get_dummies进行one-hot编码
titleDf = pd.get_dummies(titleDf['Title'])
titleDf.head()Master Miss Mr Mrs Officer Royalty 0 0 0 1 0 0 0 1 0 0 0 1 0 0 2 0 1 0 0 0 0 3 0 0 0 1 0 0 4 0 0 1 0 0 0
#添加one-hot编码产生的虚拟变量(dummy variables)到泰坦尼克号数据集full
full = pd.concat([full,titleDf],axis=1)
#删掉姓名这一列
full.drop('Name',axis=1,inplace=True)
full.head()从客舱号中提取客舱类别
#补充知识:匿名函数
'''
python 使用 lambda 来创建匿名函数。
所谓匿名,意即不再使用 def 语句这样标准的形式定义一个函数,预防如下:
lambda 参数1,参数2:函数体或者表达式
'''
# 定义匿名函数:对两个数相加
sum = lambda a,b: a + b
# 调用sum函数
print ("相加后的值为 : ", sum(10,20))
相加后的值为 : 30
'''
客舱号的首字母是客舱的类别
'''
#查看客舱号的内容
full['Cabin'].head()
0 U
1 C85
2 U
3 C123
4 U
Name: Cabin, dtype: object
#存放客舱号信息
cabinDf = pd.DataFrame()
'''
客场号的类别值是首字母,例如:
C85 类别映射为首字母C
'''
full[ 'Cabin' ] = full[ 'Cabin' ].map( lambda c : c[0] )
##使用get_dummies进行one-hot编码,列名前缀是Cabin
cabinDf = pd.get_dummies( full['Cabin'] , prefix = 'Cabin' )
cabinDf.head()#添加one-hot编码产生的虚拟变量(dummy variables)到泰坦尼克号数据集full
full = pd.concat([full,cabinDf],axis=1)
#删掉客舱号这一列
full.drop('Cabin',axis=1,inplace=True)
full.head()建立家庭人数和家庭类别
#存放家庭信息
familyDf = pd.DataFrame()
'''
家庭人数=同代直系亲属数(Parch)+不同代直系亲属数(SibSp)+乘客自己
(因为乘客自己也是家庭成员的一个,所以这里加1)
'''
familyDf[ 'FamilySize' ] = full[ 'Parch' ] + full[ 'SibSp' ] + 1
'''
家庭类别:
小家庭Family_Single:家庭人数=1
中等家庭Family_Small: 2<=家庭人数<=4
大家庭Family_Large: 家庭人数>=5
'''
#if 条件为真的时候返回if前面内容,否则返回0
familyDf[ 'Family_Single' ] = familyDf[ 'FamilySize' ].map( lambda s : 1 if s == 1 else 0 )
familyDf[ 'Family_Small' ] = familyDf[ 'FamilySize' ].map( lambda s : 1 if 2 <= s <= 4 else 0 )
familyDf[ 'Family_Large' ] = familyDf[ 'FamilySize' ].map( lambda s : 1 if 5 <= s else 0 )
familyDf.head()FamilySize Family_Single Family_Small Family_Large 0 2 0 1 0 1 2 0 1 0 2 1 1 0 0 3 2 0 1 0 4 1 1 0 0
#添加one-hot编码产生的虚拟变量(dummy variables)到泰坦尼克号数据集full
full = pd.concat([full,familyDf],axis=1)
full.head()#到现在我们已经有了这么多个特征了
full.shape
(1309, 33)3.3 特征选择
相关系数法:计算各个特征的相关系数
#相关性矩阵
corrDf = full.corr()
corrDf'''
查看各个特征与生成情况(Survived)的相关系数,
ascending=False表示按降序排列
'''
corrDf['Survived'].sort_values(ascending =False)
Survived 1.000000
Mrs 0.344935
Miss 0.332795
Pclass_1 0.285904
Family_Small 0.279855
Fare 0.257307
Cabin_B 0.175095
Embarked_C 0.168240
Cabin_D 0.150716
Cabin_E 0.145321
Cabin_C 0.114652
Pclass_2 0.093349
Master 0.085221
Parch 0.081629
Cabin_F 0.057935
Royalty 0.033391
Cabin_A 0.022287
FamilySize 0.016639
Cabin_G 0.016040
Embarked_Q 0.003650
PassengerId -0.005007
Cabin_T -0.026456
Officer -0.031316
SibSp -0.035322
Age -0.070323
Family_Large -0.125147
Embarked_S -0.149683
Family_Single -0.203367
Cabin_U -0.316912
Pclass_3 -0.322308
Sex -0.543351
Mr -0.549199
Name: Survived, dtype: float64根据各个特征与生成情况(Survived)的相关系数大小,我们选择了这几个特征作为模型的输入:
头衔(前面所在的数据集titleDf)、客舱等级(pclassDf)、家庭大小(familyDf)、船票价格(Fare)、船舱号(cabinDf)、登船港口(embarkedDf)、性别(Sex)
#特征选择
full_X = pd.concat( [titleDf,#头衔
pclassDf,#客舱等级
familyDf,#家庭大小
full['Fare'],#船票价格
cabinDf,#船舱号
embarkedDf,#登船港口
full['Sex']#性别
] , axis=1 )
full_X.head()4.构建模型
用训练数据和某个机器学习算法得到机器学习模型,用测试数据评估模型
4.1 建立训练数据集和测试数据集
#原始数据集有891行
sourceRow=891
'''
sourceRow是我们在最开始合并数据前知道的,原始数据集有总共有891条数据
从特征集合full_X中提取原始数据集提取前891行数据时,我们要减去1,因为行号是从0开始的。
'''
#原始数据集:特征
source_X = full_X.loc[0:sourceRow-1,:]
#原始数据集:标签
source_y = full.loc[0:sourceRow-1,'Survived']
#预测数据集:特征
pred_X = full_X.loc[sourceRow:,:]
'''
确保这里原始数据集取的是前891行的数据,不然后面模型会有错误
'''
#原始数据集有多少行
print('原始数据集有多少行:',source_X.shape[0])
#预测数据集大小
print('原始数据集有多少行:',pred_X.shape[0])
原始数据集有多少行: 891
原始数据集有多少行: 418
'''
从原始数据集(source)中拆分出训练数据集(用于模型训练train),测试数据集(用于模型评估test)
train_test_split是交叉验证中常用的函数,功能是从样本中随机的按比例选取train data和test data
train_data:所要划分的样本特征集
train_target:所要划分的样本结果
test_size:样本占比,如果是整数的话就是样本的数量
'''
from sklearn.cross_validation import train_test_split
#建立模型用的训练数据集和测试数据集
train_X, test_X, train_y, test_y = train_test_split(source_X ,
source_y,
train_size=.8)
#原始数据查看
source_y.head()
0 0.0
1 1.0
2 1.0
3 1.0
4 0.0
Name: Survived, dtype: float644.2 选择机器学习算法
选择一个机器学习算法,用于模型的训练。如果你是新手,建议从逻辑回归算法开始
#第1步:导入算法
from sklearn.linear_model import LogisticRegression
#第2步:创建模型:逻辑回归(logisic regression)
model = LogisticRegression()4.3 训练模型
#第3步:训练模型
model.fit( train_X , train_y )
LogisticRegression(C=1.0, class_weight=None, dual=False, fit_intercept=True,
intercept_scaling=1, max_iter=100, multi_class='ovr', n_jobs=1,
penalty='l2', random_state=None, solver='liblinear', tol=0.0001,
verbose=0, warm_start=False)5.评估模型
# 分类问题,score得到的是模型的正确率
model.score(test_X , test_y )
0.84357541899441346