原文地址:
作者:Synced
编译:ronghuaiyang
----------------------------------------------------------------------------------------------------
导读
注意力机制并不神秘或复杂。它只是一个由参数和数学构成的接口。你可以在任何合适的地方插入它,并且可能会提升结果。
什么是Attention?
Attention是一个简单的向量,通常使用softmax函数来输出得到。
在注意力机制之前,翻译依赖于阅读一个完整的句子,将所有的信息压缩成一个固定长度的向量,正如你可以想象的那样,一个几百个单词组成的句子由一个固定长度的向量表示,肯定会导致信息丢失、翻译不足等。
然而,注意力机制在一定程度上解决了这个问题。它允许机器翻译查看原句所包含的所有信息,然后根据所处理的当前单词和上下文生成正确的单词。它甚至可以让翻译器放大或缩小(关注本地或全局特征)。
注意力机制并不神秘或复杂。它只是一个由参数和数学构成的接口。你可以在任何合适的地方插入它,并且可能会提升结果。
为什么用Attention?
概率语言模型的核心是用马尔可夫假设为一个句子分配一个概率。由于句子由不同数量的单词组成,很自然的引入了RNN对单词之间的条件概率进行建模。
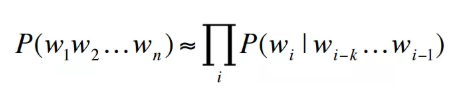
Vanilla RNN(最经典的)在建模时经常陷入困境:
-
结构困境:在现实世界中,输出和输入的长度可以完全不同,而普通的RNN只能处理固定长度的问题,这对对齐来说是困难的。考虑一个EN-FR的翻译例子:“he doesn’t like apples”→“Il n’aime pas les pommes”。
-
数学本质:它有梯度消失/爆炸的问题,这意味着当句子足够长(最多4个单词)时很难训练。
翻译通常需要任意的输入长度和输出长度,针对上述不足,采用了编解码器模型,将基本的RNN单元转换为GRU或LSTM单元,用ReLU代替双曲正切激活。这里我们使用GRU单元。
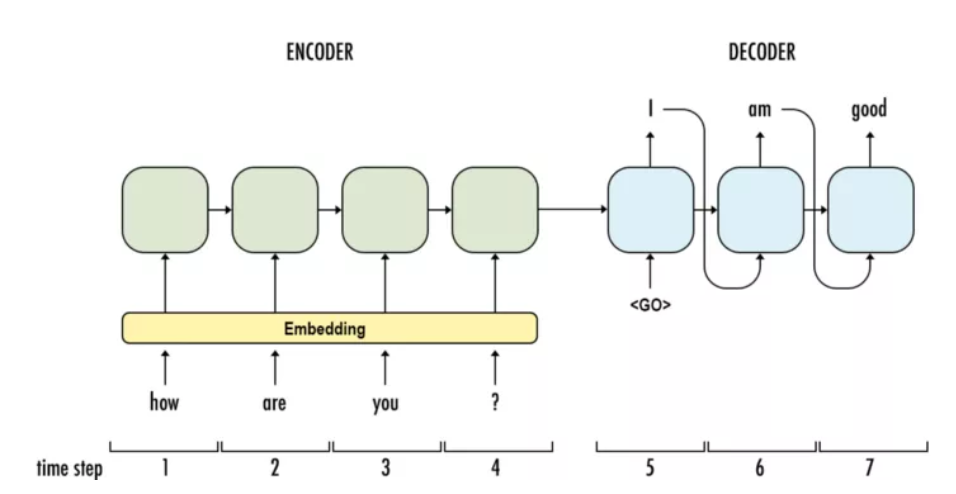
为了提高计算效率,嵌入层将离散单词映射到密集向量中。然后将嵌入的词向量按顺序输入编码器,即GRU单元。编码过程中发生了什么?信息从左到右流动,每个单词向量不仅根据当前输入,而且根据所有以前的单词来学习。当语句被完全读取时,编码器将在第4步生成一个输出和一个隐藏状态,以便进一步处理。对于编码部分,解码器(也是GRUs)从编码器中获取隐藏状态,由教师强制训练(将前一个单元的输出作为当前输入的模式),然后按顺序生成翻译单词。
这个模型可以应用于N-to-M序列,这看起来很神奇,但是仍然有一个主要的缺陷没有解决:一个隐藏状态真的足够吗?
是的,这就需要用到Attention。
Attention如何工作?
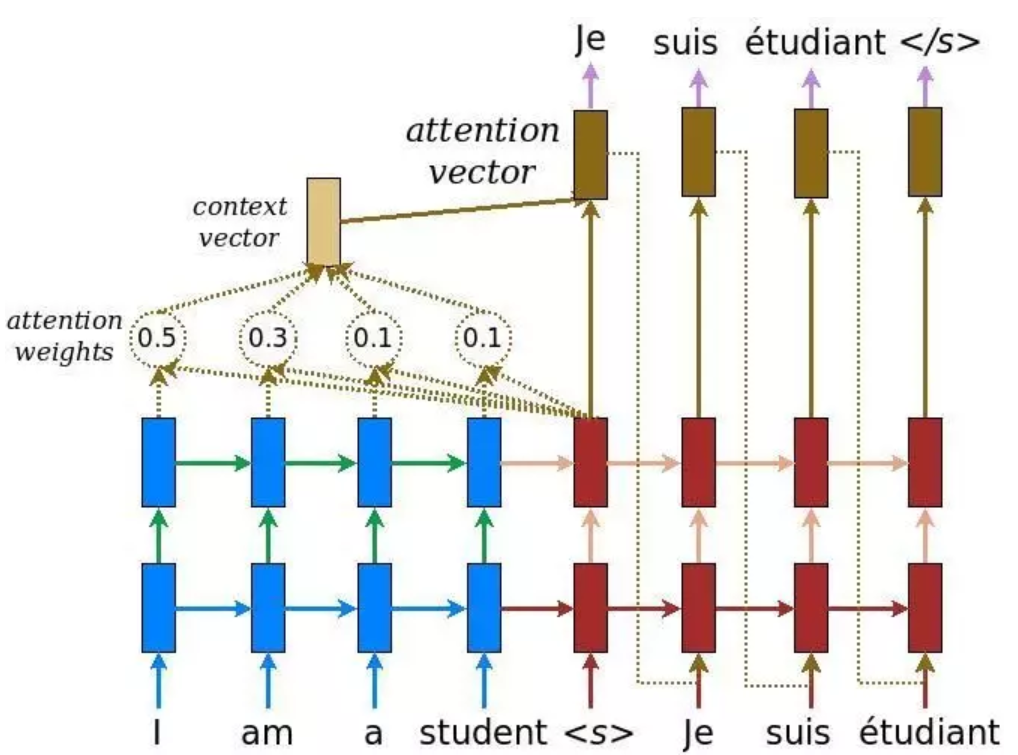
与基本的编解码器体系结构类似,这种奇特的机制在编码器和解码器之间插入了一个上下文向量。根据上图,蓝色表示编码器,红色表示解码器,我们可以看到,上下文向量将所有单元格的输出作为输入来计算每个解码器想要生成的源语言单词的概率分布。利用这种机制,解码器可以捕获某种全局信息,而不只是基于一个隐藏状态进行推断。
构建上下文向量相当简单。对于一个固定的目标字,首先,我们循环遍历所有编码器的状态,以比较目标状态和源状态,从而为编码器中的每个状态生成分数。然后我们可以使用softmax对所有的分数进行标准化,从而生成以目标状态为条件的概率分布。最后引入权值,使上下文向量易于训练。就是这样。数学计算如下:

要理解看似复杂的数学,我们需要记住三个关键点:
-
在解码过程中,对每个输出单词计算上下文向量。我们将得到一个二维矩阵,它的大小是目标单词的个数乘以源单词的个数。方程(1)演示了如何计算给定一个目标字和一组源字的单个值。
-
一旦计算了上下文向量,就可以通过上下文向量、目标词和注意力函数f来计算注意力向量。
-
我们需要可训练的注意力机制。根据式(4),两种风格都提供了可训练的权重(Luong’s中的W, Bahdanau’s中的W1和W2)。因此,不同的风格可能导致不同的性能。
—END—
英文原文:https://medium.com/syncedreview/a-brief-overview-of-attention-mechanism-13c578ba9129
相关文章链接
2、序列模型简介:RNN, 双向RNN, LSTM, GRU,有图有真相
3、动画图解RNN, LSTM 和 GRU,没有比这个更直观的了!
--------------------------------------------------------------------------------------