版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/ZWX2445205419/article/details/89067628
背景介绍
看了很多教程,发现和TensorFlow官方教程中的都差不多,但我想要的训练方式是:
- 指定最大训练步数
- 训练x步后,在测试集上进行一次全量(或抽样)测试
- 每x步记录一次训练和测试结果
- 我在GitHub上创建了一个TensorFlow训练模型的模板:https://github.com/xmuwenxiang/tensorflow-my-template
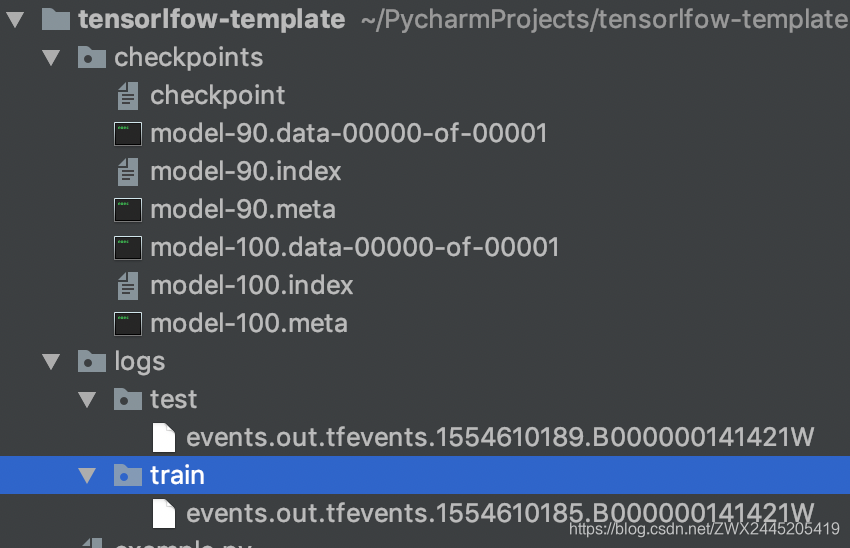
目录结构
代码
#! -*- coding: utf-8 -*-
import tensorflow as tf
import numpy as np
batch_size = 32 # batch size
max_to_keep = 2 # 最多保存模型数
max_step = 100 # 最大训练迭代次数
best_acc = 0.0 # 测试集最优准确率
test_frequency = 10 # 每训练10个step进行一次全量测试
checkpoint_dir = "checkpoints/model" # 检查点保存路径
log_dir = "logs/" # 日志保存路径
# 获取MNIST数据集
mnist = tf.keras.datasets.mnist
# 当网络无法下载mnist数据集是,可以手动下载mnist.npz文件后在load_data参数中指定文件路径
(x_train, y_train), (x_test, y_test) = mnist.load_data(
"/Users/zhangwenxiang02/Workspace/tensorflow-my-template/data/mnist.npz")
# 数据集处理
# 训练集
train_dataset = tf.data.Dataset.from_tensor_slices((x_train, y_train))
train_dataset = train_dataset.shuffle(buffer_size=1000).\
batch(batch_size).repeat().\
prefetch(buffer_size=batch_size * 2)
# 测试集
test_dataset = tf.data.Dataset.from_tensor_slices((x_test, y_test))
test_dataset = test_dataset.batch(batch_size).\
prefetch(buffer_size=batch_size * 2)
# 创建数据迭代器
train_iterator = train_dataset.make_one_shot_iterator()
test_iterator = test_dataset.make_initializable_iterator() # 可初始化迭代器
# 获取一批数据
train_next_element = train_iterator.get_next()
test_next_element = test_iterator.get_next()
# 数据占位
x = tf.placeholder(tf.float32, shape=[None, 28, 28])
y = tf.placeholder(tf.int64, shape=[None, ])
# 记录输入图片
image_shaped_input = tf.reshape(x, [-1, 28, 28, 1])
tf.summary.image("input", image_shaped_input, max_outputs=10) # 记录输入数据
# global step
globa_step = tf.Variable(0, trainable=False)
# 创建网络结构
with tf.name_scope("net"):
x_input = tf.reshape(x, shape=[-1, 784])
d1 = tf.layers.dense(x_input, 512, activation=tf.nn.relu, name="dense1")
d2 = tf.layers.dense(d1, 10, name="dense2")
with tf.name_scope("loss"):
loss = tf.reduce_mean(tf.nn.sparse_softmax_cross_entropy_with_logits(labels=y, logits=d2))
tf.summary.scalar("loss", loss) # 记录loss
with tf.name_scope("train_step"):
train_step = tf.train.AdamOptimizer(learning_rate=0.001).\
minimize(loss, global_step=globa_step) # global step用来记录全局步数,每进行一次train_step,global_step会自动加1
with tf.name_scope("accuracy"):
correct_prediction = tf.equal(tf.argmax(d2, 1), y)
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
tf.summary.scalar("acc", accuracy) # 记录accuracy
# 模型保存器
saver = tf.train.Saver(max_to_keep=max_to_keep)
# 用来记录多个step的loss和accuracy
train_losses = []
train_accs = []
# 合并记录操作
merged = tf.summary.merge_all()
# tf.local_variables_initializer()主要用来初始化global_step,
# 因为global_step是trainable=False的变量,所以它在local_variables集合中
init = tf.group(tf.global_variables_initializer(), tf.local_variables_initializer())
# 训练模型
with tf.Session() as sess:
# 日志记录
train_writer = tf.summary.FileWriter(log_dir + "train/", sess.graph) # 记录默认图
test_writer = tf.summary.FileWriter(log_dir + "test/")
sess.run(init) # 初始化全局变量
# 加载模型
checkpoint_path = tf.train.latest_checkpoint(checkpoint_dir)
if checkpoint_path:
saver.restore(sess, checkpoint_path) # 加载最近的检查点
# saver.restore(sess, checkpoint_dir) # 也可以加载指定的模型路径
for step in range(1, max_step + 1): # 训练指定的步数
x_train, y_train = sess.run(train_next_element)
train_summary, _, train_loss, train_acc = sess.run([merged, train_step, loss, accuracy], feed_dict={x: x_train, y: y_train})
train_writer.add_summary(train_summary, globa_step.eval(sess)) # 这里的step也可以用global_step.eval(sess)来代替
train_losses.append(train_loss)
train_accs.append(train_acc)
# 每隔指定训练step进行一次全量测试
if step % test_frequency == 0:
sess.run(test_iterator.initializer)
test_losses = []
test_accs = []
while True:
try:
x_test, y_test = sess.run(test_next_element)
except tf.errors.OutOfRangeError:
break
test_summary, test_loss, test_acc = sess.run([merged, loss, accuracy], feed_dict={x: x_test, y: y_test})
# 由于这里是全量测试,通过测试集多个batch的迭代,日志中每个step上有多个记录值
# 所以通过'每隔指定训练step进行一次测试集全量测试'的方式训练模型,不适合使用
# 'merge_all'的方式记录,可以通过下面手动记录的方式记录训练和测试过程中的loss
# 和acc
test_writer.add_summary(test_summary, step)
test_losses.append(test_loss)
test_accs.append(test_acc)
# 每隔指定step记录一次训练数据(loss, acc)
train_loss = np.mean(train_losses)
train_acc = np.mean(train_accs)
test_loss = np.mean(test_losses)
test_acc = np.mean(test_accs)
# 保存检查点,保存测试数据集上准确率最高的前max_to_keep个检查点
# 只有在保存时使用了global_step参数,才可能使max_to_keep生效
# 否则只能保存一个模型,并且tf.train.latest_checkpoint(checkpoint_dir)
# 也会失效,应为无法给检查点添加step信息。
if test_acc > best_acc:
saver.save(sess, checkpoint_dir, globa_step)
# 记录自定义数据
# 参考:
# https://blog.csdn.net/encodets/article/details/54172807
# https://stackoverflow.com/questions/37902705/how-to-manually-create-a-tf-summary
train_manually_summary = tf.summary.Summary(
value=[tf.summary.Summary.Value(tag="train/loss", simple_value=train_loss),
tf.summary.Summary.Value(tag="train/acc", simple_value=train_acc)])
train_writer.add_summary(train_manually_summary, step)
test_manually_summary = tf.summary.Summary(value=[
tf.summary.Summary.Value(tag="test/loss", simple_value=test_loss),
tf.summary.Summary.Value(tag="test/acc", simple_value=test_acc)])
test_writer.add_summary(test_manually_summary, step)
print("train step: %04d: loss: %.3f, acc: %.3f" % (step, train_loss, train_acc))
print("test step: %04d: loss: %.3f, acc: %.3f" % (step, test_loss, test_acc))
print("-" * 50)
train_losses.clear()
train_accs.clear()
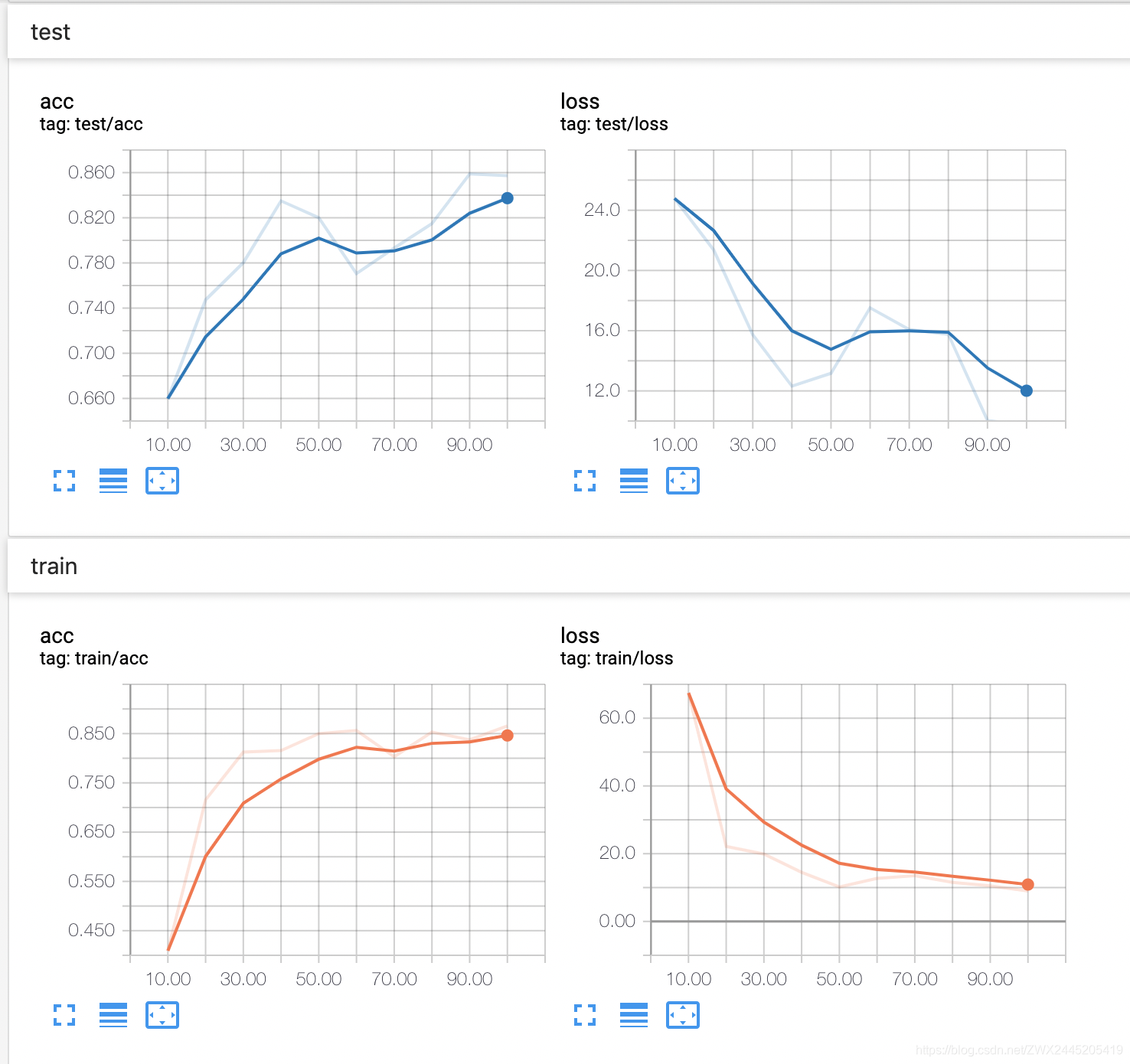
训练过程
/Users/zhangwenxiang02/.virtualenvs/tensorflow/bin/python3.6 /Users/zhangwenxiang02/PycharmProjects/tensorlfow-template/example.py
2019-04-07 12:09:44.559503: I tensorflow/core/platform/cpu_feature_guard.cc:141] Your CPU supports instructions that this TensorFlow binary was not compiled to use: AVX2 FMA
train step: 0010: loss: 67.434, acc: 0.409
test step: 0010: loss: 24.783, acc: 0.660
--------------------------------------------------
train step: 0020: loss: 22.145, acc: 0.716
test step: 0020: loss: 21.368, acc: 0.747
--------------------------------------------------
train step: 0030: loss: 19.883, acc: 0.812
test step: 0030: loss: 15.735, acc: 0.780
--------------------------------------------------
train step: 0040: loss: 14.510, acc: 0.816
test step: 0040: loss: 12.320, acc: 0.835
--------------------------------------------------
train step: 0050: loss: 10.199, acc: 0.850
test step: 0050: loss: 13.167, acc: 0.820
--------------------------------------------------
train step: 0060: loss: 12.723, acc: 0.856
test step: 0060: loss: 17.521, acc: 0.771
--------------------------------------------------
train step: 0070: loss: 13.484, acc: 0.803
test step: 0070: loss: 16.078, acc: 0.793
--------------------------------------------------
train step: 0080: loss: 11.521, acc: 0.853
test step: 0080: loss: 15.756, acc: 0.815
--------------------------------------------------
train step: 0090: loss: 10.491, acc: 0.837
test step: 0090: loss: 10.032, acc: 0.859
--------------------------------------------------
train step: 0100: loss: 8.986, acc: 0.866
test step: 0100: loss: 9.764, acc: 0.857
--------------------------------------------------
Process finished with exit code 0
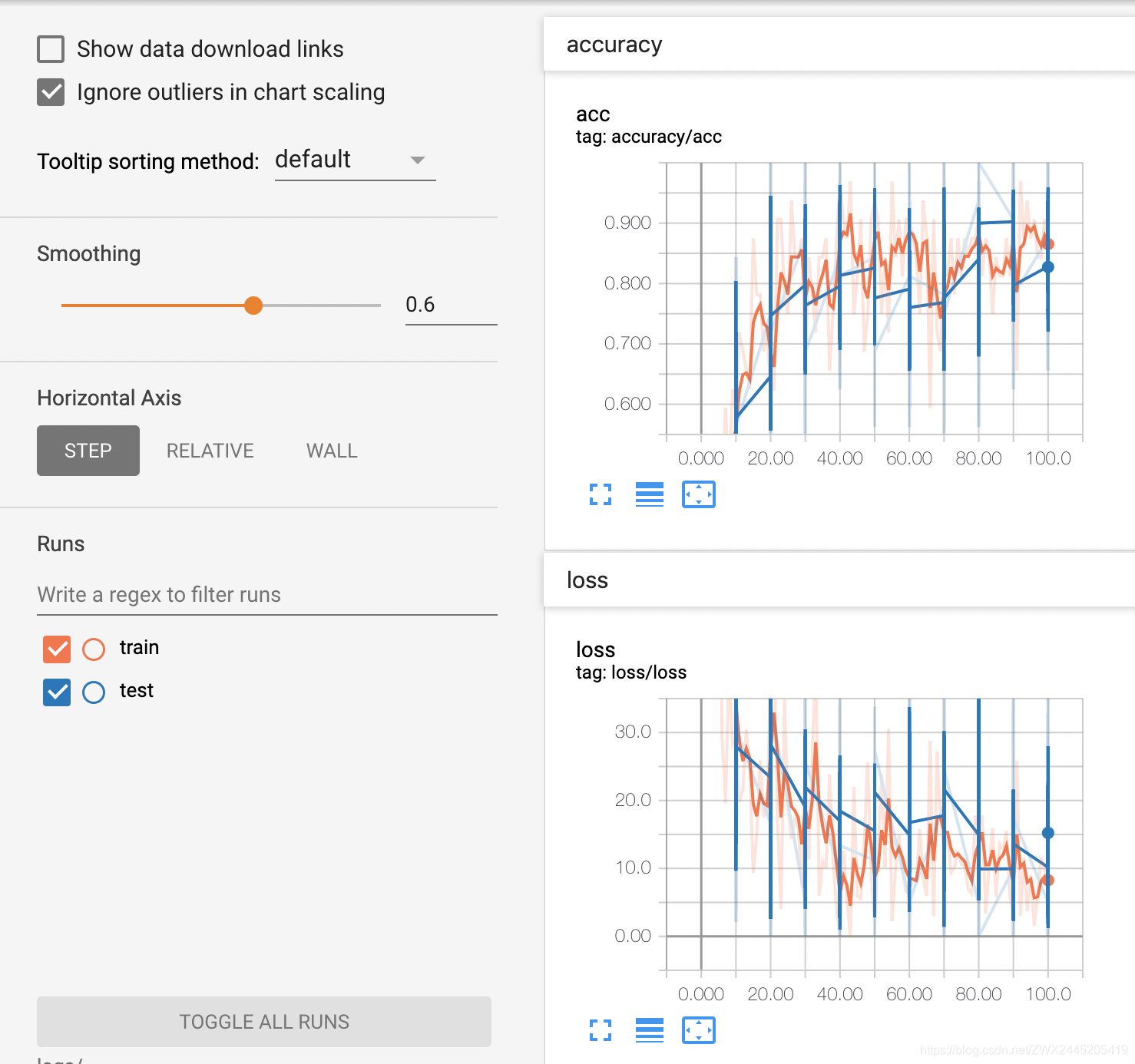
训练可视化
$ tensorboard --logdir=logs/ --host=127.0.0.1 --port=8088
通过tf.summary.merge_all()操作记录
通过自定义数据记录