创建idea工程






package test.Spark
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object WordCount {
def main(args: Array[String]): Unit = {
//alt+上箭头 向上拉取
//todo:1.创建sparkConf对象,设置appName和master的地址,local[2]表示本地运行2个线程
val sparkConf: SparkConf = new SparkConf().setAppName("wordCount").setMaster("local[2]")
//todo:2、创建sparkcontext上下文对象
val sc: SparkContext = new SparkContext(sparkConf)
//todo:3、读取数据文件
val fileRDD: RDD[String] = sc.textFile("D:\\words.txt")
//todo:4、切分文件中的每一行,返回文件所有单词
val wordsRDD: RDD[String] = fileRDD.flatMap(_.split(" "))
//todo:5、每个单词记为1,(单词,1)
val wordAndOneRDD: RDD[(String, Int)] = wordsRDD.map((_, 1))
//todo:6、相同单词出现的次数累加
val result: RDD[(String, Int)] = wordAndOneRDD.reduceByKey(_+_)
//todo:按照单词出现的次数降序排列
val sortResult: RDD[(String, Int)] = result.sortBy(_._2,false)
//todo:7、收集结果数据
val finalResult: Array[(String, Int)] = sortResult.collect()
//todo:8、打印结果数据
finalResult.foreach(x=>println(x))
//todo:9、关闭sc
sc.stop()
}
}


第二种:和hdfs整合
package test.Spark
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object WordCount_Online {
def main(args: Array[String]): Unit = {
//alt+上箭头 向上拉取
//todo:1.创建sparkConf对象,设置appName
val sparkConf: SparkConf = new SparkConf().setAppName("WordCount_Online")
//todo:2、创建sparkcontext上下文对象
val sc: SparkContext = new SparkContext(sparkConf)
//todo:3、读取数据文件,hdfs传参
val fileRDD: RDD[String] = sc.textFile(args(0))
//todo:4、切分文件中的每一行,返回文件所有单词
val wordsRDD: RDD[String] = fileRDD.flatMap(_.split(" "))
//todo:5、每个单词记为1,(单词,1)
val wordAndOneRDD: RDD[(String, Int)] = wordsRDD.map((_, 1))
//todo:6、相同单词出现的次数累加
val result: RDD[(String, Int)] = wordAndOneRDD.reduceByKey(_+_)
//todo:按照单词出现的次数降序排列
val sortResult: RDD[(String, Int)] = result.sortBy(_._2,false)
//todo:7、收集结果数据,保存在hdfs,不用打印输出
sortResult.saveAsTextFile(args(1))
//todo:8、关闭sc
sc.stop()
}
}
进行打包


上传jar包

提交脚本任务

确保你的/ 路径下有 words.txt
spark-submit --class test.Spark.WordCount_Online --master
spark://node04:7077 --executor-memory 1G --total-executor-cores 2
/root/spark-1.0-SNAPSHOT.jar /words.txt /out100
test.Spark 包名
WordCount_Online 类名
node04 master 节点名
–executor-memory 1G 计算任务时给的资源
–total-executor-cores 2 多少核
/root/spark-1.0-SNAPSHOT.jar jar包路径
/words.txt hdfs文件的路径
/out100 生成文件的路径
查看结果

看里面有一些什么

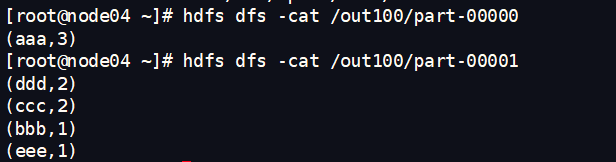
ok,全部搞定,累死我了,一口气写完的
spark-submit’\t’ --class test.Spark.WordCount_Online ‘\t’ --master
spark://node04:7077’\t’ --executor-memory 1G ‘\t’–total-executor-cores 2’\t’
/root/spark-1.0-SNAPSHOT.jar’\t’ /words.txt ‘\t’/out100
这个东西先粘贴到文档上面,然后尽量弄到一行执行 空格的位置我给你们’\t’
用到一行,记得改好了…溜溜球