1.1Hadoop产生的背景
1. HADOOP最早起源于Nutch。Nutch的设计目标是构建一个大型的全网搜索引擎,包括网页抓取、索引、查询等功能,但随着抓取网页数量的增加,遇到了严重的可扩展性问,如何解决数十亿网页的存储和索引问题。
2. 2003年开始谷歌陆续发表的三篇论文为该问题提供了可行的解决方案。
- 分布式文件系统(GFS),可用于处理海量网页的存储
- 分布式计算框架MAPREDUCE,可用于处理海量网页的索引计算问题。
- BigTable 数据库:OLTP 联机事务处理 Online Transaction Processing 增删改,OLAP 联机分析处理 Online Analysis Processing 查询,真正的作用:提供了一种可以在超大数据集中进行实时CRUD操作的功能
3.Nutch的开发人员完成了相应的开源实现HDFS和MAPREDUCE,并从Nutch中剥离成为独立项目HADOOP,到2008年1月,HADOOP成为Apache顶级项目,迎来了它的快速发展期。
1.2 Hadoop的优势
1)高可靠性:因为Hadoop假设计算元素和存储会出现故障,因为它维护多个工作数据副本,在出现故障时可以对失败的节点重新分布处理
2)高扩展性:在集群间分配任务数据,可方便的扩展数以千计的节点。
3)高效性:在MapReduce的思想下,Hadoop是并行工作的,以加快任务处理速度。
4)高容错性:自动保存多份副本数据,并且能够自动将失败的任务重新分配。
1.3 Hadoop组成
1)Hadoop HDFS:一个高可靠、高吞吐量的分布式文件系统。
2)Hadoop MapReduce:一个分布式的离线并行计算框架。
3)Hadoop YARN:作业调度与集群资源管理的框架。
4)Hadoop Common:支持其他模块的工具模块。
1.4.1 YARN架构概述
1)ResourceManager(rm): 处理客户端请求、启动/监控ApplicationMaster、监控NodeManager、资源分配与调度;
2)NodeManager(nm):单个节点上的资源管理、处理来自ResourceManager的命令、处理来自ApplicationMaster的命令;
3)ApplicationMaster:数据切分、为应用程序申请资源,并分配给内部任务、任务监控与容错。
4)Container:对任务运行环境的抽象,封装了CPU、内存等多维资源以及环境变量、启动命令等任务运行相关的信息。
1.4.2 MapReduce架构概述 MapReduce将计算过程分为两个阶段:Map和Reduce
1)Map阶段并行处理输入数据
2)Reduce阶段对Map结果进行汇总
1.4 大数据技术生态体系图
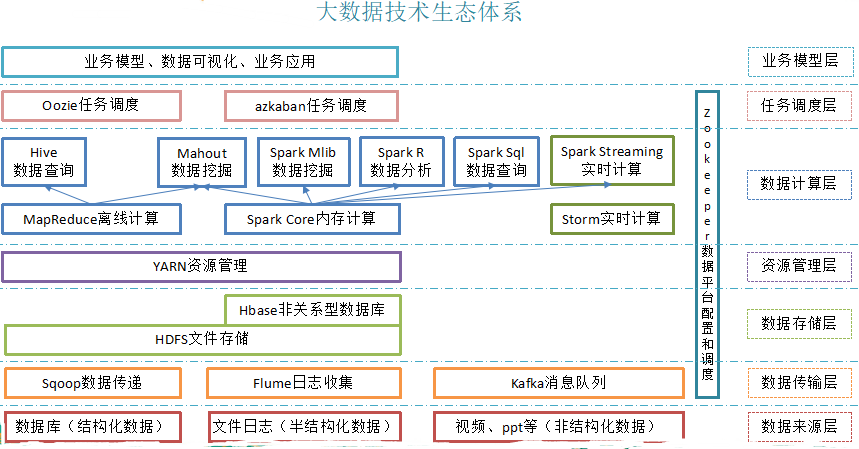
Hadoop生态圈重点组件:
HDFS:Hadoop的分布式文件存储系统。
MapReduce:Hadoop的分布式程序运算框架,也可以叫做一种编程模型。
Hive:基于Hadoop的类SQL数据仓库工具
Hbase:基于Hadoop的列式分布式NoSQL数据库
ZooKeeper:分布式协调服务组件
Mahout:基于MapReduce/Flink/Spark等分布式运算框架的机器学习算法库
Oozie/Azkaban:工作流调度引擎
Sqoop:数据迁入迁出工具
Flume:日志采集工具
获取数据的三种方式
1、自己公司收集的数据--日志 或者 数据库中的数据
2、有一些数据可以通过爬虫从网络中进行爬取
3、从第三方机构购买
主要内容如下
====================================================================
1> 集群搭建
a.完全分布式
b.高可用模式
2>集群维护
a.新节点的加入
b.下线旧节点
c.快照管理
d.配额管理
e.hadoop启动分析
f. namenode/datanode 作用
g.yarn 日志webui查看配置
h.yarn历史服务器配置
3>hdfs
a.文件写入/读取过程分析
b.hdfs启动
c.编辑日志/镜像文件
d.hdfs的增删改查
e.文件压缩
f.hadoop序列化
g. hadoop 序列文件
h. hdfs 常用命令
4> mapreduce
a.maptask 流程解析
b.wordcount
c.mapreduce 常用格式
d.mapreduce 链式编程
e.mapreduce 数据倾斜
f.mapreduce 排序
g.mapreduce 二次排序
h.mapreduce partitioner combiner
i.mapreduce 连接操作(map端join, reduce端join)