需要使用SQLContext对象来调用sql()方法,Spark SQL对数据查询分为两个分支SQLContext和HiveContext,HiveContext继承了SQLContext
Spark SQL提供了一个名为DataFrame的抽象编程模型,DataFrame是由SchemeRDD发展而来的
创建DataFrame对象
Parquet文件
load()方法将HDFS上的格式化文件转换为DataFrame,默认导入的文件格式是Parquet
sqlContext.read.load("/data/users.parquet")
JSON文件
format指定文件格式
val data=sqlContext.read.format("json").load("/data/MealRatings.json")
或者直接调用json方法
val data=sqlContext.read.json("/data/MealRatings.json")
外部数据库创建DataFrame
val url="jdbc:mysql://192.168.128.130/text"
val jdbcDF=sqlContext.read.format("jdbc").option(map("user"->url,"password"->"root")).load()
RDD创建DataFrame
利用反射机制推断RDD模式,使用这种方式需要定义一个case class,因为只有case class才能被spark隐式地转换为DataFrame
case class Users(name:Int,sex:String,age:Int,job:Int,addr:String)
val data=sc.textFile("/data/users.dat").map(_.split("::"))
val users=data.map(x=>(x(0).trim.toInt,x(1),x(2).trim.toInt,x(3).trim.toInt,x(4))).toDF()
DateFrame查看数据
数据准备:
case class Movie(movieId:Int,title:String,Genres:String)
val data=sc.textFile("/data/movies.dat").map(_.split("::"))
val movies=data.map(m=>Movie(m(0).trim.toInt,m(1),m(2))).toDF()
printSchema打印数据模式
会打印出列的名称和模式

show查看数据
show默认是查看20行数据

first获取第一条数据
head(n)获取前n条数据
take(n)获取前n条数据
takeAsList(n)获取前n条数据,并以List的形式展现

collect/collectAsList获取所有数据
collect返回Array对象,collectAsList返回List对象
DataFrame查询操作
第一种将DataFrame注册成临时表,然后将通过SQL语句进行查询
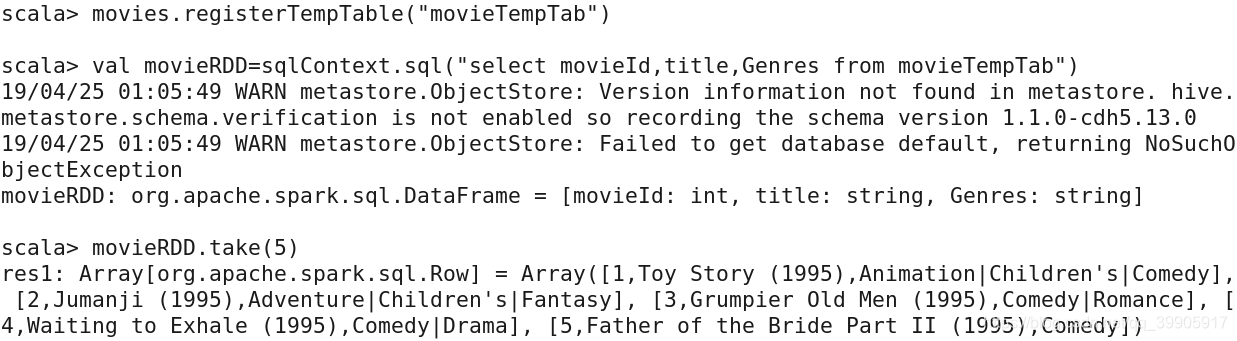
movies.registerTempTable("movieTempTab")
val movieRDD=sqlContext.sql("select movieId,title,Genres from movieTempTab")
movieRDD.take(5)
第二种是直接在DataFrame对象上进行查询,DataFrame的查询操作是懒操作
数据准备:
case class Rating(userId:Int,movieId:Int,rating:Int,timestamp:Long)
val ratingData=sc.textFile("/data/ratings.dat").map(_.split("::"))
val rating=ratingData.map(r=>Rating(r(0).trim.toInt,r(1).trim.toInt,r(2).trim.toInt,r(3).trim.toLong)).toDF()
case class User(userId:Int,gender:String,age:Int,occupation:Int,zip:String)
val userData=sc.textFile("/data/users.dat").map(_.split("::"))
val user=userData.map(u=>User(u(0).trim.toInt,u(1),u(2).trim.toInt,u(3).trim.toInt,u(4))).toDF()
where
参数中可以使用and和or,返回是DataFrame类型
val userwhere=user.where("gender='F' and age=18")
userwhere.show(3)

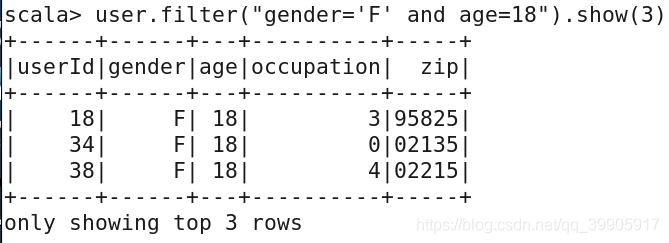
filter筛选数据
user.filter("gender='F' and age=18").show(3)
select获取指定字段值
user.select("userId","gender").show(3)

selectExpr对指定字段进行特殊处理
例如:为某个字段取别名,或者对某个字段的数据进行四舍五入
col/apply获取一个字段
并且返回类型是Column类型
val userCol=user.col("zip")
user.select(userCol).show(5)
limit获取前n条数据