1.Hadoop定义:
1)Hadoop是一个由Apache基金会所开发的分布式系统基础架构
2)主要解决,海量数据的存储和海量数据的计算问题。
3)Hadoop通常是指一个更广泛的概念——Hadoop生态圈。因为所有框架都是在Hadoop基础上建立的!
2.Hadoop发展历史:
Google是hadoop的思想之源(Google在大数据方面的三篇论文)GFS --->HDFS、Map-Reduce --->MR、BigTable --->Hbase!(非关系型数据库)
3.Hadoop三大发行版本:
三大版本:Apache、Cloudera、Hortonworks
1)Apache版本最原始(最基础)的版本,对于入门学习最好。2005年
2)Cloudera在大型互联网企业中用的较多。(收费!)2008年
比Apache Hadoop在兼容性,安全性,稳定性上有所增强。
3)Hortonworks文档较好。(收费!)2011年,后起之秀
可以支持在windows平台上运行
4.Hadoop的优势:
1)高可靠性:因为Hadoop假设计算元素和存储会出现故障(类似悲观锁),它就维护多个工作数据副本,在出现故障时可以对失败的节点重新分布处理。
2)高扩展性:在集群间分配任务数据,可方便的扩展节点(可以动态维护更新节点)。
3)高效性:在MapReduce的思想下,Hadoop是并行工作(真正理想下的状态),以加快任务处理速度。
5.Hadoop组成:
1)Hadoop HDFS:一个高可靠、高吞吐量的分布式文件系统。(用于存储数据)
- NameNode(nn):存储文件的元数据(描述数据特征的信息)。
- DataNode(dn):在本地文件系统存储文件块数据,以及块数据的校验和。(实际的数据信息)
- Secondary NameNode(2nn):用来监控HDFS状态的辅助后台程序,每隔一段时间获取HDFS元数据的快照。(校验元数据)
2)Hadoop MapReduce:一个分布式的离线并行计算框架。(用于离线处理计算)
- MapReduce将计算过程分为两个阶段:Map(映射,分割)和Reduce(聚合)
- Map阶段并行处理输入数据
- Reduce阶段对Map结果进行汇总
3)Hadoop YARN:作业调度与集群资源管理的框架。(用于资源调度)
- ResourceManager(rm):处理客户端请求、启动/监控ApplicationMaster、监控NodeManager、资源分配与调度;(总调度)
- NodeManager(nm):单个节点上的资源管理、处理来自ResourceManager的命令、处理来自ApplicationMaster的命令;
- ApplicationMaster:数据切分、为应用程序申请资源,并分配给内部任务、任务监控与容错。
- Container(容器):对任务运行环境的抽象,封装了CPU、内存等多维资源以及环境变量、启动命令等任务运行相关的信息。(类似于docker云计算这种)

4)Hadoop Common:支持其他模块的工具模块。(辅助工具/工具模块)
基于推荐系统的例子图:

6.搭建hadoop的本地分布式
熟悉linux : useradd love , passwd love , su love , :wq! , / :wq #用户创建 , vim的使用!
设置为NAT模式,因为只在内网,不涉及外网。
克隆虚拟机,必须克隆!
修改主机名!sudo vim /etc/hostname ,重启reboot
网络节点进行通信!sduo vim /etc/hosts 192.168.91.139 master
创建文件夹:sudo chown pyvip:pyvip model/ software/ #赋予用户文件权限
tar -zxvf jdk... -C /opt/model/ #解压文件
sudo vim /etc/profile #配置jdk环境变量
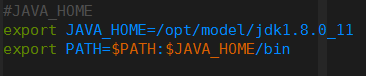
source /etc/profile #重启环境变量
java -version #查看是否成功
安装hadoop:
tar -zxvf jdk... -C /opt/model/ #解压文件
sudo vim /etc/profile #配置hadoop环境变量
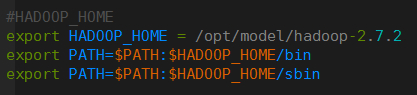
确认成功 hadoop!
#vim /opt/model/hadoop-2.7.2/etc/hadoop/hadoop-env.sh 修改JAVA_HOME路径!
大功告成,配置完了!
7.本地运行的hadoop案例
grep案例:
pyvip@master:/opt/model/hadoop-2.7.2$ mkdir input #创建输入文件
cp etc/hadoop/*.xml input/ #给输入文件夹拷贝
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar grep input/ output 'dfs[a-z.]+'
# 运行hadoop的jar文件 jar文件路径 命令 输入路径 输出路径 过滤条件
#统计出符合过滤条件的单词进行输出wordcount案例:
mkdir wcinput #创建文件夹
touch wc.input vi wc.input cd .. #写文件
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar wordcount wcinput/ wcoutput
#启动hadoop的jar程序 wordcount命令 输入文件夹 输出文件夹
8.伪分布式运行hadoop案例(Pseudo-Distributed Mode)
(1)启动HDFS并运行MapReduce 程序
配置集群:
etc/hadoop目录下:
(a)配置javahome:hadoop-env.sh export JAVA_HOME=/opt/module/jdk1.8.0_144
(b)配置:core-site.xml
<!-- 指定HDFS中NameNode的地址 /主机名 hadoop101 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop101:9000</value>
</property>
<!-- 指定hadoop运行时产生文件的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/module/hadoop-2.7.2/data/tmp</value>
</property>
(c)配置:hdfs-site.xml
<!-- 指定HDFS副本的数量 默认是三个(意思是需要有三个副本主机来存储的)-->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>启动集群:
(a)格式化namenode(第一次启动时格式化,以后就不要总格式化)
bin/hdfs namenode -format
(b)启动namenode
sbin/hadoop-daemon.sh start namenode #stop停止
(c)启动datanode
sbin/hadoop-daemon.sh start datanode #jsp查看下查看集群:
(a)查看是否启动成功
jps #必须配置jdk的环境变量才可以!
(b)查看产生的log日志
当前目录:/opt/module/hadoop-2.7.2/logs
cat hadoop-atguigu-datanode-hadoop101.log
(c)web端查看HDFS文件系统
http://192.168.1.101:50070 #主机号/IP地址都可以!操作集群:
(a)在hdfs文件系统上创建一个input文件夹
bin/hdfs dfs -mkdir -p /user/atguigu/input
(b)将测试文件内容上传到文件系统上
bin/hdfs dfs -put wcinput/wc.input /user/atguigu/input/
(c)查看上传的文件是否正确
bin/hdfs dfs -cat /user/atguigu/ input/wc.input
(d)运行mapreduce程序
bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar wordcount /user/atguigu/input/ /user/atguigu/output
(e)查看输出结果
命令行查看:bin/hdfs dfs -cat /user/atguigu/output/p*
浏览器查看:/user/master/output
(f)将测试文件内容下载到本地
hadoop fs -get /user/atguigu/output/part-r-00000 ./wcoutput/
#把atguig下的uoutput结果下载到wcoutput里面
(g)删除输出结果
hdfs dfs -rmr /user/atguigu/output
#注意bin都可不加,都可使用!!!!!!