数组操作
ndarray对象内部机制概要
numpy的ndarray功能很强大因为其内部组成足够复杂,包括
(1)一个指向数组的内存指针
(2)数据类型dtype
(3)一个表示数据形状的元祖,使用shape属性可以调用
(4)一个跨度元祖,这个是内部机制的关键,使用strides属性可以获取。


3×4×5的一个多维数组,其跨度为(160,40, 8)。
numpy数据类型体系

numpy的数据类型使用dtype属性可以获取,比如获取到整数、布尔型和浮点数。但是以浮点数为例,浮点数的类型有多种,每一种进行判断是很复杂的工作。numpy中提供了dtype的超类,比如np.integer和np.floating,可以与np.issubdtype方法结合使用,

使用dtype的mro方法查看所有父类,

数组高级操作
1)数组重塑
reshape方法
数组重塑使用reshape方法,传入的是一个新的表示形状的元组。、
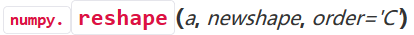
对参数C的解读如下,

一般order参数默认“C"即可。
基本使用,
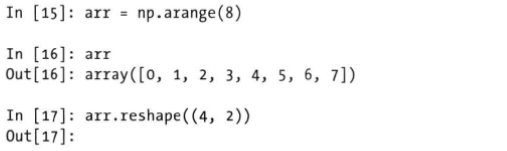



flatten和ravel方法
reshape将多维数组转换为一维数组的运算称为扁平化(flattening)或者散开(raveling)。这个过程使用flatten方法或者ravel方法。



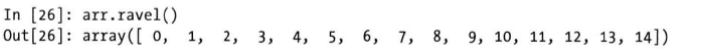
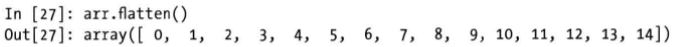
两个方法得到的效果是一样的,区别在于ravel方法在原数据上改动,不产生源数据的副本;而flatten方法产生的是源数据的副本。
2)C和Fortan顺序
numpy支持使用order参数对数据在内存中的布局进行控制。默认情况下,order参数值为”C",表示按照行的优先顺序进行创建,对于一个二维数组而言,一行中相邻的元素被存放在内存中相邻的位置。如果设置order参数的值为“F”,则是以列的优先顺序进行排列,每列中相邻的元素在内存中位置相邻。

当数组是更高维度的数组时,重塑过程就比较难理解,掌握C和Fortran的重塑顺序即可。
| order参数值 | 重塑顺序 |
|---|---|
| C/行优先顺序 | 先经过更高的维度,即n维数组(n>2),其轴[0 , n-1]被处理的顺序依次为 n-1, n-2, n-3, ……,1, 0。 |
| Fortran/列优先顺序 | 同样是上方的n维数组,轴的处理顺序 0,1,2……,n-1。 |
数组的拆分与合并
1)数组合并—concatenate、vstack、hstack方法
数组的合并可以使用numpy的concatenate方法,
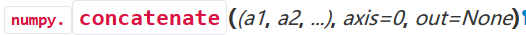
相关参数在官方文档中的定义,


更简便的还有hstack方法和vstack方法,


分别是水平拼接和竖直拼接。



相似的还有row_stack方法和column_stack方法,rowstack与vstack等效,都是在竖直方向(列方向)上对数组进行合并;column_stack与hstack是在水平方向(行方向)对数组合并,但是二者有一定的差异。官方文档给的例子进行说明,

2)拆分—split方法
数组的拆分使用split方法,
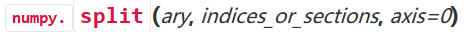
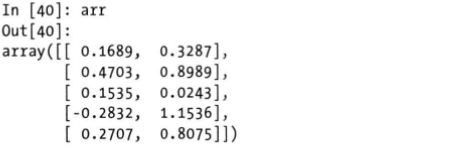
返回值类型是列表,每个元素是拆分得到的数组,


3)堆叠辅助类—r_方法和c_方法
功能与合并的方法相似,单列出来的原因是辅助类可以实现对数组的切片进行合并,使用的是numpy的r_方法和c_方法,这两个方法的使用形式也比较特殊,用的不是圆括号,而是方括号。两个方法分别形成的是新的行和列。


对切片翻译为数组并进行合并,
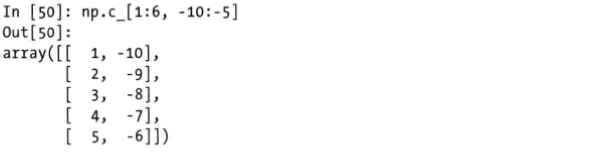
元素的重复操作—repeat和tile方法
1)repeat方法
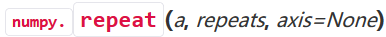
相应的参数解读如下,

最重要的是repeats参数,
一维数组的重复较为简单,


多维数组的重复需要指定axis参数,其余与一维数组一样


2)tile方法

tile方法返回的是原始数据的副本,相关参数如下,

如果reps参数传入的是整数,则会水平方向进行重复,

另一种形式传入的是元组,


对于二维数组而言,元组第一个元素是竖直方向重复次数,第二个元素是水平方向重复次数。
与花式索引等价的函数—take和put方法
花式索引的等价函数有两个,分别是take方法和put方法,分别用于元素获取和元素插入,首先回顾一下花式索引的基本使用,

上面的代码取出arr中索引为7,1,2,6的四个元素。
1)take方法


首先是官方文档的两个例子进行说明,


axis参数的使用指定的是从哪个轴上进行取值,axis=0时,在与索引为0的轴方向取元素;axis=1时,在索引为1的轴方向取元素。

2)put方法
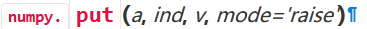

官方文档中的实例,put方法将元素放在数组的指定位置。mode参数为“clip”时,大过数组本身长度的索引值会被放在最后一个元素的位置上。
