pandas数据对象进阶
层次化索引是Index类的子类 MultiIndex类,实际上就是有两个以上级别的索引。
1. Series层次化索引
Series创建层次化索引
创建Series对象时,可以向index参数传递二维数组进行层次化索引的构建,

获取Series层次化索引
内层索引可以视为外层索引的子标签。

使用对象的index属性获取现在的索引,展现的形式很像是Python的zip方法处理过的两个列表后得到的结果。
层次化索引中,可以仅使用外层索引获取数据,

使用Series层次化索引
MultiIndex的情况下,使用外层的标签,得到其所有子标签。不过上方的代码只是从Series中取出其中一个外层索引,一次性取出多个外层索引的方式有两种,

在内层索引中进行筛选,

层次化索引使Series与DataFrame相互转换
1)unstack方法
通过unstack方法可以将其转换为一个Dataframe,

外层索引还是索引,内层索引变为Dataframe的列,生成的DataFrame的列是所有的内层索引的并集,包含了内层索引所有的值,如果外层索引不存在某个内层索引,会使用NaN来进行填充。
2)stack方法
stack方法是unstack方法的逆运算,这两个方法以后会详细讲解,

2. DataFrame层次化索引
因为Dataframe存在两个轴,所以在每个轴上都能存在层次索引。
DataFrame创建层次化索引
通过在创建时向index参数和columns参数中传入二维列表,可以创建层次化的行索引和列索引,


同样的可以通过index和columns的names属性给行和列命名,此时可以给外层、内层分别命名,但是命名时注意顺序,

DataFrame行列索引操作
通过行和列的外层标签取出其内层的子标签,

3. 重排分级次序
层次化索引的层次重排
创建完Series或者Dataframe对象后,重新调整某条轴上各级别的顺序,或者根据指定级别上的值对数据进行排序使用到的是swaplevel方法,
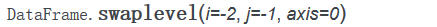
该方法接收的是Series或者Dataframe的任意两个已存在的索引的级别编号或者名称。

假设现在要交换index层级 key1和key2的级别关系,即让 key2变成外层索引,key1变为内层索引,

上面的代码等价于
frame.swaplevel( 0, 1, axis=0 )
其中 0是外层索引,1是内层索引,axis=0是对index进行交换。
层次化索引指定层级的排序
根据单个级别中的值进行排序使用的是sortlevel方法,swaplevel和sortlevel方法常常一起使用得到的最终结果是有序的,
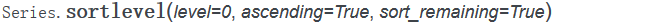

具体使用演示,


根据级别汇总统计
MultiIndex下的sum方法的使用,无论是Series还是Dataframe,sum方法都有一个level参数,这个参数用于指定求和的级别。

在“key2”这个级别上进行汇总统计,

axis=0,默认对行索引方向进行求和。axis参数为1时,对列索引方向进行求和,

已存在的Series和DataFrame构建和取消层次索引
在一般的Series或者Dataframe中,设置索引和取消索引使用的是 set_index方法和 reset_index方法,设置MultiIndex使用的同样是这两个方法。
1)set_index方法


一般创建单层索引的Dataframe在调用set_index方法时的形式为 ,
set_index( 'column_name' , inplace=True)
设置多层索引只需要将被设置为索引的几个列名以列表的形式传入即可。设置为外层索引的列在前面。
2)reset_index方法
reset_index方法也可以将多层索引一起删除,

