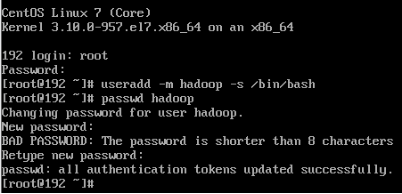
1、创建haddop用户,并设置密码
useradd -m hadoop -s /bin/bash
passwd hadoop
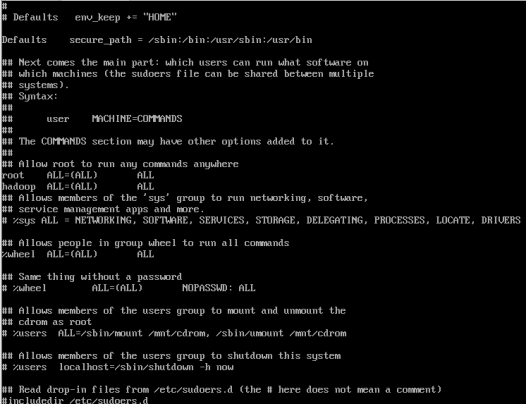
2、为hadoop用户添加管理员权限
visudo
找到 root ALL=(ALL) ALL 并在下面添加
hadoop ALL=(ALL) ALL
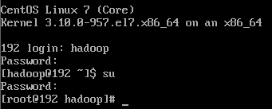
3、退出当前登陆并登陆hadoop用户
exit
4、准备工作
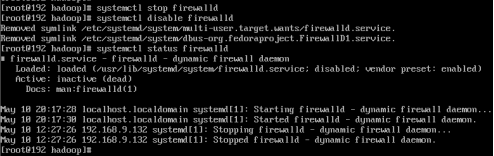
(1) 关闭防火墙
systemctl stop firewalld
systemctl disable firewalld
systemctl status firewalld
vi /etc/sysconfig/selinux
设置SELINUX=disabled
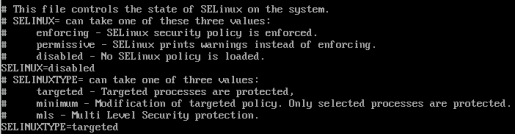
(2) 设置hostname
hostnamectl set-hostname huatec37
vi /etc/hosts
结尾添加 ip地址 huatec37

(3) 安装软件
ifconfig:yum install net-tools
自动补全:yum install bash
vim:yum -y install vim
wget:yum -y install wget
hadoop安装包: wget
http://mirrors.hust.edu.cn/apache/hadoop/core/hadoop-2.7.6/hadoop-2.7.6.tar.gz
(先进入目录 /usr/local 再执行命令)
ssh: sudo yum install openssh-clients
sudo yum install openssh-server
测试命令是否可用,输入yes和密码
ssh localhost
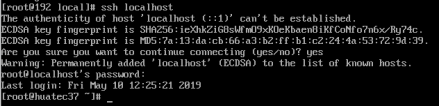
配置ssh免密登陆
exit # 退出刚才的 ssh localhost
cd ~/.ssh/ # 若没有该目录,请先执行一次ssh localhost
ssh-keygen -t rsa # 会有提示,都按回车就可以
cat id_rsa.pub >> authorized_keys # 加入授权
chmod 600 ./authorized_keys # 修改文件权限
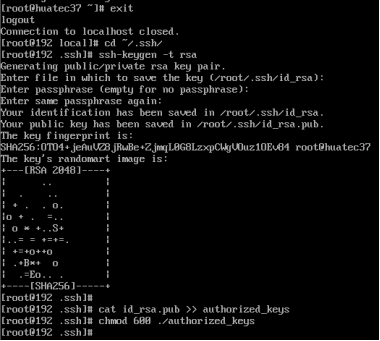
再次输入ssh localhost ,若成功则不需要密码直接登陆
5、安装JAVA
sudo yum install java-1.7.0-openjdk java-1.7.0-openjdk-devel
默认安装目录在 /usr/lib/jvm/java-1.7.0-openjdk
配置JAVA_HOME环境变量
vim ~/.bashrc
在最后一行添加
export JAVA_HOME=/usr/lib/jvm/java-1.7.0-openjdk
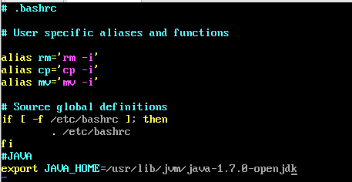
使环境变量生效
source ~/.bashrc
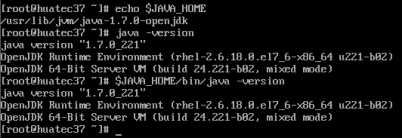
检验设置是否正确,如果正确,则java -version与$JAVA_HOME/bin/java -version 输出结果一样
echo $JAVA_HOME
java -version
$JAVA_HOME/bin/java -version
6、安装hadoop
进入目录 /usr/local ,解压hadoop压缩包
tar -zxvf hadoop-2.7.6.tar.gz
将hadoop-2.7.6改名为hadoop
mv hadoop-2.7.6 hadoop
修改文件权限
sudo chown -R hadoop:hadoop ./hadoop
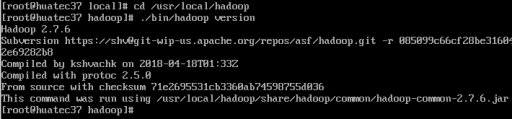
检查hadoop是否可用
cd /usr/local/hadoop
./bin/hadoop version
6、hadoop伪分布式配置
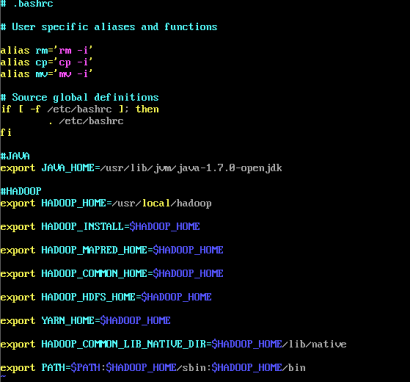
设置hadoop环境变量
vim ~/.bashrc
在结尾添加
export HADOOP_HOME=/usr/local/hadoop
export HADOOP_INSTALL=$HADOOP_HOME
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
使配置生效
source ~/.bashrc
进入目录 /usr/local/hadoop/etc/hadoop
cd /usr/local/hadoop/etc/hadoop
修改配置文件 core-site.xml 和 hdfs-site.xml
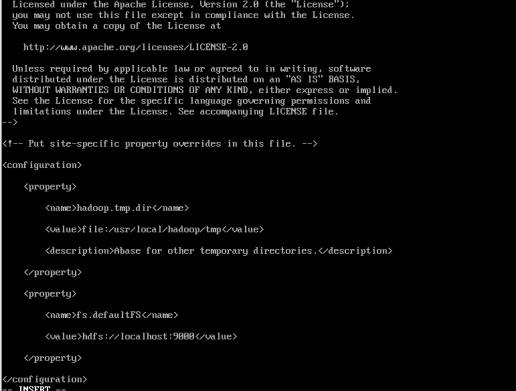
core-site.xml
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/hadoop/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
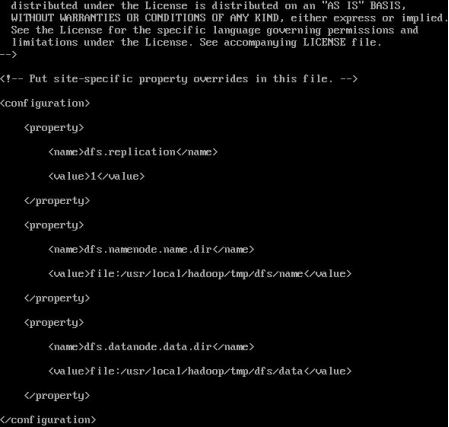
hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/data</value>
</property>
</configuration>
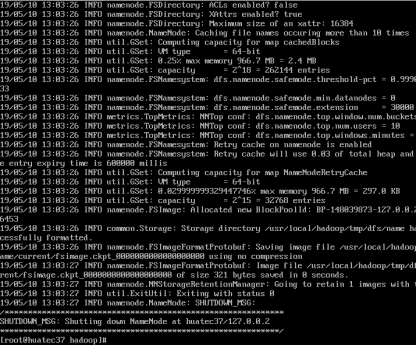
执行NameNode
hdfs namenode -format
成功的话,会看到 “successfully formatted” 和 “Exitting with status 0” 的提示,若为 “Exitting with status 1” 则是出错。
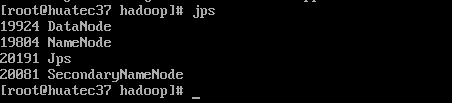
打开NameNode和DataNode守护进程
start-dfs.sh
判断是否打开成功
jps
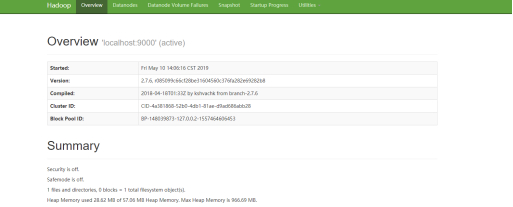
访问192.168.9.135:50070
7、启动yarn
修改配置文件mapred-site.xml和yarn-site.xml
将mapred-site.xml.template 重命名为mapred-site.xml
mv mapred-site.xml.template mapred-site.xml
mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
启动yarn
start-dfs.sh
查看后台进程
jps
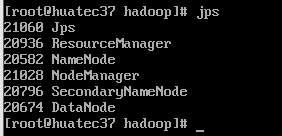
访问192.168.9.135:8088
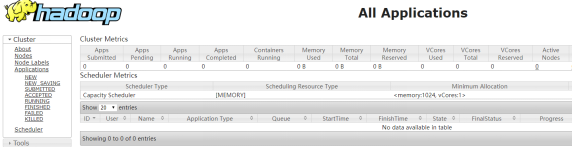
参考http://dblab.xmu.edu.cn/blog/install-hadoop-in-centos/