追踪XmlBeanFactory
XmlBeanFactory的创建需要一个Resource参数
创建ClassPathResource
下图是Resource类相关类图
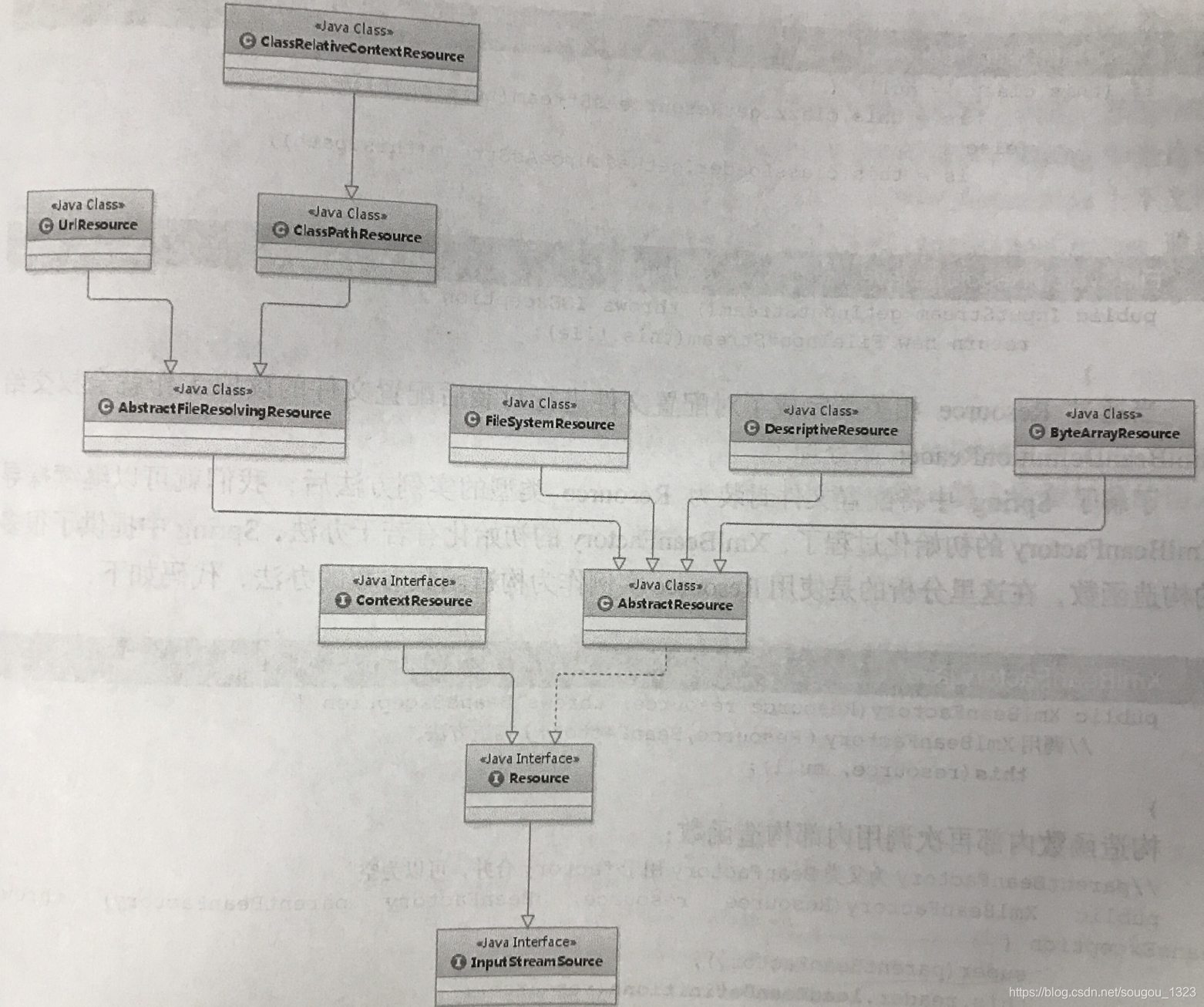
我们从这句代码出发
new ClassPathResource("beanFactoryTest.xml")
会来到ClassPathResource类的构造函数
public ClassPathResource(String path) {
this(path, (ClassLoader) null);
}
会调用另一个构造函数
public ClassPathResource(String path, ClassLoader classLoader) {
Assert.notNull(path, "Path must not be null");
//对路径规范化
String pathToUse = StringUtils.cleanPath(path);
if (pathToUse.startsWith("/")) {
pathToUse = pathToUse.substring(1);
}
this.path = pathToUse;
this.classLoader = (classLoader != null ? classLoader : ClassUtils.getDefaultClassLoader());
//执行完毕后后给ClassPathResource类的两个属性赋值
//path. classLoader
}
跳进cleanPath方法
/**
* 通过抑制“path/..”和内部简单的圆点之类的序列来规范化路径
* 该结果便于路径比较。对于其他用途,
* 注意,Windows分隔符("\")被简单的斜杠替换。
* @param 路径初始路径
* @return 规范化路径
*/
/**
* Normalize the path by suppressing sequences like "path/.." and
* inner simple dots.
* <p>The result is convenient for path comparison. For other uses,
* notice that Windows separators ("\") are replaced by simple slashes.
* @param path the original path
* @return the normalized path
*/
public static String cleanPath(String path) {
if (path == null) {
return null;
}
//一些和文件路径有关的常量定义
//WINDOWS_FOLDER_SEPARATOR = "\\"
//FOLDER_SEPARATOR = "/"
//TOP_PATH = ".."
//CURRENT_PATH = "."
//EXTENSION_SEPARATOR = '.'
//将路径中'\\'替换为‘/',主要考虑Windows和Linux文件路径符号不同
String pathToUse = replace(path, WINDOWS_FOLDER_SEPARATOR, FOLDER_SEPARATOR);
// Strip prefix from path to analyze, to not treat it as part of the
// first path element. This is necessary to correctly parse paths like
// "file:core/../core/io/Resource.class", where the ".." should just
// strip the first "core" directory while keeping the "file:" prefix.
int prefixIndex = pathToUse.indexOf(":");
String prefix = "";
//处理一些文件前缀。如"file:", "jndi:"等等
//如果路径中存在‘:',并且不包含‘/',提取前缀 prefix = 0~index(:)
// pathToUse = index(:)~end
//如果路径中存在‘:',并且包含‘/'prefix = ''
//如果不存在‘:',prefix = ''
if (prefixIndex != -1) {
prefix = pathToUse.substring(0, prefixIndex + 1);
if (prefix.contains("/")) {
prefix = "";
}
else {
pathToUse = pathToUse.substring(prefixIndex + 1);
}
}
//如果pathTouse以‘/'开始,将‘/'分给prefix
if (pathToUse.startsWith(FOLDER_SEPARATOR)) {
prefix = prefix + FOLDER_SEPARATOR;
pathToUse = pathToUse.substring(1);
}
//按照‘/’进行分解成一个个token
String[] pathArray = delimitedListToStringArray(pathToUse, FOLDER_SEPARATOR);
List<String> pathElements = new LinkedList<String>();
int tops = 0;
//记录'..'上一层出现的次数,忽略‘.'当前目录
for (int i = pathArray.length - 1; i >= 0; i--) {
String element = pathArray[i];
if (CURRENT_PATH.equals(element)) {
// Points to current directory - drop it.
}
else if (TOP_PATH.equals(element)) {
// Registering top path found.
tops++;
}
//用来抵消‘..'上一层
else {
if (tops > 0) {
// Merging path element with element corresponding to top path.
tops--;
}
else {
// Normal path element found.
pathElements.add(0, element);
}
}
}
// Remaining top paths need to be retained.
//将处理后的token存到链表中
for (int i = 0; i < tops; i++) {
pathElements.add(0, TOP_PATH);
}
//返回处理后的新path
return prefix + collectionToDelimitedString(pathElements, FOLDER_SEPARATOR);
}
代码有点长,简单的说就是对路径字符串进行规范化处理
总结一下,执行new ClassPathResource("beanFactoryTest.xml”)会创建一个ClassPathResource对象,初始化ClassPathResource类的两个属性,path和classLoader
private final String path;
private ClassLoader classLoader;
创建XmlBeanFactory
XmlBeanFactory继承自DefaultListableBeanFactory,下面是DefaultListableBeanFactory的类图

我们从下面的代码出发
BeanFactory bf = new XmlBeanFactory(new ClassPathResource("beanFactoryTest.xml"));
将会调用XmlBeanFactory的构造函数
public XmlBeanFactory(Resource resource) throws BeansException {
this(resource, null);
}
调用XmlBeanFactory另一个构造函数
private final XmlBeanDefinitionReader reader = new XmlBeanDefinitionReader(this);
public XmlBeanFactory(Resource resource, BeanFactory parentBeanFactory) throws BeansException {
super(parentBeanFactory);
this.reader.loadBeanDefinitions(resource);
}
调用了XmlBeanFactory父类DefaultListableBeanFactory的构造函数
public DefaultListableBeanFactory(BeanFactory parentBeanFactory) {
super(parentBeanFactory);
}
又调用了DefaultListableBeanFactory父类AbstractAutowireCapableBeanFactory的构造函数
public AbstractAutowireCapableBeanFactory(BeanFactory parentBeanFactory) {
this();
setParentBeanFactory(parentBeanFactory);
}
调用了AbstractAutowireCapableBeanFactory自身的空参构造函数
public AbstractAutowireCapableBeanFactory() {
super();
ignoreDependencyInterface(BeanNameAware.class);
ignoreDependencyInterface(BeanFactoryAware.class);
ignoreDependencyInterface(BeanClassLoaderAware.class);
//ignoreDependencyInterface忽略给定接口的自动装配功能
}
之后调用AbstractAutowireCapableBeanFactory父类AbstractBeanFactory的方法setParentBeanFactory,传入parentBeanFactory参数
@Override
public void setParentBeanFactory(BeanFactory parentBeanFactory) {
if (this.parentBeanFactory != null && this.parentBeanFactory != parentBeanFactory) {
throw new IllegalStateException("Already associated with parent BeanFactory: " + this.parentBeanFactory);
}
this.parentBeanFactory = parentBeanFactory;
}
回顾一下
我们调用XmlBeanFactory(resource, null)方法来创建XmlBeanFactory对象
构造参数中做了两件事:super(parentBeanFactory)和this.reader.loadBeanDefinitions(resource);
super(parentBeanFactory)调用了DefaultListableBeanFactory的构造函数,DefaultListableBeanFactory调用了AbstractAutowireCapableBeanFactory的构造函数,
AbstractAutowireCapableBeanFactory调用了自身的空参构造函数和AbstractBeanFactory的setParentBeanFactory方法,将BeanFactory parentBeanFactory作为参数传入,初始化
AbstractBeanFactory的parentBeanFactory属性。
下面我们来看第二件事做了什么
private final XmlBeanDefinitionReader reader = new XmlBeanDefinitionReader(this);
this.reader.loadBeanDefinitions(resource);
首先来看reader,是一个XmlBeanDefinitionReader类型
下面是XmlBeanDefinitionReader的类图
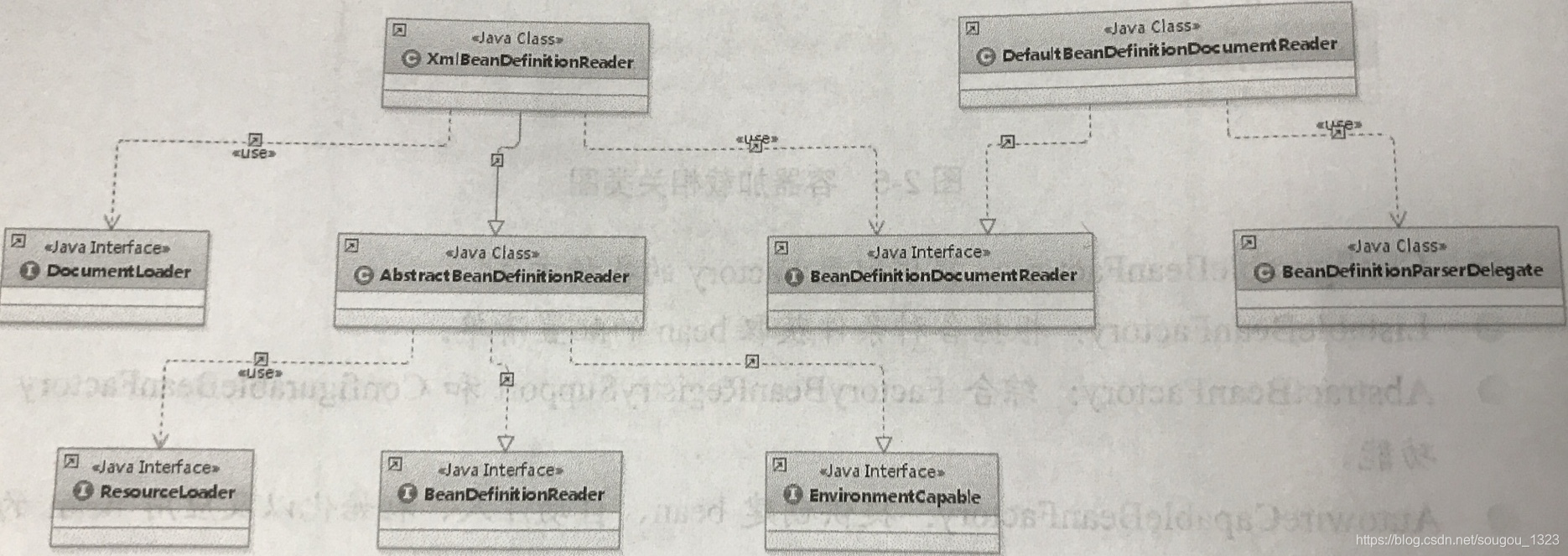
构造函数如下
public XmlBeanDefinitionReader(BeanDefinitionRegistry registry) {
//传进来的是beanFactory,但是这里的入参是BeanDefinitionRegistry,因为DefaultListableBeanFactory实现了BeanDefinitionRegistry接口。
super(registry);
}
调用了XmlBeanDefinitionReader父类AbstractBeanDefinitionReader的构造函数
protected AbstractBeanDefinitionReader(BeanDefinitionRegistry registry) {
Assert.notNull(registry, "BeanDefinitionRegistry must not be null");
this.registry = registry;
// Determine ResourceLoader to use.
if (this.registry instanceof ResourceLoader) {
this.resourceLoader = (ResourceLoader) this.registry;
}
else {
this.resourceLoader = new PathMatchingResourcePatternResolver();
}
// Inherit Environment if possible
if (this.registry instanceof EnvironmentCapable) {
this.environment = ((EnvironmentCapable) this.registry).getEnvironment();
}
else {
this.environment = new StandardEnvironment();
}
}
XmlBeanDefinitionReader创建完成后,我们回到
this.reader.loadBeanDefinitions(resource);
看看reader的loadBeanDefinitions方法都做了些什么
loadBeanDefinitions的定义:
@Override
public int loadBeanDefinitions(Resource resource) throws BeanDefinitionStoreException {
return loadBeanDefinitions(new EncodedResource(resource));
}
首先是创建一个EncodedResource(resource)对象
public EncodedResource(Resource resource) {
this(resource, null, null);
}
private EncodedResource(Resource resource, String encoding, Charset charset) {
super();
Assert.notNull(resource, "Resource must not be null");
this.resource = resource;
this.encoding = encoding;
this.charset = charset;
}
EncodedResource实现了InputStreamSource接口,对Resource的字符集和编码进行封装
//封装了Resource的字符集和编码。
public class EncodedResource implements InputStreamSource {
private final Resource resource;
private final String encoding;
private final Charset charset;
之后我们看loadBeanDefinitions(new EncodedResource(resource))
/**
* Load bean definitions from the specified XML file.
*
* @param encodedResource the resource descriptor for the XML file,
* allowing to specify an encoding to use for parsing the file
* @return the number of bean definitions found
* @throws BeanDefinitionStoreException in case of loading or parsing errors
*/
public int loadBeanDefinitions(EncodedResource encodedResource) throws BeanDefinitionStoreException {
Assert.notNull(encodedResource, "EncodedResource must not be null");
if (logger.isInfoEnabled()) {
logger.info("Loading XML bean definitions from " + encodedResource.getResource());
}
Set<EncodedResource> currentResources = this.resourcesCurrentlyBeingLoaded.get();
if (currentResources == null) {
currentResources = new HashSet<EncodedResource>(4);
this.resourcesCurrentlyBeingLoaded.set(currentResources);
}
if (!currentResources.add(encodedResource)) { //向currentResources里面添加resource失败。
throw new BeanDefinitionStoreException(
"Detected cyclic loading of " + encodedResource + " - check your import definitions!");
}
try {
InputStream inputStream = encodedResource.getResource().getInputStream();
try {
// 把流包装成inputSource,InputSource类中封装了许多便于操作xml的方法。
InputSource inputSource = new InputSource(inputStream);
if (encodedResource.getEncoding() != null) {
inputSource.setEncoding(encodedResource.getEncoding());
}
//返回注册的BeanDefinition的个数。
return doLoadBeanDefinitions(inputSource, encodedResource.getResource());
} finally {
inputStream.close();
}
} catch (IOException ex) {
throw new BeanDefinitionStoreException(
"IOException parsing XML document from " + encodedResource.getResource(), ex);
} finally {
//resource使用完后,从currentResources中删掉。
currentResources.remove(encodedResource);
if (currentResources.isEmpty()) {
//如果没有需要解析的resource了,remove掉resourcesCurrentlyBeingLoaded。
this.resourcesCurrentlyBeingLoaded.remove();
}
}
}
整理一下,readers的loadBeanDefinitions方法首先对Resource参数使用EncodedResource类封装,之后从Resource获得对应的InputStream输入流并构造InputSource,使用构造的InputSource实例和Resource实例调用doLoadBeanDefinitions方法。
下面看一看doLoadBeanDefinitions方法
protected int doLoadBeanDefinitions(InputSource inputSource, Resource resource)
throws BeanDefinitionStoreException {
try {
//获得Document对象。
Document doc = doLoadDocument(inputSource, resource);
return registerBeanDefinitions(doc, resource); //返回注册的BeanDefinition的个数。
} catch (BeanDefinitionStoreException ex) {
throw ex;
} catch (SAXParseException ex) {
throw new XmlBeanDefinitionStoreException(resource.getDescription(),
"Line " + ex.getLineNumber() + " in XML document from " + resource + " is invalid", ex);
} catch (SAXException ex) {
throw new XmlBeanDefinitionStoreException(resource.getDescription(),
"XML document from " + resource + " is invalid", ex);
} catch (ParserConfigurationException ex) {
throw new BeanDefinitionStoreException(resource.getDescription(),
"Parser configuration exception parsing XML from " + resource, ex);
} catch (IOException ex) {
throw new BeanDefinitionStoreException(resource.getDescription(),
"IOException parsing XML document from " + resource, ex);
} catch (Throwable ex) {
throw new BeanDefinitionStoreException(resource.getDescription(),
"Unexpected exception parsing XML document from " + resource, ex);
}
}
除去异常处理,其实只做了两件事
获取Document对象Document doc = doLoadDocument(inputSource, resource);
进行注册registerBeanDefinitions(doc, resource);
doLoadDocument方法调用了documentLoader的loadDocument方法
protected Document doLoadDocument(InputSource inputSource, Resource resource) throws Exception {
return this.documentLoader.loadDocument(inputSource, getEntityResolver(), this.errorHandler,
getValidationModeForResource(resource), isNamespaceAware());
}
documentLoader是一个接口,真正调用的是他的实现类DefaultDocumentLoader
下面是loadDocument方法
@Override
public Document loadDocument(InputSource inputSource, EntityResolver entityResolver,
ErrorHandler errorHandler, int validationMode, boolean namespaceAware) throws Exception {
DocumentBuilderFactory factory = createDocumentBuilderFactory(validationMode, namespaceAware);
if (logger.isDebugEnabled()) {
logger.debug("Using JAXP provider [" + factory.getClass().getName() + "]");
}
DocumentBuilder builder = createDocumentBuilder(factory, entityResolver, errorHandler);
return builder.parse(inputSource);
}
把文档转换为Document后,接下来就是提取及注册bean了
public int registerBeanDefinitions(Document doc, Resource resource) throws BeanDefinitionStoreException {
//BeanDefinitionDocumentReader是一个接口,通过createBeanDefinitionDocumentReader()方法创建一个DefaultBeanDefinitionDocumentReader对象。
BeanDefinitionDocumentReader documentReader = createBeanDefinitionDocumentReader();
//记录之前BeanDefinition的加载个数
int countBefore = getRegistry().getBeanDefinitionCount();
documentReader.registerBeanDefinitions(doc, createReaderContext(resource));
//记录本次加载BeanDefinition的个数
return getRegistry().getBeanDefinitionCount() - countBefore;
}
进入DefaultBeanDefinitionDocumentReader类的registerBeanDefinitions(Document doc, XmlReaderContext readerContext)方法
@Override
public void registerBeanDefinitions(Document doc, XmlReaderContext readerContext) {
this.readerContext = readerContext;
logger.debug("Loading bean definitions");
Element root = doc.getDocumentElement();
//解析并注册BeanDefinition。
doRegisterBeanDefinitions(root);
}
doRegisterBeanDefinitions(root)方法开始真正的解析了
/**
* Register each bean definition within the given root {@code <beans/>} element.
*/
protected void doRegisterBeanDefinitions(Element root) {
// Any nested <beans> elements will cause recursion in this method. In
// order to propagate and preserve <beans> default-* attributes correctly,
// keep track of the current (parent) delegate, which may be null. Create
// the new (child) delegate with a reference to the parent for fallback purposes,
// then ultimately reset this.delegate back to its original (parent) reference.
// this behavior emulates a stack of delegates without actually necessitating one.
BeanDefinitionParserDelegate parent = this.delegate;
this.delegate = createDelegate(getReaderContext(), root, parent);
//解析profile 区分生产环境和开发环境
if (this.delegate.isDefaultNamespace(root)) {
//PROFILE_ATTRIBUTE = "profile";
String profileSpec = root.getAttribute(PROFILE_ATTRIBUTE);
if (StringUtils.hasText(profileSpec)) {
//BeanDefinitionParserDelegate.MULTI_VALUE_ATTRIBUTE_DELIMITERS = ",; "
String[] specifiedProfiles = StringUtils.tokenizeToStringArray(
profileSpec, BeanDefinitionParserDelegate.MULTI_VALUE_ATTRIBUTE_DELIMITERS);
if (!getReaderContext().getEnvironment().acceptsProfiles(specifiedProfiles)) {
return;
}
}
}
//模板方法,可用户自定义
preProcessXml(root);
parseBeanDefinitions(root, this.delegate);
//模板方法,可用户自定义
postProcessXml(root);
this.delegate = parent;
}
parseBeanDefinitions方法
//解析标签信息,并构造BeanDefinition注册。
protected void parseBeanDefinitions(Element root, BeanDefinitionParserDelegate delegate) {
if (delegate.isDefaultNamespace(root)) {
NodeList nl = root.getChildNodes();
for (int i = 0; i < nl.getLength(); i++) {
//node是xml配置中每一行的内容,包括空行
Node node = nl.item(i);
if (node instanceof Element) {
Element ele = (Element) node;
if (delegate.isDefaultNamespace(ele)) {
//解析<beans/>标签下的子标签,如<import>,<bean>,<alias>,<beans>
parseDefaultElement(ele, delegate);
} else {
//自定义标签,如:<aop:config>,<context:component-scan>等
delegate.parseCustomElement(ele);
}
}
}
} else {
delegate.parseCustomElement(root);
}
}
到这里我们面临的就是对默认标签和自定义标签的解析了,将在后续文章说到。