版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/datadev_sh/article/details/84583157
hive导出数据,想找一个分隔符。hive默认分隔符是“\001”。想换个其他的。在ASCII码对照表中找了下,决定用“\0011”。
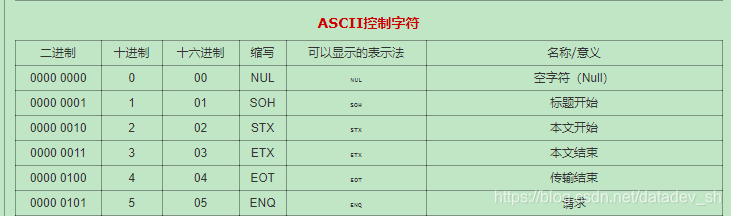
然后Hive能正常导出数据,到notepad++里面显示的字符和ASCII码对照表里的是一样的。
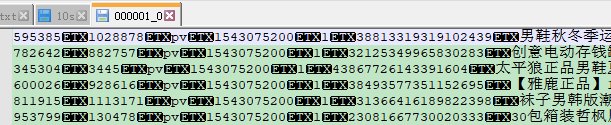
但是在pandas中用“\011”切割时,切割不出,且字段首尾不能有空格。
# Python
data = pd.read_table(path,header=None, sep='\011')
# scala
val actionRDD = data.map(_.split("\\011"))
用“EmEditor”打开这个文件,这个字符被显示为“\x03”。
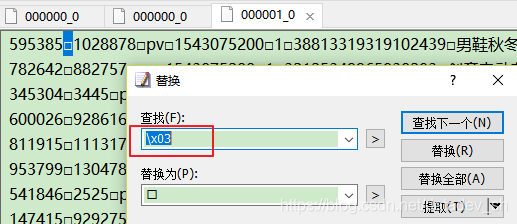
所以在pandas中用“\x03”能成功切割。
data = pd.read_table(path,header=None, sep='\x03')