Python爬虫
关于爬虫,很多人都说这个东西,第一天学第二天用第三天精通,太过轻视一件事往往是会吃大亏的,实际动手试写了一下毫不意外的遇到了各种小问题,在此总结记录,好记性不如烂笔头,以前学过的很多东西不总结都还给老师了。参考书【明日科技零基础学python】。
1.请求模块
1.1 urllib模块
urllib模块是python自带的一个模块提供了一个urlopen()方法,通过该方法可以指定URL发送网络请求来获取数据。urllib提供了多个子模块。
| 模块名称 | 描述 |
|---|---|
| urllib.request | 该模块定义了打开URL(主要是http)的方法和类,例如身份验证,重定向,cookie等等 |
| urllib.error | 该模块中主要包含异常类,基本的异常类是URLError |
| urllib.parse | 该模块定义的功能分为两大类:URL解析和URL引用 |
| urllib.robotparser | 该模块用于解析robot.txt文件 |
例1 通过urllib.request 请求网页
import urllib.request
# 指定URL
url = 'https://www.shanbay.com/wordlist/205949/643540/'
# 打开需要爬取的页面
response = urllib.request.urlopen(url)
html = response.read()
print(html)
# 由于控制台的原因,这里输出的页面是没有任何处理的HTML代码,汉字也会是乱码
# 可以对页面进行unicode编码
html = html.decode('utf8')
print(html)
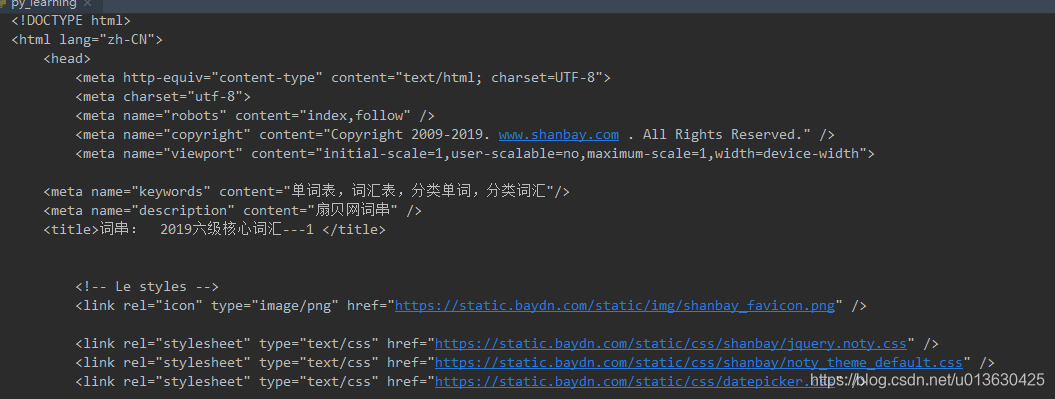
# 这样输出可以看到网页的结构
# post请求格式如下
data=bytes(urllib.parse.urlencode({'words':'hello'}),encoding='utf8')
response = urllib.request.urlopen(url,data=data)
html=reponse.read()
不编码的结果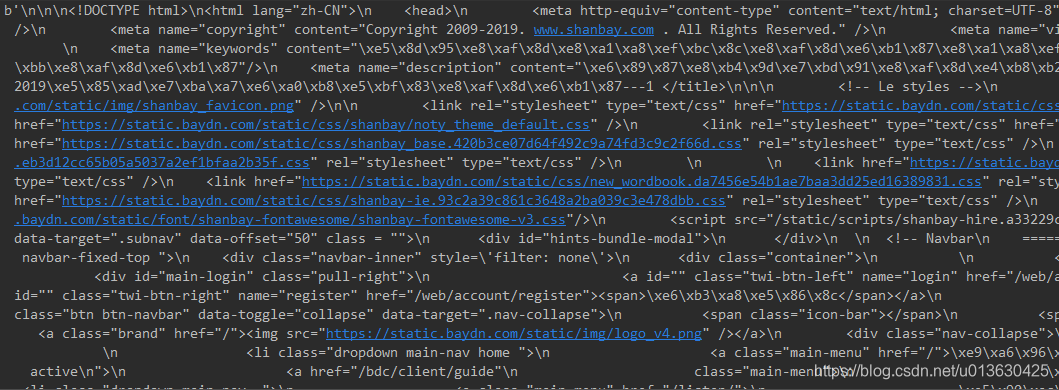
编码后明显可以看到页面结构了
1.2. Urllib3模块
Urllib3 是一个功能强大条理清晰用于HTTP客户端的Python库。具有很多Python标准库里面没有的重要特征。
- 线程安全
- 连接池
- 客户端SSL/TLS验证
- 使用大部分编码上传文件
- Helpers用于重试请求并处理HTTP重定向
- 支持gzip和deflate编码
- 支持HTTP和SOCKS代理
- 100%的测试覆盖率
import urllib3
# 创建PoolManager对象,用于处理与线程池的连接以及线程安全的所有细节
http = urllib3.PoolManager()
# 对需要爬取的网页发送请求
response = http.request('GET', url)
print(response.data)
# post请求格式如下
response=http.request('POST',field={'word':'hello'})
1.3. requests 模块
requests是Python中实现HTTP请求的一种方式,requests是第三方模块,该模块在实现HTTP请求时要比urllib模块简化很多,更加人性化。
功能特色如下
- Keep-Alive&连接池
- 国际化域名和URL
- 带持久Cookie的会话
- 浏览器式的SSL认证
- 自动内容解码
- 基本/摘要式的身份认证
- 优雅的key/value Cookie
- 自动解压
- 流下载
- 连接超时
- Unicode响应体
- HTTP(S)代理支持
- 文件分块上传
- 分块请求
- 支持.netrc
以get请求为例打印多种信息
import requests
response = requests.get(url)
print(response.status_code)
print(response.url)
print(response.headers)
print(response.cookies)
print(response.text)
print(response.content)
# post请求格式
data={'word':'hello'}
response=requests.post(url,data=data)
# 参数传递方式
payload={'key1':'value1','key2':'value2'}
response=requests.get(url,params=payload)
1.4. 请求头处理
在浏览器中打开开发者模式可以轻易拿到User-Agent信息,其中元素有很多,可以根据需要加或不加。
# 定义headers,
headers={
'User-Angent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36 SE 2.X MetaSr 1.0'
}
# 在请求URL时加上headers即可
response=reauests.get(url,headers=headers)
1.5. 网络超时
访问某个页面时如果该页面长时间无响应系统应该会判断该网页超时,无法打开页面。
for i in range(0, 50):
try:
# 根据网络环境,设置超时时间为0.2秒
response = requests.get('https://www.baidu.com', timeout=0.2)
print(response.status_code)
except Exception as e:
print('异常 ', str(e))
# 会有超时异常
# 异常 HTTPSConnectionPool(host='www.baidu.com', port=443): Read timed out. (read timeout=0.2)
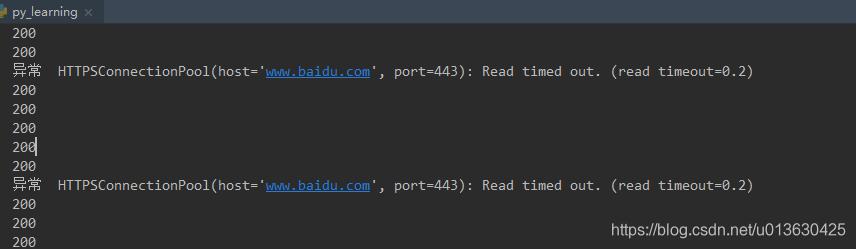
requests提供了三种常见的网络异常类
# 导入requests异常模块
from requests.exceptions import ReadTimeout,HTTPError,RequestException
for i in range(0, 10):
try:
# 根据网络环境,设置超时时间为0.2秒
response = requests.get('https://www.baidu.com', timeout=0.2)
print(response.status_code)
except ReadTimeout:
print('超时异常 ')
except HTTPError:
print('http异常')
except RequestException:
print('请求异常 ')
2.HTML解析器
2.1 BeautifulSoup
beautifulsoup有中文的文档可以参考,例子如下
下面的一段HTML代码将作为例子被多次用到.这是 爱丽丝梦游仙境的 的一段内容(以后内容中简称为 爱丽丝 的文档):
html_doc = """
<html><head><title>The Dormouse's story</title></head>
<body>
<p class="title"><b>The Dormouse's story</b></p>
<p class="story">Once upon a time there were three little sisters; and their names were
<a href="http://example.com/elsie" class="sister" id="link1">Elsie</a>,
<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and
<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p>
<p class="story">...</p>
使用BeautifulSoup解析这段代码,能够得到一个 BeautifulSoup 的对象,并能按照标准的缩进格式的结构输出:
from bs4 import BeautifulSoup
soup = BeautifulSoup(html_doc)
print(soup.prettify())
# <html>
# <head>
# <title>
# The Dormouse's story
# </title>
# </head>
# <body>
# <p class="title">
# <b>
# The Dormouse's story
# </b>
# </p>
# <p class="story">
# Once upon a time there were three little sisters; and their names were
# <a class="sister" href="http://example.com/elsie" id="link1">
# Elsie
# </a>
# ,
# <a class="sister" href="http://example.com/lacie" id="link2">
# Lacie
# </a>
# and
# <a class="sister" href="http://example.com/tillie" id="link2">
# Tillie
# </a>
# ; and they lived at the bottom of a well.
# </p>
# <p class="story">
# ...
# </p>
# </body>
# </html>
几个简单的浏览结构化数据的方法:
soup.title
# <title>The Dormouse's story</title>
soup.title.name
# u'title'
soup.title.string
# u'The Dormouse's story'
soup.title.parent.name
# u'head'
soup.p
# <p class="title"><b>The Dormouse's story</b></p>
soup.p['class']
# u'title'
soup.a
# <a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>
soup.find_all('a')
# [<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>,
# <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>,
# <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>]
soup.find(id="link3")
# <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>
从文档中找到所有<a>标签的链接:
for link in soup.find_all('a'):
print(link.get('href'))
# http://example.com/elsie
# http://example.com/lacie
# http://example.com/tillie
从文档中获取所有文字内容:
print(soup.get_text())
# The Dormouse's story
#
# The Dormouse's story
#
# Once upon a time there were three little sisters; and their names were
# Elsie,
# Lacie and
# Tillie;
# and they lived at the bottom of a well.
#
# ...
2.2 beautifulsoup 的解析器
| 解析器 | 用法 | 优点 | 缺点 |
|---|---|---|---|
| python 标准库 | BeautifulSoup(markup,‘html.parser’) | Python标准库执行速度适中 | (在2.7.3或3.2.2之前的版本中文档容错能力差)页面编码解析上可能会有问题 |
| lxml的HTML解析器 | BeautifulSoup(markup,‘lxml’) | 速度快,容错能力强 | 需要C语言支持库,部分编写不规范的页面会出现加载不全的问题 |
| lxml的XML解析器 | BeautifulSoup(markup,‘lxml-xml’) | 速度快,唯一支持XML的解析器 | 需要C语言支持库 |
| html5lib | BeautifulSoup(markup,‘html5lib’) | 最好的容错性,以浏览器的方式解析文档,生成HTML5格式的文档 | 速度慢,不依赖外部扩展 |
2.2 其他框架
Scrapy框架是一个比较成熟的Python框架。BeautifulSoup可以说是一个解析器,而Scrapy就是一个完整的工具,中文文档
Crawley框架。
PySpider框架。