Python学习记录Day2
1.变量(Variables)
1.1 什么是变量?变量的作用是什么?
Variables are used to store information to be referenced and manipulated in a computer program. They also provide a way of labeling data with a descriptive name, so our programs can be understood more clearly by the reader and ourselves. It is helpful to think of variables as containers that hold information. Their sole purpose is to label and store data in memory. This data can then be used throughout your program.
简而言之,变量就是个载体,一般用于存储信息,还可以提供命名。

如上图所示,name为变量名,而变量name的值为:nature天一
1.2 变量名命名规则
1.变量名只能是字母,数字或下划线的任意组合 (eg:job ,name,_123,_my_name......)
2.变量名的第一个字符不能是数字
3.不能用关键字
另外,值得一提的是,变量的命名最好有含义,最好定义为age=" 21" job="IT" 这样大家都容易看懂的,当然a ="21" b= "IT"并没有错误,但是Python讲究的是容易看懂,你定义为a ,b,这样的话,只有自己看的懂,别人看你的代码不容易懂。
1.2.1 关键字
关键字如下:
['False', 'None', 'True', 'and', 'as', 'assert', 'async', 'await', 'break', 'class', 'continue', 'def', 'del', 'elif', 'else', 'except', 'finally', 'for', 'from', 'global', 'if', 'import', 'in', 'is', 'lambda', 'nonlocal', 'not', 'or', 'pass', 'raise', 'return', 'try', 'while', 'with', 'yield']
可以用如下方法调出关键字:

2.字符编码和二进制
python解释器在加载 .py 文件中的代码时,会对内容进行编码(默认ascill)
ASCII(American Standard Code for Information Interchange,美国标准信息交换代码)是基于拉丁字母的一套电脑编码系统,主要用于显示现代英语和其他西欧语言,其最多只能用 8 位来表示(一个字节),即:2**8 = 256-1,所以,ASCII码最多只能表示 255 个符号。
关于中文
为了处理汉字,程序员设计了用于简体中文的GB2312和用于繁体中文的big5。
GB2312(1980年)一共收录了7445个字符,包括6763个汉字和682个其它符号。汉字区的内码范围高字节从B0-F7,低字节从A1-FE,占用的码位是72*94=6768。其中有5个空位是D7FA-D7FE。
GB2312 支持的汉字太少。1995年的汉字扩展规范GBK1.0收录了21886个符号,它分为汉字区和图形符号区。汉字区包括21003个字符。2000年的GB18030是取代GBK1.0的正式国家标准。该标准收录了27484个汉字,同时还收录了藏文、蒙文、维吾尔文等主要的少数民族文字。现在的PC平台必须支GB18030,对嵌入式产品暂不作要求。所以手机、MP3一般只支持GB2312。
从ASCII、GB2312、GBK 到GB18030,这些编码方法是向下兼容的,即同一个字符在这些方案中总是有相同的编码,后面的标准支持更多的字符。在这些编码中,英文和中文可以统一地处理。区分中文编码的方法是高字节的最高位不为0。按照程序员的称呼,GB2312、GBK到GB18030都属于双字节字符集 (DBCS)。
有的中文Windows的缺省内码还是GBK,可以通过GB18030升级包升级到GB18030。不过GB18030相对GBK增加的字符,普通人是很难用到的,通常我们还是用GBK指代中文Windows内码。
显然ASCII码无法将世界上的各种文字和符号全部表示,所以,就需要新出一种可以代表所有字符和符号的编码,即:Unicode
Unicode(统一码、万国码、单一码)是一种在计算机上使用的字符编码。Unicode 是为了解决传统的字符编码方案的局限而产生的,它为每种语言中的每个字符设定了统一并且唯一的二进制编码,规定虽有的字符和符号最少由 16 位来表示(2个字节),即:2 **16 = 65536,
注:此处说的的是最少2个字节,可能更多
UTF-8,是对Unicode编码的压缩和优化,他不再使用最少使用2个字节,而是将所有的字符和符号进行分类:ascii码中的内容用1个字节保存、欧洲的字符用2个字节保存,东亚的字符用3个字节保存...
历史顺序理一下:
ASCII 255 1bytes
--------1980 GB2312 7445
----------1995 GBK1.0 21886
----------2000 GB18030 27484
----------Unicode(万国码,统一码) 2bytes
---------- UTF-8 ASCII码中的内容1个字节,欧洲字符2个字节,东亚的字符3个字节保存
3.if-else
if-else是一个判断语句,就像流程图一样,如果满足这个条件,它就执行yes对应的语句,否则就是no对应的语句;
按我自己来说if-else条件语句,其实就是if +一个条件: 而冒号后面就是对应输出的语句,如果这个条件为True的话,他就会执行后面的语句;但是如果条件为False的话,则后面就会有else:输出内容。
来一个简单的代码就可以很清楚的弄明白问题了:

这里的条件语句是 name_input == name,python中 == 是等于的意思,也就是说这个条件是判断我们输入的name_input是否等于已经确定的name,如果它们相等,那么条件为True,就会print(“用户名正确,欢迎!”);同理,如果不等的话,条件为False,就会执行else语句,会print(“请输入正确的用户名”)
4.while循环
个人感觉while也是和if一样是判断语句,while+条件 :如果条件为True,它会一直执行
举个简单的例子:

当while的条件为True,它就一直print(“emmmmm”),不会停止,所以最好在后面在上一个break,break是结束整个循环
5.for循环
直接来看一个例子:

continue表明不继续往下走,直接开始下一个循环。
for i in range(10): 其实就是让i依次从0-9中循环,第一次i为0,开始第一次循环,然后为1,2.....,最后为9,也就是遍历
加上if中的条件 i<5,conyinue,就会print(“loop”,i),其实这个可以换成if i>4:print("loop",i),会得出同样的结果。
6.作业
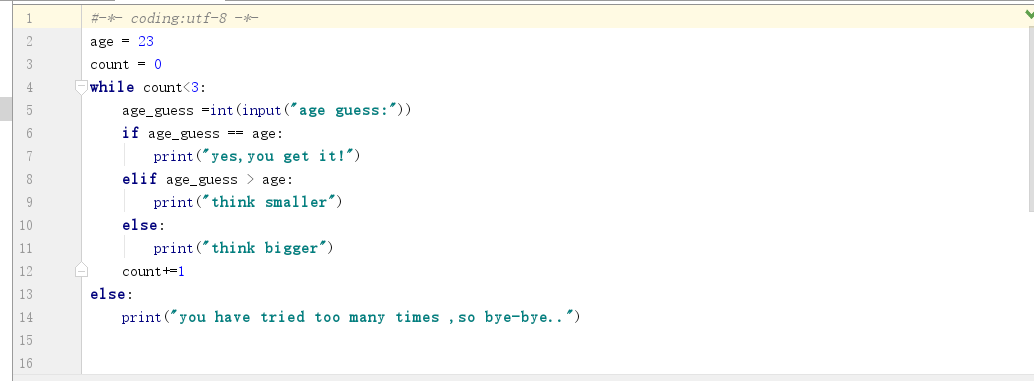
1.如何实现让用户不断的猜年龄,但只给最多3次机会,再猜不对就退出程序
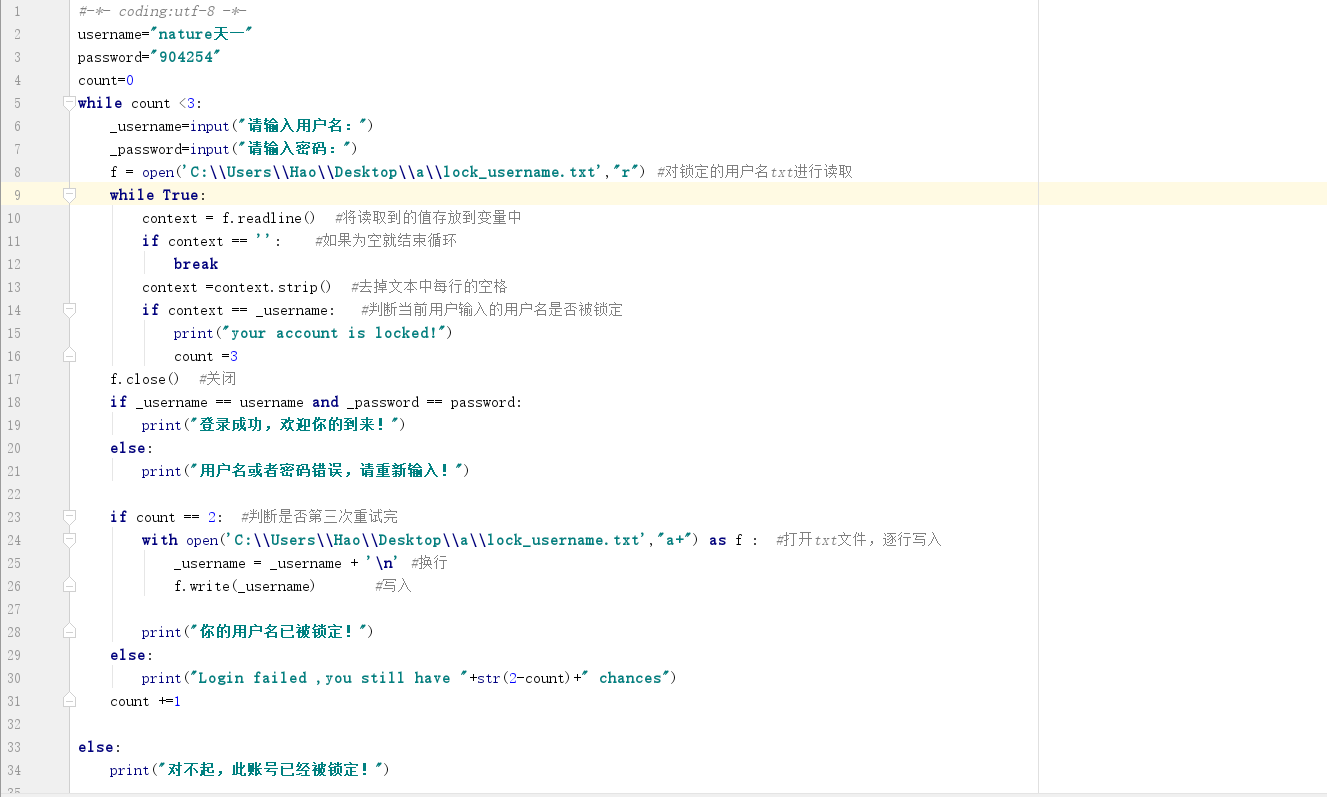
2.编写登录接口,实现以下三个功能:
·输入用户名密码
·认证成功后显示欢迎信息
·输入三次后锁定