Spark Streaming
Spark Streaming 是在 Spark 批处理基础上构建的流式框架。
Duration 时间窗口
Batch duration
批处理间隔,它是指 Spark streaming 以多少时间间隔为单位来提交任务逻辑。
Spark Streaming 在处理数据时是以 “一批” 为单位, Spark Streaming 系统需要设置时间间隔使得数据汇总到一定的量后再一并进行处理,这个时间就是 batch duration。此参数决定提交作业的频率和数据处理的时延。
Slide duration
控制着计算的频率。用来控制对新的 DStream 进行计算的间隔。
window duration
当前一个窗口处理数据的时间跨度。控制每次计算最近的多少个批次的数据。
在实际项目中,window duration 和 slide duration 的默认值时相同的,在自行设置中,必须保证其为 batch duration 的整数倍。

关于 Slide duration 和 window duration 的保证:
- 因为每个 batch 内的数据可能被后面几个窗口间隔所处理,所以数据会保存在 Spark Streaming 系统中,不会立即被处理;
- 窗口的重叠会带来重复计算,Spark Streaming 框架会进行优化,保证计算过的数据不会被重复计算;
注:在初始的几个窗口,可能数据是没有被填充满的,随着时间的推进,窗口会最终被填充满。
DStream
Spark Streaming 抽象了离散数据流 DStream(Discretized Stream),它包含一组连续的 RDD,这组连续的 RDD 代表了连续的流式数据。
DStream 是一组时间序列上的连续的 RDD 来表示的,每个 RDD 都包含特定时间间隔的数据流。用户对 DStream 上的各种操作最终都会映射到内部的 RDD 中。
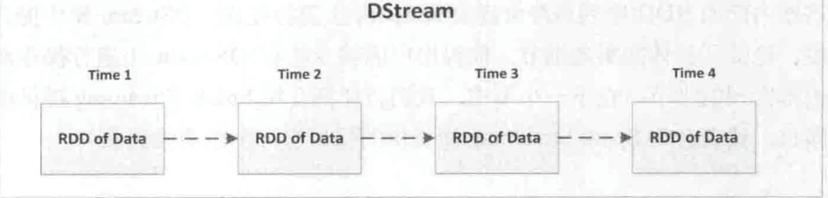
在 Spark Streaming 中,作业产生后并不会立即被提交,而是需要等到 StreamingContext 启动后才会被依次提交 sc.start(),作业的提交间隔是由批处理间隔 slide duration 决定的。
Spark Streaming 作业最终会被翻译成 SparkCore 作业并提交和执行。DStream 在内部维护了相应的 RDD,对于 Dstreaming 的操作,无论是转换操作还是输出操作,最终都会被映射到 RDD 上。
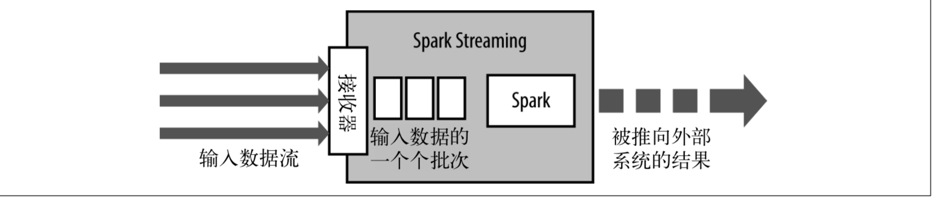
案例:
代码 ——> 打包 ——> submit ——> 模拟
package com.demo.streaming;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.function.FlatMapFunction;
import org.apache.spark.api.java.function.Function2;
import org.apache.spark.api.java.function.PairFunction;
import org.apache.spark.streaming.Durations;
import org.apache.spark.streaming.api.java.JavaDStream;
import org.apache.spark.streaming.api.java.JavaPairDStream;
import org.apache.spark.streaming.api.java.JavaReceiverInputDStream;
import org.apache.spark.streaming.api.java.JavaStreamingContext;
import scala.Tuple2;
import java.util.Arrays;
import java.util.Iterator;
public class StreamingWindowApp {
public static void main(String[] args) throws InterruptedException {
SparkConf conf = new SparkConf()
.setMaster("local[2]")
.setAppName("StreamingWindowApp");
JavaStreamingContext jssc = new JavaStreamingContext(conf, Durations.seconds(5));
JavaReceiverInputDStream<String> lines = jssc.socketTextStream("localhost", 8888);
JavaDStream<String> dStream = lines.flatMap(new FlatMapFunction<String, String>() {
private static final long serialVersionUID = 1L;
@Override
public Iterator<String> call(String s) throws Exception {
System.out.println(s+" ");
return Arrays.asList(s.split(" ")).iterator();
}
});
JavaPairDStream<String, Integer> wordCounts = dStream.mapToPair(new PairFunction<String, String, Integer>() {
private static final long serialVersionUID = 1L;
@Override
public Tuple2<String, Integer> call(String s) throws Exception {
return new Tuple2<>(s, 1);
}
}).reduceByKey(new Function2<Integer, Integer, Integer>() {
private static final long serialVersionUID = 1L;
@Override
public Integer call(Integer v1, Integer v2) throws Exception {
return v1 + v2;
}
});
Thread.sleep(5000);
wordCounts.print();
jssc.start();
jssc.awaitTermination();
jssc.close();
}
}
#提交
./spark-submit --class com.demo.streaming.StreamingWindowApp /root/monitoranalysis-1.0-SNAPSHOT-jar-with-dependencies.jar
#模拟实时数据
nc -lk 8888 ——> 输入
