版权声明:本文为博主原创文章,转载请标明出处 https://blog.csdn.net/C2681595858/article/details/85687836
文章目录
实验代码(github)
一、实验内容
1、 Dijkstra算法求最短路径。
- 测试用图
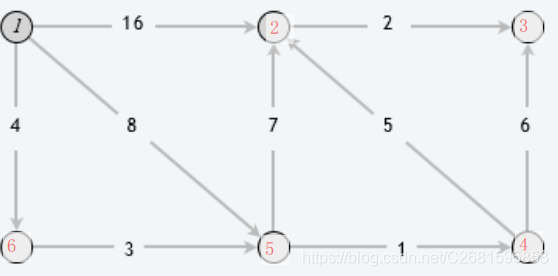
- 预期结果:
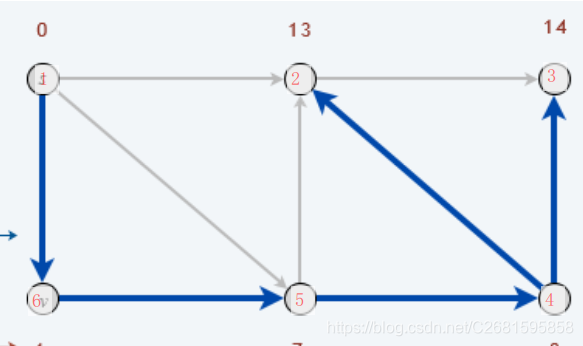
2、Bellman-ford算法求最短路径
- 测试用图
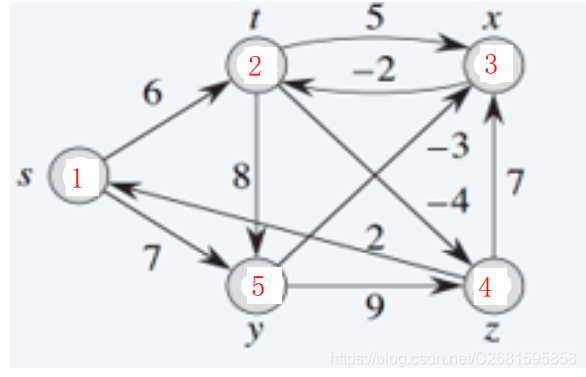
- 预期结果

二、理论准备
1、 Dijkstra算法
- 最大的一个特征就是为每一个顶点维护了一个 值,就是从原点到该点,经过已经知道的最短路径长度。然后选择还未加进来的顶点中 值最小的顶点加进来,然后在修改与刚加进来的这个顶点相邻的顶点的 值,一直循环,直到所有顶点都已经加进来了。
- 它只要有两个步骤,一个是更新未确定的顶点的 值,另一个是从更新后的顶点中选择 值最小的一个顶点,让它加进来,也就是将它变为确定的顶点。先更新然后选择的目的是,
- 伪码如下:

- decrease-key()这里是说减小顶点v在队列中的key值。
- 特别注意,这里每次更新优先队列中的 [v]的时候是 。学过最小生成树的同学知道有一个prim算法与dijkstra算法非常相似,但是注意他们并不相同,prim算法每次用定点u到v之间的权重去更新优先队列中v的key值,不需要加上 .
2、bellman-ford算法
- 算法思路:
核心思想是:首先对距离进行松弛,然后随着迭代次数的增加,距离越来越接近最短路径,直到最后得出最短路径。
更具体一点说就是每一次检查每一条边(u,v),看是否有 情况,如果有就更新d[v]的值,这样一来每一遍大的循环就把源点的情况全局推进一步,然后最多推进n-1步也就把原点的情况推到了每一个节点。 - 伪码:

- 伪码解读:
- 在内部的两层循环中看似是两层循环应该有 的复杂度,但是它真正是m的复杂度,这是为什么呢?
- 首先思考bellman-ford算法最初的想法,他是每次查看一条边是否满足 情况。所以那两层内层循环实质上是在便利所有的边,所以它的复杂度只是边的条数m,而不是 .
3、 两个算法的使用环境。
- Dijkstra算法适用于没有负权边的图。
- 引理1:如果一个s~v包含负圈,那么它没有最短路径。
- 引理2:如果没有负圈,那么就一定有最短路径,并且这个最短路径最多包含n-1条边,n是顶点数目。
- bellman-ford可以有负边,但是如果有负边就一定不能有负圈。
- 负圈:圈上各个边之和是负值。这里要注意,有负边并且负边在圈上,但是这个圈不一定是负圈。
三、实验环境
- 操作系统及版本:windows10
- 编译软件及版本:g++6.3.0
- 使用的计算机语言:c语言
四、实验过程
- 这次实验是在前几次实验的基础上完成的。
1、Dijkstra算法
- 算法过程和理论准备中是一样的,核心代码如下:
void Graph::dijkstra(int startId)
{//先把它从队列中删除,然后找到它的邻居顶点并更新节点的值直到队列为空
Pritree<Vertex> pritree;
initialForDij(pritree, startId);
while(pritree.getSize() != 0)
{
Vertex temp = pritree.popHead();//找到discovery最小的值
Vertex* vertexp = findVerAccId(temp.getVertexId());
Node* neighbor = vertexp->getHeadNode();//找到邻居节点
// cout<<temp.getVertexId()<<"-> ";
while(neighbor != NULL)//对每一个邻居节点进行循环中的操作
{
Vertex* tempNe = neighbor->getVertex();//与弹出来的顶点相邻的顶点
if(tempNe->getDiscovery() > temp.getDiscovery() + neighbor->getWeight())
{
tempNe->setDiscovery(temp.getDiscovery() + neighbor->getWeight());
tempNe->setParent(vertexp);//记住其父节点
pritree.delete_ele(*tempNe, equal);//从优先队列中删除
pritree.insert(*tempNe);//然后插入新的更新后的顶点
}
neighbor = neighbor->getNextNode();
}
}
//打印出最后的结果
Vertex* for_out_ver = this->headVertex;
cout<<"dijkstra:"<<endl;
while(for_out_ver != NULL)
{
for_out_ver = for_out_ver->getNextVertex();
if(for_out_ver != NULL)
cout<<(for_out_ver->getParent())->getVertexId()<<"->"<<for_out_ver->getVertexId()<<endl;
}
}
2、bellman-ford算法
- 实现方式和理论准备中的伪码是一样的,它的实现思路比起dijkstra算法的话要简单,但是它复杂度也更高。
void Graph::bellmanFord(int startId)
{
//初始化
Vertex* vptr = this->headVertex;
while(vptr != NULL)
{
if(vptr->getVertexId() == startId)
vptr->setDiscovery(0);
else
vptr->setDiscovery(INT_MAX);
vptr->setParent(NULL);
vptr = vptr->getNextVertex();
}
//最外层迭代顶点数目减一次
for(int counter0 = 1; counter0 < this->vertexNumber; counter0++)
{
vptr = this->headVertex;
while(vptr != NULL)//遍历每一个顶点
{
Node* eptr = vptr->getHeadNode();
while(eptr != NULL)//遍历每一条边
{
Vertex* vtoptr = eptr->getVertex();
if( vtoptr->getDiscovery()> vptr->getDiscovery()+eptr->getWeight())
{
vtoptr->setDiscovery(vptr->getDiscovery()+eptr->getWeight());
vtoptr->setParent(vptr);
}
eptr = eptr->getNextNode();
}
vptr = vptr->getNextVertex();
}
}
Vertex* for_out_ver = this->headVertex;
cout<<"bellman-ford:"<<endl;
while(for_out_ver != NULL)
{
for_out_ver = for_out_ver->getNextVertex();
if(for_out_ver != NULL)
cout<<(for_out_ver->getParent())->getVertexId()<<"->"<<for_out_ver->getVertexId()<<endl;
}
}
五、实验结果
- 测试用图在实验内容中给出了,下面是算法执行的结果,一对数字代表一条边:
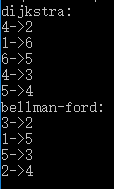
- 注意这两个结果不同的算法,测试用的图是不一样的,当然也可以用没有负边的图去测试bellman-ford算法。
六、实验总结
- 再写dijkstra算法的时候思路是非常清楚的,但是写出来总是有bug,真的是写bug用了半小时,debug用了半天,最终找到原因还是不够细心,误把临时对象的地址存进链表中,最后访问的时候出错。优先队列用动态数组来实现,为了使得下标和PPT上的伪码相对应,动态数组第一个位置没有存放东西,最后在写delete_ele函数时候忽略了,导致查了半天。