版权声明:本文为博主原创文章,转载请标明出处 https://blog.csdn.net/C2681595858/article/details/84104688
文章目录
实验代码(github)
一、实验内容
- 实现优先队列。
- 实现kruskal方法求最小生成树。
- 实现prim算法求最小生成树。
最后用下面的图进行测试:

二、理论知识
1、 优先队列
- 特点:插入元素和查找最值时间复杂度都是log(n)。
- 实现思路:使用完全二叉树,所有操作保证父节点大于子节点(仅父子节点大小关系,没有其他要求),这样最大值就是树根。
- 具体细节:
由于父节点必须大于子节点,所以在插入或者删除的时候要进行顺序调整,调整方法如下:

- 插入时,直接把元素插到数组最后一个位置,这样在树中也就是最下层的最右叶节点(图右上1)。然后比较叶节点和它父节点的大小关系,如果父节点小于它,那么交换他们的位置,以此类推,直到父节点大于它,就找到了正确位置。由于它最糟糕的情况就是从叶节点一直换到树根,假设树的层数从0开始计,总共有h层。那么他就换了h次。而这里h = log(n),n为节点总数。所以其时间复杂度也是log(n).
- 删除时,将树的最后一个叶节点放到删除位置,然后看该位置和其父子的大小关系,进行移动。最糟糕的情况就是删除树根,然后移动的时候又从树根移到了最下层的叶子结点,那么它和插入时最糟糕的情况相同,都是交换了h次。
2、kruskal算法
- 说白了,就是在所有剩余的边中找到权值最小的边,然后看如果把它加进去,会不会构成环,如果不构成环就加进去,如果构成环,就直接扔了。看完所有的边,最小生成树也就有了。
图示具体过程如下:



3、prim算法
- 这个要用到割线。具体步骤如下:
- 从一个节点开始,画个圈,圈主自己;
- 然后在被割了的边中选权值最小的边,加进来,在画个圈,圈住原有的元素和已经加进来的元素。
- 再看被这个圈割了的哪些边,从他们中找一条权值最小的边,加进来。
- 以此类推,直到所有的顶点都进来了的时候,最小生成树也就有了。
- 具体如下图。







三、实验环境
- 操作系统及版本:windows10
- 编译软件及版本:g++6.3.0
- 使用的计算机语言:c++语言
四、实验过程
- 这次作业是在前几次作业的基础上完成的,也就是说底层的代码架构、图的存储方式和前面是相同的,下面只着重解释新实现的算法。
1、优先队列
- 输入:用两个端点表示且有权重的边组成的集合
- 输出:这个集合中权值最小的边
- 思路:
- 为了让这个优先队列具有普适性,选择使用模板实现。
- 由于传进去的是一个对象,由于在排序时需要比较大小,所以该对象所属的类应该重载了比较运算符。为了简化程序的实现,排序时尽量将使用的比较运算符限定在(>,<,==)之间。
主要实现了下面的几个函数:
//insert a element into priority queue
void insert(T ele_in);
//get it root element, but not delete it
T getHead();
//get it root element, and delete it.
T popHead();
//get the length of queue
int getSize();
它的私有成员有下面这些:
T* btree;//it will be used as a array.
int length;
int maxLength;
- btree在构造函数中给它申请大小为maxLength的空间,然后length记录它真正的长度。
- 有一个私有函数成员
void ifResize();再每次插入的时候会判断是否需要扩充btree的空间,如果需要就扩充,每次扩充为原有空间的2倍。
2、prim算法
- 这个算法由于它在计算过程中只会产生两个集合,所以相比于kruskal算法简单些,然后一个函数就可以实现具体如下:
void Graph::prim(int startId)
{
set<int> setInt;//这个集合用来存放已经被加进来的顶点
setInt.insert(startId);
cout<<"from "<<"to "<<"weigh\n";
while(setInt.size() < this->vertexNumber)//until all vertexes add to setInt
{
Pritree<Node> pritree;
for(set<int>::iterator it = setInt.begin(); it != setInt.end(); it++)
{//把这个集合所有的割边都加进来
Vertex* vertexPtr = this->headVertex;
while(vertexPtr != NULL)
{//先在顶点链表中找到set中的某个顶点
if(vertexPtr->getVertexId() == (*it))
{
Node *nodePtr = vertexPtr->getHeadNode();
while(nodePtr != NULL)
{//然后再去看,这条边是不是割边,也就是看它指向的顶点是狗已经在setInt中了
//如果这个顶点不再集合中,那么他就是一个待选顶点
if(setInt.find(nodePtr->getToId()) == setInt.end())
{//add cut edge to priority queue
pritree.insert(*nodePtr);
}
nodePtr = nodePtr->getNextNode();
}
break;
}
vertexPtr = vertexPtr->getNextVertex();
}
}
Node newNode = pritree.popHead();//弹出权值最小的边
setInt.insert(newNode.getToId());//把这个边指向的顶点加进集合中
cout<<newNode.getFromId()<<" "<<newNode.getToId()<<" "<<newNode.getWeight()<<endl;
}
}
3、kruskal算法
- 思路:使用二维动态数组实现,每一行的第一个位置记录这一行的长度。每一行放一个集合,随着每个集合元素数量的变化动态改变每一行的大小。如果发现两个集合之间有一条边被加进去了,那么这两个集合就合并为一个集合。
void Graph::kruskal()
{
cout<<"from "<<"to\n";
Pritree<Node> pritree;
initial(pritree);
while(this->list_set[0][0] < this->vertexNumber+1)
{
Node newNode = pritree.popHead();
//posf是fromId所在的集合下标,post是toId所在集合下标
int posf = -1, post = -1;
find(newNode,posf, post);
if(posf != post)//如果这两个元素不再同一个集合中,那么合并这两个集合
{
cout<<newNode.getFromId()<<" "<<newNode.getToId()<<" "<<endl;
merge(posf,post);
}
}
}
void initial(Pritree<Node>& pritree);//负责把所有的边加进优先队列中
void find(Node& newNode, int& posf, int& post);//查看两个元素是否在同一个集合中
void merge(int& posf, int& post);//合并两个集合
五、实验结果
- 最终输出如下:from 表示起始顶点,to表示到达顶点,weight表示边上的权重。
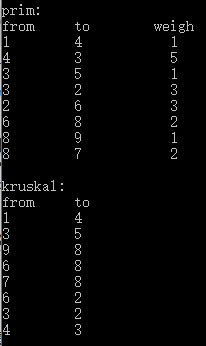
- 用图的形式表示出来就是:
prim:

kruskal:

- 这个例子,这两个算法求出来的结果刚好相同。
六、实验总结
- 在做kruskal算法时,遇到了困难,怎么样对顶点进行分组,不知道将会有多少组,空间不好开辟,最后选择了动态数组,就是用完就删,要用就申请的死办法。最终是做出来了,但但感觉非常不好,当然这是在老师讲具体的kruskl算法实现之前。
图取自刘宏老师PPT ↩︎