版权声明:本文为博主原创文章,转载请附上博文链接! https://blog.csdn.net/m0_37263345/article/details/91418355
一、简介
1、 AdaBoost就是损失函数为指数损失的Boosting算法(当然这是后话,意思是指数损失的前向分步算法和Adaboost一致)
二、细节
1、算法流程

2、最重要的两点
误差率: ==
==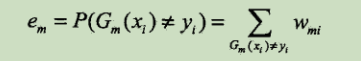 (也就是在一轮过后,误差率直接用分错样本的权重想加就可以了)
(也就是在一轮过后,误差率直接用分错样本的权重想加就可以了)
(1)、弱分类器的权重如何确定
权重![]() 仅仅由该分类器的分类误差率e决定,e的范围应该是[0, 0.5]
仅仅由该分类器的分类误差率e决定,e的范围应该是[0, 0.5]
 ,所以误差率越大,权重越小
,所以误差率越大,权重越小
(2)、样本的权重如何确定
样本的下一次的权重是由上个分类器的误差率和上个分类器是否对该样本正确分类来决定

(a)、先说是否正确分类,如果正确分类,那么最右边的公式将是分数的形式,值相对较小,错误分类就是正指数的形式,值相对较大,对应分错的样本将在下一轮分配更大的权重
(b)、再说误差率,对于正确分类的样本,如果误差率较大,也就是权重![]() 较小,那么此时
较小,那么此时![]() ,就会偏大,说明此例的分类结果相对不可信,值得更多的关注,如果误差率较小,权重较大,那么此时
,就会偏大,说明此例的分类结果相对不可信,值得更多的关注,如果误差率较小,权重较大,那么此时![]() ,就会相对偏小,说明此例的分类结果相对可信,那么就分配更小的权重
,就会相对偏小,说明此例的分类结果相对可信,那么就分配更小的权重
对于错误分类的样本,如果误差率较小,权重较大,那么此时![]() ,就会偏大,表示在误差率较小的分类器里边,又分错了,所以值得更多的关注,如果误差率较大,权重较小,那么此时
,就会偏大,表示在误差率较小的分类器里边,又分错了,所以值得更多的关注,如果误差率较大,权重较小,那么此时![]() ,就会偏小,在误差大的分类器下,分错了,情有可原,所以分配一个更小的权重。
,就会偏小,在误差大的分类器下,分错了,情有可原,所以分配一个更小的权重。
3、强分类器

这里所有的![]() 的和不为1
的和不为1
4、理论解释
由算法的推导过程可以证明,该算法的学习步骤正是一个损失函数是指数损失函数的前向分步算法的优化问题
推导:



