Hadoop笔记大全
Hadoop的思想:分而治之(将大文件、大批量文件,分布式存放在大量服务器上,以便于采取分而治之的方式对海量数据进行运算分析)
一.hdfs
1.定义:
分布式文件存储系统。
2.作用:
分布式存储文件。
3.应用场景:
一次写入,多次读出,且不支持文件的修改的场景。
4.重要角色:
NameNode,DataNode,block
①NameNode:NameNode负责管理整个文件系统的元数据。
(1)namenade工作职责:
负责客户端请求的响应
元数据的管理(查询,修改)
管理datanode的状态
(2)namenode数据管理存储的三种形式:
内存元数据(NameSystem)
磁盘元数据镜像文件
数据操作日志文件(可通过日志运算出元数据)
(3)元数据的checkpoint:secondarynamenode将namenode上积累的所有edits和一个最新的fsimage下载到本地,并加载到内存进行merge。重点词(secondarynamenode和namenode)
②secondaryNameNode:辅助NameNode的日志合并。
③DataNode:负责管理用户的文件数据块(block)。
(1)DataNode工作职责:
存储管理用户的文件块数据。
定期向namenode汇报自身所持有的block信息(通过心跳信息上报)。重点词(namenode和datanode)
5.hdfs工作流程
(1).Hdfs写操作:
①、根namenode通信请求上传文件,namenode检查目标文件是否已存在,父目录是否存在
②、namenode返回是否可以上传
③、client请求第一个 block该传输到哪些datanode服务器上
④、namenode返回3个datanode服务器ABC
⑤、client请求3台dn中的一台A上传数据(本质上是一个RPC调用,建立pipeline),A收到请求会继续调用B,然后B调用C,将真个pipeline建立完成,逐级返回客户端
⑥、client开始往A上传第一个block(先从磁盘读取数据放到一个本地内存缓存),以packet为单位,A收到一个packet就会传给B,B传给C;A每传一个packet会放入一个应答队列等待应答
⑦、当一个block传输完成之后,client再次请求namenode上传第二个block的服务器。
(2)HDFS读操作:
①、跟namenode通信查询元数据,找到文件块所在的datanode服务器
②、挑选一台datanode(就近原则,然后随机)服务器,请求建立socket流
③、datanode开始发送数据(从磁盘里面读取数据放入流,以packet为单位来做校验)
④、客户端以packet为单位接收,先在本地缓存,然后写入目标文件
6.配置:
①配置前准备:jdk安装,ssh免密登录,时间同步,关闭防火墙和配置局域网。
②配置的文件
1.vi hadoop-env.sh
export JAVA_HOME=/apps/jdk1.8.0_60
2.vi core-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://192.168.91.3:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/hadoop/data/temp</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>4096</value>
</property>
<property>
<name>fs.trash.interval</name>
<value>5</value>
</property>
<property>
<name>fs.trash.checkpoint.interval</name>
<value>5</value>
</property>
</configuration>
3. vi hdfs-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<!--镜像文件fsimage的检测目录-->
<property>
<name>dfs.namenode.checkpoint.dir</name>
<value>/hadoop/data/name</value>
</property>
<!--日志文件edits的检测目录-->
<property>
<name>dfs.namenode.checkpoint.edits.dir</name>
<value>/hadoop/data/edits</value>
</property>
<property>
<name>dfs.namenode.checkpoint.period</name>
<value>3600</value>
</property>
<property>
<name>dfs.namenode.checkpoint.txns</name>
<value>1000000</value>
</property>
<!--是否开启hdfs的文件系统权限-->
<property>
<name>dfs.permissions.enabled</name>
<value>false</value>
</property>
<!--是否开启webhdfs api的权限-->
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
<!--设置块的大小-->
<property>
<name>dfs.blocksize</name>
<value>900M</value>
</property>
</configuration>
4.vi slaves
hry1
hry2
hry3
5.vi /etc/profile
export JAVA_HOME=/apps/jdk1.8.0_60
export PATH=$PATH:$JAVA_HOME/bin
export HADOOP_HOME=/apps/hadoop-2.7.1
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:
6.把jdk和Hadoop以及profile文件分发给hry2和hry3:scp
6.source /etc/profile
7.启动namenode之前必须进行Hadoop namenode-format
7.启动和端口:
start/stop-dfs.sh ,可以看到namenode,secondarynamenode和datanode
网页测试:hry1:50070
注意:start/stop-all.sh 是hdfs,yarn,spark的同时启动命令
二.zookeeper
1.定义:
分布式协调服务。
2.作用:
为用户的分布式程序提供协调服务,存储数据,提供数据节点监听功能。
3.应用场景:
(1) 场景一:节点的动态上下线。
(2) 场景二:高可用、主从选举,解决单点故障。
(3) 统一配置管理。
(4)统一的名称服。
(5)分布式锁。
4.重要角色:
5.Leader工作流程:
(1)Leader主要有三个功能:
1 .恢复数据;
2 .维持与Learner的心跳,接收Learner请求并判断Learner的请求消息类型;
3 .Learner的消息类型主要有PING消息、REQUEST消息、ACK消息、REVALIDATE消息,根据不同的消息类型,进行不同的处理。
PING消息是指Learner的心跳信息;REQUEST消息是Follower发送的提议信息,包括写请求及同步请求;ACK消息是 Follower的对提议的回复,超过半数的Follower通过,则commit该提议;REVALIDATE消息是用来延长SESSION有效时间。
Leader的工作流程简图如下所示,在实际实现中,流程要比下图复杂得多,启动了三个线程来实现功能。

6.Follower工作流程
(1)Follower主要有四个功能:
1. 向Leader发送请求(PING消息、REQUEST消息、ACK消息、REVALIDATE消息);
2 .接收Leader消息并进行处理;
3 .接收Client的请求,如果为写请求,发送给Leader进行投票;
4 .返回Client结果。
Follower的消息循环处理如下几种来自Leader的消息:
1 .PING消息: 心跳消息;
2 .PROPOSAL消息:Leader发起的提案,要求Follower投票;
3 .COMMIT消息:服务器端最新一次提案的信息;
4 .UPTODATE消息:表明同步完成;
5 .REVALIDATE消息:根据Leader的REVALIDATE结果,关闭待revalidate的session还是允许其接受消息;
6 .SYNC消息:返回SYNC结果到客户端,这个消息最初由客户端发起,用来强制得到最新的更新。
Follower的工作流程简图如下所示,在实际实现中,Follower是通过5个线程来实现功能的。

7.分布式锁:
①作用:保证了数据的强一致性
②分类:保持独占(所有试图来获取这个锁的客户端,最终只有一个可以成功获得这把锁)和控制时序(所有视图来获取这个锁的客户端,最终都是会被安排执行,只是有个全局时序)。
8.高可用:
①作用: 实际高可用最关键的是解决单点故障问题。
②原理:①通过双namenode消除单点故障问题。
③配置:见我Linux软件安装思维导图
9.配置:
①配置前准备:jdk,ssh免密登录,防火墙关闭,局域网搭建,时间同步
②配置zookeeper文件
1.vi zoo.cfg
# The number of milliseconds of each tick
tickTime=2000
# The number of ticks that the initial
# synchronization phase can take
initLimit=10
# The number of ticks that can pass between
# sending a request and getting an acknowledgement
syncLimit=5
# the directory where the snapshot is stored.
# do not use /tmp for storage, /tmp here is just
# example sakes.
dataDir=/apps/zookeeper-3.4.7/zKData
# the port at which the clients will connect
clientPort=2181
# the maximum number of client connections.
# increase this if you need to handle more clients
#maxClientCnxns=60
#
# Be sure to read the maintenance section of the
# administrator guide before turning on autopurge.
#
# http://zookeeper.apache.org/doc/current/zookeeperAdmin.html#sc_maintenance
#
# The number of snapshots to retain in dataDir
#autopurge.snapRetainCount=3
# Purge task interval in hours
# Set to "0" to disable auto purge feature
#autopurge.purgeInterval=1
server.1=hry1:2888:3888
server.2=hry2:2888:3888
server.3=hry3:2888:3888
2. mkdir zKData--->vi zKData/myid
1
3.配置全局变量vi /etc/profile
4.把zookeeper和profile分发到hry2和hry3上:
5.改hry2上mypid为2,hry3上mypid为3
6.加载profile:source /etc/profile
7.启动:zkServer.sh.sh start
10.启动和端口:
zkServer.sh start后jps可以看到QuorumPeerMain表示安装成功!
三.MapReduce
1.定义:
分布式运算程序的编程框架。
2.作用:
将用户编写的业务逻辑代码和自带默认组件整合成一个完整的分布式运算程序,并发运行在一个hadoop集群上。
3.应用场景:
分布式计算,Hadoop的核心部分。
4.重要角色:
①MRAppMaster:负责整个程序的过程调度及状态协调。
②MapTask:负责map阶段的整个数据处理流程。
③ReduceTask:负责reduce阶段的整个数据处理流程。
5.工作流程:
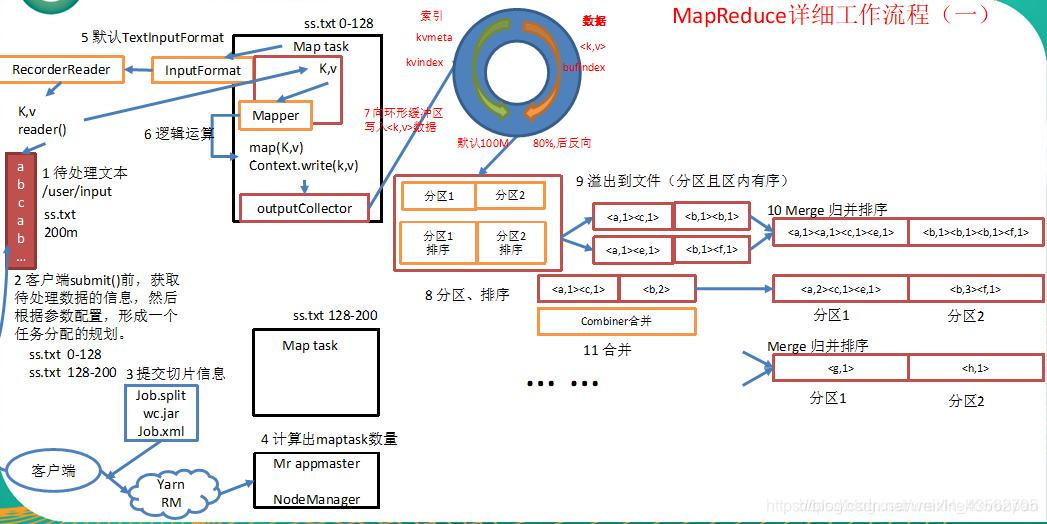
1.首先我们有一个待处理的文本ss.txt,大小为200m,假设要对这个文本中的内容进行单词统计。
2.在我们客户端提交之前,获取到待处理文本相关信息,根据block块的大小划分出具体的切片信息(默认集群中的块大小是128m,所以这里将我们的待处理文本ss.txt划分为两个切片分别为0-128m和128-200m)。
3.客户端将切片信息和jar包提交到yarn集群ResourceManager上。
4.ResourceManager将根据切片的个数决定开启多少个MapTask(一个MapTask处理一个切片)。
5.MapTask通过InputFormat(默认使用它的实现类TextInputFormat:将偏移量作为key,将一行数据作为value)来解析key/value对。将key/value对解析到map方法中。
6.在map方法中进行相应的逻辑处理,然后通过outputCollector写出到环形缓冲区。
7.当环形缓冲区数据达到80%以后,将会对数据进行分区、排序处理,然后溢出到文件。
8.可能会有多次溢出,将多次溢出的文件进行归并排序(可以使用Combiner来进行数据的汇总操作,来优化MapReduce减少IO流的传输)。形成一个大的有序文件。为下一阶段的reduce阶段拷贝数据做准备。
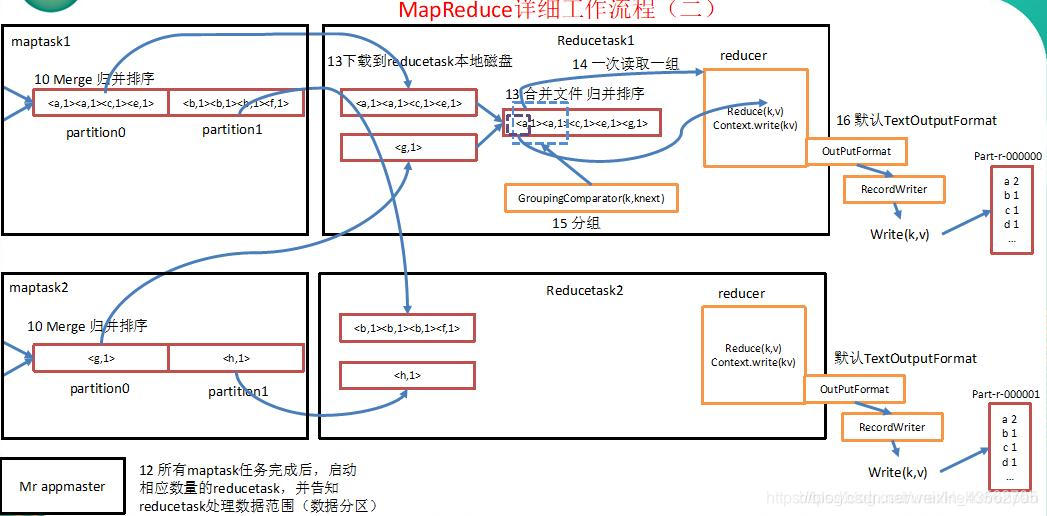
9.在reduce阶段,根据map阶段的分区个数,启动相应数量的ReduceTask。
10.将map处理后溢出到磁盘的结果从远程拷贝到ReduceTask本地磁盘(实际是内存中,内存不足时才溢写到磁盘)。
11.将多个MapTask中文件的相同分区(例如:MapTask1中的一号分区和MapTask2中的一号分区)的数据进行一次合并进行归并排序,合并为一个文件。
12.然后送入到reducer方法中。reduce方法进行相应的处理,然后进行写出到文件中(当然也可以自定义OutputFormat,按照自定义的格式写入到自定义的路径当中)。
注意:我特意仔细说明一哈shuffle的具体过程
1)maptask收集我们的map()方法输出的kv对,放到内存缓冲区中。
2)从内存缓冲区不断溢出本地磁盘文件,可能会溢出多个文件。
3)多个溢出文件会被合并成大的溢出文件。
4)在溢出过程中,及合并的过程中,都要调用partitioner进行分区和针对key进行排序。
5)reducetask根据自己的分区号,去各个maptask机器上取相应的结果分区数据。
6)reducetask会取到同一个分区的来自不同maptask的结果文件,reducetask会将这些文件再进行合并(归并排序)。
6.配置:同yarn一样
7.启动和端口:同yarn一样
四.Yarn
1.定义:
2.作用:
3.应用场景:
4.重要角色
5.工作流程:
6.配置:
①配置前准备
②配置yarn文件:
1.vi mapred-site.xml
<configuration>
<!--用于执行MapReduce作业的运行时框架-->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
[root@hry1 hadoop]#
2. vi yarn-site.xml
<configuration>
<!--配置resourcemanager的主机-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hry1</value>
</property>
<!--NodeManager上运行的附属服务-->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!--配置resourcemanager的scheduler的内部通讯地址-->
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>hry1:8030</value>
</property>
<!--配置resoucemanager的资源调度的内部通讯地址-->
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>hry1:8031</value>
</property>
<!--配置resourcemanager的内部通讯地址-->
<property>
<name>yarn.resourcemanager.address</name>
<value>hry1:8032</value>
</property>
<!--配置resourcemanager的管理员的内部通讯地址-->
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>hry1:8033</value>
</property>
<!--配置resourcemanager的web ui 的监控页面-->
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>hry1:8088</value>
</property>
</configuration>
3.把以上2个配置文件分发hry2和hry3上
4.启动:yarn-daemon.sh start resourcemanager和yarn-daemon.sh start nodemanager以及start-all.sh
7.启动和端口:
yarn-daemon.sh start resourcemanager和yarn-daemon.sh start nodemanager以及start-all.sh可以分别看到resourcemanager和nodemanager
五.hive
1.定义:
将结构化的数据映射成一张数据库表,提供了类sql语句,并能将语句翻译成MR,在hadoop框架中执行的数据仓库基础构架。关系型数据库《-----》hdfs/MapReduce
2.作用:
将结构化的数据映射成一张数据库表。
3.应用场景:
数据仓库
4.重要角色:
①hive的元数据:存在关系型数据库中。
②hive的数据:存在Hadoop的hdfs上。
③hive的计算:MapReduce。
5.hive和mysql关系与异同点:
①关系:hive元数据存在mysql中
②异同点:
| Hive | RDBMS | |
|---|---|---|
| 查询语言 | HQL | SQL |
| 数据存储 | HDFS | Raw Device or Local FS |
| 索引 | 无 | 有 |
| 执行 | MapReduce | Excutor |
| 执行延迟 | 高 | 低 |
| 处理数据规模 | 大 | 小 |
6.hive和hadoop关系:
①hive的数据:存在Hadoop的hdfs上。
②hive的计算:MapReduce。
7.hive的sql语句执行顺序
from–>on—>join---->where—>group by—>having—distribute by/cluster by–>sort by/order by—>select----->distinct---->order by—>limit—>union/union all
①join表连接方法:仅支持等值连接,不支持非等值的连接,分为左右内外连接4种:left/right [outer] join,其中left semi join 用于只能查询左表的数据,主要解决hive中数据是否存在的问题;用于两张表的连接。
②union联合方法:用于两个select的联合增加行数据。union去重排序,union all不去重不排序。不过注意点:但是使用union 和union all必须保证各个select的集合的结果有相同的个数的列,并且每个列的类型是一样的。
③where后边不能跟聚合函数和聚合函数的结果。
④having后面可以跟聚合函数和聚合函数的结果,并且常和group by连用。
⑤笛卡尔积:join 不加任何的on 或者where过滤条件、
⑥count:
count(*)包含了所有的列,相当于行数,在统计结果的时候不会忽略null值
count(1) 包含了所有的列,用1 代表代码行,在统计结果的时候不会忽略null值
count(col) 只包括列名那一列,在统计结果的时候会忽略null值,即某个字段为null值时,不统计
执行效率上:
列名为主键:count(col) 会比count(1)快
列名不为主键:count(1) 会比count(col)快
如果表有多个列,并且没有主键,count(1)要比count()快,如果有主键count(主键)最快
如果表里只有一个字段,count()最快
⑦分类:
distribute by:会对指定的字段按照hashcode值对reduce数量取模,然后将任务分配到对应的reduce中去执行
cluster by:distribute by和sort by合用就是cluster by ,但是cluster by不能指定排序,只能是升序 asc /desc(降序)
⑧排序:
sort by:局部排序,只保证单个reduce的数量
order by: 全局排序,保证所有的reduce内数据有序,如果是全局排序,reduce的数量只能是1个
⑨group by:hive和MySQL的group by表示含义不同,也就是说select 后面的字段必须先在group by后面出现才可以,但MySQL不必如此严格。
⑩键的区别:hive无键的说法,更不会有主键,外键,候选键,而MySQL就存在键。
8.hive的优化办法
①分区一定要加
②多表连接时使用相同的关键词
③减少每个阶段的数据量,只选出需要的,在join表前进行过滤
④map端join
⑤小表驱动大表
⑥本地模式
⑦严格模式
⑧limit的优化
⑨stage并行执行
⑩explain的执行计划
11.map,reduce个数设置
12.数据倾斜(order by,)
13.索引
14.视图
14.fetch抓取
15.jvm的重用
16.Union All insert
13.数据倾斜的原因:
①数据本身不均匀
②join
③group by
④count(distinct)
9.hive数据类型
①基本数据类型
| Hive数据类型 | Java数据类型 | 长度 | 例子 |
|---|---|---|---|
| TINYINT | byte | 1byte有符号整数 | 20 |
| SMALINT | short | 2byte有符号整数 | 20 |
| INT | int | 4byte有符号整数 | 20 |
| BIGINT | long | 8byte有符号整数 | 20 |
| BOOLEAN | boolean | 布尔类型,true或者false | TRUE FALSE |
| FLOAT | float | 单精度浮点数 | 3.14159 |
| DOUBLE | double | 双精度浮点数 | 3.14159 |
| STRING | string | 字符系列。可以指定字符集。可以使用单引号或者双引号。 | ‘now is the time’ “for all good men” |
| TIMESTAMP | 时间类型 | ||
| BINARY | 字节数组 |
对于Hive的String类型相当于数据库的varchar类型,该类型是一个可变的字符串,不过它不能声明其中最多能存储多少个字符,理论上它可以存储2GB的字符数。
② 集合数据类型
| 数据类型 | 描述 | 语法示例 |
|---|---|---|
| STRUCT | 和c语言中的struct类似,都可以通过“点”符号访问元素内容。例如,如果某个列的数据类型是STRUCT{first STRING, last STRING},那么第1个元素可以通过字段.first来引用。 | struct() |
| MAP | MAP是一组键-值对元组集合,使用数组表示法可以访问数据。例如,如果某个列的数据类型是MAP,其中键->值对是’first’->’John’和’last’->’Doe’,那么可以通过字段名[‘last’]获取最后一个元素 | map() |
| ARRAY | 数组是一组具有相同类型和名称的变量的集合。这些变量称为数组的元素,每个数组元素都有一个编号,编号从零开始。例如,数组值为[‘John’, ‘Doe’],那么第2个元素可以通过数组名[1]进行引用。 | Array() |
例子1:连接和联合的例子
create table if not exists a(id int,name string)
row format delimited
fields terminated by ','
;
load data local inpath '/root/a.txt' into table a;
create table if not exists b(id int,name string)
row format delimited
fields terminated by ','
;
load data local inpath '/root/b.txt' into table b;
查询:
select * from a inner join b on a.id=b.id;
select * from a left outer join b on a.id=b.id;
select * from a left semi join b on a.id=b.id;
select * from a,b where a.id>b.id;
select * from a right outer join b on a.id=b.id;
select * from a full outer join b on a.id=b.id;
select id,count(1) from a where id>1 group by id;
select id,count(1) as idcount from a where id>1 group by id having idcount>1;
select id,count(1) as idcount from a group by id having count(1) > 1;
select * from a where id>=1 union select * from b where id<=10;
select * from a where id>=1 union all select * from b where id<=10;
例子2:分区分桶的例子
create table if not exists dy_buc(
uid int,
uname string,
sex int
)
partitioned by (Ssex int)
clustered by (uid) into 4 buckets
row format delimited
fields terminated by ','
;///////注意分区是逻辑概念,不占用字段,所以考虑时设置非字段名即可。
create table if not exists dy_buc1(
uid int,
uname string,
sex int
)
row format delimited
fields terminated by ','
lines terminated by '\n'
;
load data local inpath '/root/stu.txt' into table dy_buc1;
insert overwrite table dy_buc partition(Ssex=1) select * from dy_buc1 cluster by (uid);
select * from dy_buc tablesample(bucket 1 out of 4);
例子3:(数组)
河北 石家庄
河北 保定
河北 邯郸
河北 张家口
河北 北戴河
江西 南昌
江西 九江
江西 赣州
江西 鹰潭
江西 井冈山[
create table if not exists arr(provicens string,city array<string>)
row format delimited
fields terminated by '\t'
;
load data local inpath '/root/arr' into table arr;
例子4:(数组)
河北:石家庄,保定,邯郸,张家口,北戴河
江西:南昌,九江,赣州,鹰潭,井冈山
create table if not exists arr1(provicens string,city array<string>)
row format delimited
fields terminated by ':'
collection items terminated by ','
;
load data local inpath '/root/arr1' into table arr1;
select * from arr1;
select explode(city) as scity from arr1;
select provicens, scity
from arr1
lateral view explode(city) city as scity
;
例子5:(map)
某蓉|皮鞭:2,蜡烛:1,手铐:1
宋吉吉|红酒:1,花生米:2,皮皮虾:10
王强|皮鞭:2,蜡烛:1,手铐:1
create table if not exists map1(
uname string,
itemids map<string,int>
)
row format delimited
fields terminated by '|'
collection items terminated by ','
map keys terminated by ':'
;
load data local inpath '/root/map' into table map1;
select * from map1;
某蓉 {"皮鞭":2,"蜡烛":1,"手铐":1}
宋吉吉 {"红酒":1,"花生米":2,"皮皮虾":10}
王强 {"皮鞭":2,"蜡烛":1,"手铐":1}
Time taken: 0.237 seconds, Fetched: 3
select uname,size(itemids) from map1;
某蓉 3
宋吉吉 3
王强 3
select uname,
map_keys(itemids),
map_values(itemids)
from map1;
某蓉 ["皮鞭","蜡烛","手铐"] [2,1,1]
宋吉吉 ["红酒","花生米","皮皮虾"] [1,2,10]
王强 ["皮鞭","蜡烛","手铐"] [2,1,1]
select explode(itemids) as (itemName,num) from map1;<==>select explode(itemids) from map1;
皮鞭 2
蜡烛 1
手铐 1
红酒 1
花生米 2
皮皮虾 10
皮鞭 2
蜡烛 1
手铐 1
select uname,itemName,itemNum from map1 lateral view explode(itemids) itemids1 as itemName,itemNum;
某蓉 皮鞭 2
某蓉 蜡烛 1
某蓉 手铐 1
宋吉吉 红酒 1
宋吉吉 花生米 2
宋吉吉 皮皮虾 10
王强 皮鞭 2
王强 蜡烛 1
王强 手铐 1
例子6:(struct)
贾静雯:台湾省,台北市,台中区,英皇大道11号
高圆圆:北京市,北京市,朝阳区,北京大酒店
create table if not exists struct1(uname string,
addr struct<provicens:string,city:string,area:string,street:string>
)
row format delimited
fields terminated by ':'
collection items terminated by ','
;
load data local inpath '/root/struct' into table struct1;
select * from struct1;
注意:explode只能用于map和array,不能用于struct
例子7:窗口函数(本质就是记录上一次和当前次)
2019-03-30 冯鹏 97
2019-03-30 司翔 96
2019-03-30 廉德枫 95
2019-03-30 王鑫 94
2019-03-30 胡浩洋 93
2019-03-30 刘浩(小) 93
2019-03-30 孙湘钦 93
2019-03-30 霍鹏飞 93
2019-03-30 毕传鑫 93
2019-03-30 韩冬 92
2019-03-30 刘旭 92
2019-03-30 杨佳星 92
2019-03-30 马关军 90
2019-03-30 葛军 90
2019-03-30 李晶辉 90
2019-03-30 王钊 89
2019-03-30 夏军 88
2019-03-30 施胜秋 88
2019-03-30 刘浩(大) 88
2019-03-30 任荣 88
2019-03-30 高亚楠 87
2019-03-30 齐承博 87
2019-03-30 孙洁 86
2019-03-30 路建才 86
2019-03-30 杜颢 86
2019-03-30 刘增辉 86
2019-03-30 冯惠臣 86
2019-03-30 李壮壮 85
2019-03-30 丁金辉 85
2019-03-30 李超然 85
2019-03-30 史昌盛 85
2019-03-30 曹猛 85
2019-03-30 唐晓康 85
2019-03-30 吴逸男 85
2019-03-30 戴晓浩 83
2019-03-30 杨航天 83
2019-03-30 胡剑峰 82
2019-03-30 刘秀杰 81
2019-03-30 段元淳 80
2019-03-30 宋振玺 78
2019-03-30 丁利飞 78
2019-03-30 陈鹏 76
2019-03-30 黄嵩 75
2019-03-30 王留香 74
2019-03-30 暴志鹏 73
2019-03-30 陶尧尧 70
2019-03-30 周志舵 61
2019-03-30 孔祥托 60
2019-03-23 胡浩洋 98
2019-03-23 司翔 98
2019-03-23 孙洁 98
2019-03-23 夏军 98
2019-03-23 高亚楠 96
2019-03-23 王鑫 95
2019-03-23 王钊 95
2019-03-23 戴晓浩 94
2019-03-23 路建才 94
2019-03-23 史翼璇 94
2019-03-23 杜颢 93
2019-03-23 冯鹏 93
2019-03-23 刘浩(小) 93
2019-03-23 孙湘钦 93
2019-03-23 霍鹏飞 92
2019-03-23 李壮壮 92
2019-03-23 丁金辉 91
2019-03-23 韩冬 91
2019-03-23 李超然 91
2019-03-23 史昌盛 91
2019-03-23 段元淳 90
2019-03-23 胡剑峰 90
2019-03-23 陈鹏 89
2019-03-23 施胜秋 88
2019-03-23 王留香 88
2019-03-23 毕传鑫 87
2019-03-23 曹猛 86
2019-03-23 廉德枫 86
2019-03-23 刘浩(大) 86
2019-03-23 马关军 86
2019-03-23 齐承博 86
2019-03-23 唐晓康 86
2019-03-23 刘旭 85
2019-03-23 周志舵 84
2019-03-23 葛军 83
2019-03-23 宋振玺 83
2019-03-23 刘增辉 82
2019-03-23 黄嵩 80
2019-03-23 孔祥托 80
2019-03-23 任荣 80
2019-03-23 吴逸男 79
2019-03-23 杨佳星 78
2019-03-23 暴志鹏 76
2019-03-23 丁利飞 76
2019-03-23 李晶辉 76
2019-03-23 杨航天 76
2019-03-23 冯惠臣 73
2019-03-23 刘秀杰 73
create table if not exists window1(
dt string,
name string,
score int
)
row format delimited
fields terminated by '\t'
;
load data local inpath /root/window' into table window1;
select * from window1;
//进行排序
select *,
row_number() over(distribute by dt sort by score desc) rm,
rank() over(distribute by dt sort by score desc) rk,
dense_rank() over(distribute by dt sort by score desc) drk
from window1
;
//求每次考试的最高分和最低分
select dt,max(score),min(score) from window1 group by dt;
//每次考试每位学员的成绩与最高成绩的差值
select dt,name, score,max(score) over(distribute by dt sort by score desc) maxscore from window1;
//求第一次和最后一次的分数
select
dt,
name,
score,
first_value(score) over(distribute by dt sort by score desc) maxscore,
last_value(score) over(distribute by dt sort by score asc) minscore
from window1
;
例子8:
create table if not exists window2(uid int,class string,score double)
row format delimited
fields terminated by ','
;
load data local inpath '/root/over.txt' into table window2;
select * from window2;
select * ,row_number() over(distribute by class sort by score desc) rn from window2;
select * ,rank() over(distribute by class sort by score desc) rn from window2;
select * ,dense_rank() over(distribute by class sort by score desc) rn from window2;
select *,max(score) over(distribute by class sort by score desc) maxscore from window2;
select *,max(score) over(distribute by class sort by score desc) maxscore from window2;
select *,
first_value(score) over(distribute by class sort by score desc) maxscore,
last_value(score) over(distribute by class sort by score asc) minscore from window2;
select *,
lag(score,1) over(distribute by class sort by score asc) as upscore,
lead(score,1) over(distribute by class sort by score asc) as downscore
from window2;
10.hive的增删改查的操作
❶库
①增
⑴
create database db_hive;
⑵
create database if not exists db_hive;
⑶
create database db_hive2 location ‘/db_hive2.db‘;
②删:
⑴
drop database db_hive;
⑵
drop database if exists db_hive2;
⑶
drop database db_hive cascade(数据库不为空!);
③改:
alter database db_hive set dbproperties(‘createtime‘=‘20170830‘);
④查
⑴
show databases;
⑵
show databases like ‘db_hive*‘;
⑶
show create database hb_hive;
⑷
desc database db_hive;
⑸
desc database extended db_hive;
⑤使用:
use db_hive;
❷表
表的分类:内部表,外部表,分区表和分桶表。
外部表和内部表的区别:
- 外部表:删除表时,只会删除元数据信息,而不对真实数据进行修改
- 内部表:也叫管理表,删除表时,会对元数据和真实数据一起删除。
①增
⑴内部表
create table if not exists t_user (
name string ,
address string );
⑵外部表
create external table if not exists t_user (
name string ,
address string );
⑶复制空表
create table t_user1 like t_user;
⑶分区表:意义(避免全表扫描,优化查询),特点是分区字段不在表中,是一种虚拟字段。
设置动态分区:set hive.exec.dynamic.partition=true;
设置动态分区严格模式:set hive.exec.dynamic.partition.mode=nostrict;注意默认是strict(至少有一个分区列是静态分区)。
1.
create table if not exists t_user (
name string ,
address string )
partitioned by (st string, type string)
;
2.
alter table t_user add if not exists partition(country='xxx'[, state='yyy']);
⑷分桶表:意义(方便取样,优化查询),其中分桶的字段是表中存在的,是真实的字段,实现原则是哈希取模而得。
开启分桶:set hive.enforce.bucketing=true;
create table if not exists t_user (
id int,
name string ,
address string)
clustered by(id) sorted by(name) into 4 buckets
;
②删
⑴删除分区:
alter table t_user drop if not exists partition(country='xxx'[, state='yyy']);
⑵删除表
drop table log;
(3)清空表:truncate table t_user;
③改
⑴修改表
alter table log_1 rename to log;
⑵修改字段名
alter table log change column ip myip string;
⑶添加字段、
add columns
alter table log add columns (
sex int ,
age int
)
⑷替换字段;相当于将之前的字段全部删除,重新添加新的
alter table log replace columns(
se int,
lang int
)
;
④查
⑴查看所有表:show tables;
⑵查看指定表:show table t_user;
⑶查看指定表的详细信息:describe table t_user;
(4)查看分区:show partitions day_part;
❸数据
①增
⑴本地覆盖加载数据:
load data local inpath '/data/students.txt' overwrite into table t_user;
⑵hdfs不覆盖加载数据:
load data inpath '/data/students.txt' into table t_user;
⑶不覆盖插入数据:
insert into table t_user
select * from t_stu
cluster by (sno)
;
⑷覆盖插入数据:
override into table t_user
select * from t_stu
cluster by (sno)
;
(5)分区表加载数据必须指定分区:
load data local inpath '/etc/profile' into table stu1 partition (province='beijing');
(6)指定分区插入数据:
insert into table dyp1 partition(year=2011,month,day)
select uid,commentid,recommentid,month,day
from
tmp
;
(7)指定分桶插入数据:
insert overwrite table t_user
select * from t_stu
cluster by (sno)
;
②清空表:
trunk table t_user;
③查看数据
(1)查看普通表数据
select * from t_uer;
(2)查看分区表的数据
select * from t_user where year=2019 and month=04;
(3)查看分桶表的数据:
select * from t_user tablesample(bucket 1 out of 1);
select * from t_user tablesample(3 rows);//查询3行数据
select * from t_user tablesample(20 percent);//查询20%的数据
select * from t_user tablesample(20k);//查询一定大小的数据 B,K,M,G,T,P
❹索引:目的(优化查询以及检索性能)
①创建索引:
create index t1_index on table tb_name1(name)
as 'org.apache.hadoop.hive.ql.index.compact.CompactIndexHandler' with deferred rebuild
in table t1_index_table;
②重建索引:
ALTER INDEX t1_index ON tb_name1 REBUILD;
③删除索引:
DROP INDEX IF EXISTS t1_index ON tb_name1;
④查询索引:
show index on tb_name1;
11.hive的窗口函数:
①应用场景
(1)用于分区排序
(2)动态Group By
(3)Top N
(4)累计计算
(5)层次查询
②常用的分析函数:
| 函数 | 含义 |
|---|---|
| rank() | 在窗口内,按照某一列排序,返回在窗口内的序号。 |
| row_number() | 返回在窗口内的行号。 |
| first_value(x) | 返回窗口内的第一个value,一般用法是窗口内数值排序,获取最大值。 |
| last_value(x) | 含义和first value相反。 |
| nth_value(x, offset) | 窗口内的第offset个数。 |
| lead(x,offset,defaut_value) | 窗口内x列某行之后offset行的值,如果不存在该行,则取default_value。 |
| lag(x,offset,defaut_value) | 窗口内x列某行之前offset行的值,如果不存在该行,则取default_value。 |
①排名函数:row_number(),rank(),dense_rank()与over连用
窗口函数中的排名函数
row_number:没有并列,相同名次顺序排
rank():有并列,相同名次空位
dense_rank:有并列相同名次不空位
eg:注意(可以使用partition by 代替distribute by ,但是需要用order by 排序)
select *,
row_number() over(distribute by class sort by score desc) rm,
rank() over(distribute by class sort by score desc) rk,
dense_rank() over(distribute by class sort by score desc) drk
from rstu
;
②最大值和最小值:max(…),min(…)和over连用
select
dt,
name,
score,
max(score) over(distribute by dt sort by score desc) maxscore,
min(score) over(distribute by dt sort by score ) minscore
from stu_score
;
③最近和第一个版本:first_value,last_value和over连用。、
select
dt,
name,
score,
first_value(score) over(distribute by dt sort by score desc) maxscore,
last_value(score) over(distribute by dt sort by score asc) minscore
from stu_score
;
④前n行,后n行:lag()取出前n行的数据,lead() 取出后n行的数据。
select
dt,
name,
score,
lag(score,1) over(distribute by name sort by dt asc) as upscore
lead(score,1) over(distribute by name sort by dt asc) as upscore
from stu_score
;
12.hive的自定义函数
- UDTF:一进多出函数,对于某个数据经过函数会产生多条记录,eg: explode
- UDF:一进一出函数,对于一个数据经过函数处理,还是一条数据 eg: to_date
- UDAF:多进一出函数,多条数据经过函数处理会聚合成一条数据 eg: count
- 详细查看官网:官网都有详细的文档,
运用步骤:
①书写一个继承UDF的自定义类,重写evulue
②add jar /root/mr_demo-1.0.jar;
③创建一个自定义的临时函数名:create temporary function myUpper as ‘hiveudf.FirstUDF’;其中hiveudf.FirstUDF是类的绝度路径。
④查看函数:show functions
⑤测试:select myupper(‘a’);
第一种:(只对当前session有效)
1、将编写好的UDF打包并上传到服务器,并将jar包添加到hive的class path中
hive> add jar /root/mr_demo-1.0.jar;
2、创建一个自定义的临时函数名
hive>create temporary function myUpper as ‘hiveudf.FirstUDF’;
3、测试
show functions
4、select myupper(‘a’);
第二种方式
1、将编写好的UDF打包并上传到服务器
2、写一个配置文件,将以下语句写入配置文件中
vi /root/hive-init
add jar /root/mr_demo-1.0.jar;
create temporary function myUpper1 as ‘hiveudf.FirstUDF’;
3、启动hive的时候指定启动配置
hive -i /root/hive-init
第三种方式:
1、将编写好的UDF打包并上传到服务器
2、在hive的安装目录下的bin目录下,创建一个文件,文件名字hiverc
将以下内容加入进来
add jar /root/mr_demo-1.0.jar;
create temporary function upp as ‘hiveudf.FirstUDF’;
3、启动hive
注意:hive必须与hdfs,MapReduce中的yarn合用,hdfs和yarn一起启动的方法start-all.sh
13.内置运算符
1.1关系运算符
| 运算符 | 类型 | 说明 |
|---|---|---|
| A = B | 所有原始类型 | 如果A与B相等,返回TRUE,否则返回FALSE |
| A == B | 无 | 失败,因为无效的语法。 SQL使用”=”,不使用”==”。 |
| A <> B | 所有原始类型 | 如果A不等于B返回TRUE,否则返回FALSE。如果A或B值为”NULL”,结果返回”NULL”。 |
| A < B | 所有原始类型 | 如果A小于B返回TRUE,否则返回FALSE。如果A或B值为”NULL”,结果返回”NULL”。 |
| A <= B | 所有原始类型 | 如果A小于等于B返回TRUE,否则返回FALSE。如果A或B值为”NULL”,结果返回”NULL”。 |
| A > B | 所有原始类型 | 如果A大于B返回TRUE,否则返回FALSE。如果A或B值为”NULL”,结果返回”NULL”。 |
| A >= B | 所有原始类型 | 如果A大于等于B返回TRUE,否则返回FALSE。如果A或B值为”NULL”,结果返回”NULL”。 |
| A IS NULL | 所有类型 | 如果A值为”NULL”,返回TRUE,否则返回FALSE |
| A IS NOT NULL | 所有类型 | 如果A值不为”NULL”,返回TRUE,否则返回FALSE |
| A LIKE B | 字符串 | 如 果A或B值为”NULL”,结果返回”NULL”。字符串A与B通过sql进行匹配,如果相符返回TRUE,不符返回FALSE。B字符串中 的””代表任一字符,”%”则代表多个任意字符。例如: (‘foobar’ like ‘foo’)返回FALSE,( ‘foobar’ like ‘foo _ _’或者 ‘foobar’ like ‘foo%’)则返回TURE |
| A RLIKE B | 字符串 | 如 果A或B值为”NULL”,结果返回”NULL”。字符串A与B通过java进行匹配,如果相符返回TRUE,不符返回FALSE。例如:( ‘foobar’ rlike ‘foo’)返回FALSE,(’foobar’ rlike ‘^f.*r$’ )返回TRUE。 |
| A REGEXP B | 字符串 | 与RLIKE相同。 |
1.2算术运算符
| 运算符 | 类型 | 说明 |
|---|---|---|
| A + B | 所有数字类型 | A和B相加。结果的与操作数值有共同类型。例如每一个整数是一个浮点数,浮点数包含整数。所以,一个浮点数和一个整数相加结果也是一个浮点数。 |
| A – B | 所有数字类型 | A和B相减。结果的与操作数值有共同类型。 |
| A * B | 所有数字类型 | A和B相乘,结果的与操作数值有共同类型。需要说明的是,如果乘法造成溢出,将选择更高的类型。 |
| A / B | 所有数字类型 | A和B相除,结果是一个double(双精度)类型的结果。 |
| A % B | 所有数字类型 | A除以B余数与操作数值有共同类型。 |
| A & B | 所有数字类型 | 运算符查看两个参数的二进制表示法的值,并执行按位”与”操作。两个表达式的一位均为1时,则结果的该位为 1。否则,结果的该位为 0。 |
| A|B | 所有数字类型 | 运算符查看两个参数的二进制表示法的值,并执行按位”或”操作。只要任一表达式的一位为 1,则结果的该位为 1。否则,结果的该位为 0。 |
| A ^ B | 所有数字类型 | 运算符查看两个参数的二进制表示法的值,并执行按位”异或”操作。当且仅当只有一个表达式的某位上为 1 时,结果的该位才为 1。否则结果的该位为 0。 |
| ~A | 所有数字类型 | 对一个表达式执行按位”非”(取反)。 |
1.3逻辑运算符
| 运算符 | 类型 | 说明 |
|---|---|---|
| A AND B | 布尔值 | A和B同时正确时,返回TRUE,否则FALSE。如果A或B值为NULL,返回NULL。 |
| A && B | 布尔值 | 与”A AND B”相同 |
| A OR B | 布尔值 | A或B正确,或两者同时正确返返回TRUE,否则FALSE。如果A和B值同时为NULL,返回NULL。 |
| A | B | 布尔值 | 与”A OR B”相同 |
| NOT A | 布尔值 | 如果A为NULL或错误的时候返回TURE,否则返回FALSE。 |
| ! A | 布尔值 | 与”NOT A”相同 |
1.4复杂类型函数
| 函数 | 类型 | 说明 |
|---|---|---|
| map | (key1, value1, key2, value2, …) | 通过指定的键/值对,创建一个map。 |
| struct | (val1, val2, val3, …) | 通过指定的字段值,创建一个结构。结构字段名称将COL1,COL2,… |
| array | (val1, val2, …) | 通过指定的元素,创建一个数组。 |
1.5对复杂类型函数操作
| 函数 | 类型 | 说明 |
|---|---|---|
| A[n] | A是一个数组,n为int型 | 返回数组A的第n个元素,第一个元素的索引为0。如果A数组为[‘foo’,‘bar’],则A[0]返回’foo’和A[1]返回”bar”。 |
| M[key] | M是Map<K, V>,关键K型 | 返回关键值对应的值,例如mapM为 {‘f’ -> ‘foo’, ‘b’ -> ‘bar’, ‘all’ -> ‘foobar’},则M[‘all’] 返回’foobar’。 |
| S.x | S为struct | 返回结构x字符串在结构S中的存储位置。如 foobar {int foo, int bar} foobar.foo的领域中存储的整数。 |
14.内置函数
2.1数学函数
| 返回类型 | 函数 | 说明 |
|---|---|---|
| BIGINT | round(double a) | 四舍五入 |
| DOUBLE | round(double a, int d) | 小数部分d位之后数字四舍五入,例如round(21.263,2),返回21.26 |
| BIGINT | floor(double a) | 对给定数据进行向下舍入最接近的整数。例如floor(21.2),返回21。 |
| BIGINT | ceil(double a), ceiling(double a) | 将参数向上舍入为最接近的整数。例如ceil(21.2),返回23. |
| double | rand(), rand(int seed) | 返回大于或等于0且小于1的平均分布随机数(依重新计算而变) |
| double | exp(double a) | 返回e的n次方 |
| double | ln(double a) | 返回给定数值的自然对数 |
| double | log10(double a) | 返回给定数值的以10为底自然对数 |
| double | log2(double a) | 返回给定数值的以2为底自然对数 |
| double | log(double base, double a) | 返回给定底数及指数返回自然对数 |
| double | pow(double a, double p) power(double a, double p) | 返回某数的乘幂 |
| double | sqrt(double a) | 返回数值的平方根 |
| string | bin(BIGINT a) | 返回二进制格式 |
| string | hex(BIGINT a) hex(string a) | 将整数或字符转换为十六进制格式 |
| string | unhex(string a) | 十六进制字符转换由数字表示的字符。 |
| string | conv(BIGINT num, int from_base, int to_base) | 将 指定数值,由原来的度量体系转换为指定的试题体系。例如CONV(‘a’,16,2),返回。参考:’1010′ http://dev.mysql.com/doc/refman/5.0/en/mathematical-functions.html#function_conv |
| double | abs(double a) | 取绝对值 |
| int double | pmod(int a, int b) pmod(double a, double b) | 返回a除b的余数的绝对值 |
| double | sin(double a) | 返回给定角度的正弦值 |
| double | asin(double a) | 返回x的反正弦,即是X。如果X是在-1到1的正弦值,返回NULL。 |
| double | cos(double a) | 返回余弦 |
| double | acos(double a) | 返回X的反余弦,即余弦是X,,如果-1<= A <= 1,否则返回null. |
| int double | positive(int a) positive(double a) | 返回A的值,例如positive(2),返回2。 |
| int double | negative(int a) negative(double a) | 返回A的相反数,例如negative(2),返回-2。 |
2.2收集函数
| 返回类型 | 函数 | 说明 |
|---|---|---|
| int | size(Map<K.V>) | 返回的map类型的元素的数量 |
| int | size(Array) | 返回数组类型的元素数量 |
2.3类型转换函数
| 返回类型 | 函数 | 说明 |
|---|---|---|
| 指定 “type” | cast(expr as ) | 类型转换。例如将字符”1″转换为整数:cast(’1′ as bigint),如果转换失败返回NULL。 |
2.4日期函数
| 返回类型 | 函数 | 说明 |
|---|---|---|
| string | from_unixtime(bigint unixtime[, string format]) | UNIX_TIMESTAMP参数表示返回一个值’YYYY- MM – DD HH:MM:SS’或YYYYMMDDHHMMSS.uuuuuu格式,这取决于是否是在一个字符串或数字语境中使用的功能。该值表示在当前的时区。 |
| bigint | unix_timestamp() | 如果不带参数的调用,返回一个Unix时间戳(从’1970- 01 – 0100:00:00′到现在的UTC秒数)为无符号整数。 |
| bigint | unix_timestamp(string date) | 指定日期参数调用UNIX_TIMESTAMP(),它返回参数值’1970- 01 – 0100:00:00′到指定日期的秒数。 |
| bigint | unix_timestamp(string date, string pattern) | 指定时间输入格式,返回到1970年秒数:unix_timestamp(’2009-03-20′, ‘yyyy-MM-dd’) = 1237532400 |
| string | to_date(string timestamp) | 返回时间中的年月日: to_date(“1970-01-01 00:00:00″) = “1970-01-01″ |
| string | to_dates(string date) | 给定一个日期date,返回一个天数(0年以来的天数) |
| int | year(string date) | 返回指定时间的年份,范围在1000到9999,或为”零”日期的0。 |
| int | month(string date) | 返回指定时间的月份,范围为1至12月,或0一个月的一部分,如’0000-00-00′或’2008-00-00′的日期。 |
| int | day(string date) dayofmonth(date) | 返回指定时间的日期 |
| int | hour(string date) | 返回指定时间的小时,范围为0到23。 |
| int | minute(string date) | 返回指定时间的分钟,范围为0到59。 |
| int | second(string date) | 返回指定时间的秒,范围为0到59。 |
| int | weekofyear(string date) | 返回指定日期所在一年中的星期号,范围为0到53。 |
| int | datediff(string enddate, string startdate) | 两个时间参数的日期之差。 |
| int | date_add(string startdate, int days) | 给定时间,在此基础上加上指定的时间段。 |
| int | date_sub(string startdate, int days) | 给定时间,在此基础上减去指定的时间段。 |
2.5条件函数
| 返回类型 | 函数 | 说明 |
|---|---|---|
| T | if(boolean testCondition, T valueTrue, T valueFalseOrNull) | 判断是否满足条件,如果满足返回一个值,如果不满足则返回另一个值。 |
| T | COALESCE(T v1, T v2, …) | 返回一组数据中,第一个不为NULL的值,如果均为NULL,返回NULL。 |
| T | CASE a WHEN b THEN c [WHEN d THEN e]* [ELSE f] END | 当a=b时,返回c;当a=d时,返回e,否则返回f。 |
| T | CASE WHEN a THEN b [WHEN c THEN d]* [ELSE e] END | 当值为a时返回b,当值为c时返回d。否则返回e。 |
2.6字符函数
| 返回类型 | 函数 | 说明 |
|---|---|---|
| int | length(string A) | 返回字符串的长度 |
| string | reverse(string A) | 返回倒序字符串 |
| string | concat(string A, string B…) | 连接多个字符串,合并为一个字符串,可以接受任意数量的输入字符串 |
| string | concat_ws(string SEP, string A, string B…) | 链接多个字符串,字符串之间以指定的分隔符分开。 |
| string | substr(string A, int start) substring(string A, int start) | 从文本字符串中指定的起始位置后的字符。 |
| string | substr(string A, int start, int len) substring(string A, int start, int len) | 从文本字符串中指定的位置指定长度的字符。 |
| string | upper(string A) ucase(string A) | 将文本字符串转换成字母全部大写形式 |
| string | lower(string A) lcase(string A) | 将文本字符串转换成字母全部小写形式 |
| string | trim(string A) | 删除字符串两端的空格,字符之间的空格保留 |
| string | ltrim(string A) | 删除字符串左边的空格,其他的空格保留 |
| string | rtrim(string A) | 删除字符串右边的空格,其他的空格保留 |
| string | regexp_replace(string A, string B, string C) | 字符串A中的B字符被C字符替代 |
| string | regexp_extract(string subject, string pattern, int index) | 通过下标返回正则表达式指定的部分。regexp_extract(‘foothebar’, ‘foo(.*?)(bar)’, 2) returns ‘bar.’ |
| string | parse_url(string urlString, string partToExtract [, string keyToExtract]) | 返回URL指定的部分。parse_url(‘http://facebook.com/path1/p.php?k1=v1&k2=v2#Ref1′, ‘HOST’) 返回:’facebook.com’ |
| string | get_json_object(string json_string, string path) | select a.timestamp, get_json_object(a.appevents, ‘ .eventname’) from log a; |
| string | space(int n) | 返回指定数量的空格 |
| string | repeat(string str, int n) | 重复N次字符串 |
| int | ascii(string str) | 返回字符串中首字符的数字值 |
| string | lpad(string str, int len, string pad) | 返回指定长度的字符串,给定字符串长度小于指定长度时,由指定字符从左侧填补。 |
| string | rpad(string str, int len, string pad) | 返回指定长度的字符串,给定字符串长度小于指定长度时,由指定字符从右侧填补。 |
| array | split(string str, string pat) | 将字符串转换为数组。 |
| int | find_in_set(string str, string strList) | 返回字符串str第一次在strlist出现的位置。如果任一参数为NULL,返回NULL;如果第一个参数包含逗号,返回0。 |
| array<array> | sentences(string str, string lang, string locale) | 将字符串中内容按语句分组,每个单词间以逗号分隔,最后返回数组。 例如sentences(‘Hello there! How are you?’) 返回:( (“Hello”, “there”), (“How”, “are”, “you”) ) |
| array<struct<string,double>> | ngrams(array<array>, int N, int K, int pf) | SELECT ngrams(sentences(lower(tweet)), 2, 100 [, 1000]) FROM twitter; |
| array<struct<string,double>> | context_ngrams(array<array>, array, int K, int pf) | SELECT context_ngrams(sentences(lower(tweet)), array(null,null), 100, [, 1000]) FROM twitter; |
15.内置的聚合函数(UDAF)
| 返回类型 | 函数 | 说明 |
|---|---|---|
| bigint | count(*) , count(expr), count(DISTINCT expr[, expr_., expr_.]) | 返回记录条数。 |
| double | sum(col), sum(DISTINCT col) | 求和 |
| double | avg(col), avg(DISTINCT col) | 求平均值 |
| double | min(col) | 返回指定列中最小值 |
| double | max(col) | 返回指定列中最大值 |
| double | var_pop(col) | 返回指定列的方差 |
| double | var_samp(col) | 返回指定列的样本方差 |
| double | stddev_pop(col) | 返回指定列的偏差 |
| double | stddev_samp(col) | 返回指定列的样本偏差 |
| double | covar_pop(col1, col2) | 两列数值协方差 |
| double | covar_samp(col1, col2) | 两列数值样本协方差 |
| double | corr(col1, col2) | 返回两列数值的相关系数 |
| double | percentile(col, p) | 返回数值区域的百分比数值点。0<=P<=1,否则返回NULL,不支持浮点型数值。 |
| array | percentile(col, array(p~1,\ [, p,2,]…)) | 返回数值区域的一组百分比值分别对应的数值点。0<=P<=1,否则返回NULL,不支持浮点型数值。 |
| double | percentile_approx(col, p[, B]) | Returns an approximate pth percentile of a numeric column (including floating point types) in the group. The B parameter controls approximation accuracy at the cost of memory. Higher values yield better approximations, and the default is 10,000. When the number of distinct values in col is smaller than B, this gives an exact percentile value. |
| array | percentile_approx(col, array(p~1, [, p,2_]…) [, B]) | Same as above, but accepts and returns an array of percentile values instead of a single one. |
| array<struct{‘x’,'y’}> | histogram_numeric(col, b) | Computes a histogram of a numeric column in the group using b non-uniformly spaced bins. The output is an array of size b of double-valued (x,y) coordinates that represent the bin centers and heights |
| array | collect_set(col) | 返回无重复记录 |
16.内置表生成函数(UDTF)
| 返回类型 | 函数 | 说明 |
|---|---|---|
| 数组 | explode(array a) | 数组一条记录中有多个参数,将参数拆分,每个参数生成一列。 |
| json_tuple | get_json_object 语句:select a.timestamp, get_json_object(a.appevents, ‘ .eventname’) from log a; json_tuple语句: select a.timestamp, b.* from log a lateral view json_tuple(a.appevent, ‘eventid’, ‘eventname’) b as f1, f2 |
17.配置:
①配置前准备:mysql安装,防火墙关闭,局部网搭建,ssh免密登录,时间同步
②配置mysql
安装mysql-5.6
1.解决依赖问题
yum -y install libaio.x86_64
yum -y install perl.x86_64
2.解决包冲突问题
rpm -e --nodeps mysql-libs-5.1.73-5.el6_6.x86_64
3.安装mysql服务端
rpm -ivh /data/MySQL-server-5.6.26-1.linux_glibc2.5.x86_64.rpm
4.安装mysql客户端
rpm -ivh /data/MySQL-client-5.6.26-1.linux_glibc2.5.x86_64.rpm
5.修改配置信息,添加: vi /etc/my.cnf
[mysql]
default-character-set=utf8
[mysqld]
character-set-server=utf8
lower_case_table_names=1 ##数据库名表名不区分大小写
6 .启动mysql服务:service mysql start
7 .执行/usr/bin/mysql_secure_installation,将/root/.mysql_secret记录的随机密码输入
8 .根据提示设置新密码
9 .使用新密码登录数据库创建mysql用户:
create user 'hive' identified by 'hive';
10.授权:
grant all privileges on *.* to 'hive'@'%' identified by 'hive' with grant option;
grant all privileges on *.* to 'hive'@'hry1' identified by 'hive' with grant option;
flush privileges; 刷新权限
11.创建数据库(两种方式)
1).使用hive用户创建数据库并指定编码
create database if not exists hive character set latin1
2).使用hive用户创建数据库并修改连接信息。
create database hive;
alter database hive character set latin1;
③配置hive
1.vi hive-site.xml
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive/warehouse</value>
</property>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://hry1:3306/hry?createDatabaseIfNotExist=true</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>hry</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>hry110</value>
<description>password to use against metastore database</description>
</property>
</configuration>
2.把mysql的驱动包拷贝到hive下lib路径下
3.分发到hry2和hry3上
4.服务端vi hive-site.xml
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive2/warehouse</value>
</property>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://hry1:3306/hry1?createDatabaseIfNotExist=true</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>hry</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>hry110</value>
</property>
</configuration>
5.客户端vi hive-site.xml
vi hive-site.xml
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>hive.metastore.uris</name>
<value>thrift://hry2:9083</value>
</property>
</configuration>
6.服务端启动: hive --service metastore &
7.客户端启动:hive命令进入hive命令编辑页面
18.启动和端口:
服务端启动 hive --service metastore &可以看到RunJar,客户端启动hive进入命令界面
19.Hive函数
①.内置运算符
①.1关系运算符
| 运算符 | 类型 | 说明 |
|---|---|---|
| A = B | 所有原始类型 | 如果A与B相等,返回TRUE,否则返回FALSE |
| A == B | 无 | 失败,因为无效的语法。 SQL使用”=”,不使用”==”。 |
| A <> B | 所有原始类型 | 如果A不等于B返回TRUE,否则返回FALSE。如果A或B值为”NULL”,结果返回”NULL”。 |
| A < B | 所有原始类型 | 如果A小于B返回TRUE,否则返回FALSE。如果A或B值为”NULL”,结果返回”NULL”。 |
| A <= B | 所有原始类型 | 如果A小于等于B返回TRUE,否则返回FALSE。如果A或B值为”NULL”,结果返回”NULL”。 |
| A > B | 所有原始类型 | 如果A大于B返回TRUE,否则返回FALSE。如果A或B值为”NULL”,结果返回”NULL”。 |
| A >= B | 所有原始类型 | 如果A大于等于B返回TRUE,否则返回FALSE。如果A或B值为”NULL”,结果返回”NULL”。 |
| A IS NULL | 所有类型 | 如果A值为”NULL”,返回TRUE,否则返回FALSE |
| A IS NOT NULL | 所有类型 | 如果A值不为”NULL”,返回TRUE,否则返回FALSE |
| A LIKE B | 字符串 | 如 果A或B值为”NULL”,结果返回”NULL”。字符串A与B通过sql进行匹配,如果相符返回TRUE,不符返回FALSE。B字符串中 的””代表任一字符,”%”则代表多个任意字符。例如: (‘foobar’ like ‘foo’)返回FALSE,( ‘foobar’ like ‘foo _ _’或者 ‘foobar’ like ‘foo%’)则返回TURE |
| A RLIKE B | 字符串 | 如 果A或B值为”NULL”,结果返回”NULL”。字符串A与B通过java进行匹配,如果相符返回TRUE,不符返回FALSE。例如:( ‘foobar’ rlike ‘foo’)返回FALSE,(’foobar’ rlike ‘^f.*r$’ )返回TRUE。 |
| A REGEXP B | 字符串 | 与RLIKE相同。 |
①.2算术运算符
| 运算符 | 类型 | 说明 |
|---|---|---|
| A + B | 所有数字类型 | A和B相加。结果的与操作数值有共同类型。例如每一个整数是一个浮点数,浮点数包含整数。所以,一个浮点数和一个整数相加结果也是一个浮点数。 |
| A – B | 所有数字类型 | A和B相减。结果的与操作数值有共同类型。 |
| A * B | 所有数字类型 | A和B相乘,结果的与操作数值有共同类型。需要说明的是,如果乘法造成溢出,将选择更高的类型。 |
| A / B | 所有数字类型 | A和B相除,结果是一个double(双精度)类型的结果。 |
| A % B | 所有数字类型 | A除以B余数与操作数值有共同类型。 |
| A & B | 所有数字类型 | 运算符查看两个参数的二进制表示法的值,并执行按位”与”操作。两个表达式的一位均为1时,则结果的该位为 1。否则,结果的该位为 0。 |
| A|B | 所有数字类型 | 运算符查看两个参数的二进制表示法的值,并执行按位”或”操作。只要任一表达式的一位为 1,则结果的该位为 1。否则,结果的该位为 0。 |
| A ^ B | 所有数字类型 | 运算符查看两个参数的二进制表示法的值,并执行按位”异或”操作。当且仅当只有一个表达式的某位上为 1 时,结果的该位才为 1。否则结果的该位为 0。 |
| ~A | 所有数字类型 | 对一个表达式执行按位”非”(取反)。 |
①.3逻辑运算符
| 运算符 | 类型 | 说明 |
|---|---|---|
| A AND B | 布尔值 | A和B同时正确时,返回TRUE,否则FALSE。如果A或B值为NULL,返回NULL。 |
| A && B | 布尔值 | 与”A AND B”相同 |
| A OR B | 布尔值 | A或B正确,或两者同时正确返返回TRUE,否则FALSE。如果A和B值同时为NULL,返回NULL。 |
| A | B | 布尔值 | 与”A OR B”相同 |
| NOT A | 布尔值 | 如果A为NULL或错误的时候返回TURE,否则返回FALSE。 |
| ! A | 布尔值 | 与”NOT A”相同 |
①.4复杂类型函数
| 函数 | 类型 | 说明 |
|---|---|---|
| map | (key1, value1, key2, value2, …) | 通过指定的键/值对,创建一个map。 |
| struct | (val1, val2, val3, …) | 通过指定的字段值,创建一个结构。结构字段名称将COL1,COL2,… |
| array | (val1, val2, …) | 通过指定的元素,创建一个数组。 |
①.5对复杂类型函数操作
| 函数 | 类型 | 说明 |
|---|---|---|
| A[n] | A是一个数组,n为int型 | 返回数组A的第n个元素,第一个元素的索引为0。如果A数组为[‘foo’,‘bar’],则A[0]返回’foo’和A[1]返回”bar”。 |
| M[key] | M是Map<K, V>,关键K型 | 返回关键值对应的值,例如mapM为 {‘f’ -> ‘foo’, ‘b’ -> ‘bar’, ‘all’ -> ‘foobar’},则M[‘all’] 返回’foobar’。 |
| S.x | S为struct | 返回结构x字符串在结构S中的存储位置。如 foobar {int foo, int bar} foobar.foo的领域中存储的整数。 |
②.内置函数
②.1数学函数
| 返回类型 | 函数 | 说明 |
|---|---|---|
| BIGINT | round(double a) | 四舍五入 |
| DOUBLE | round(double a, int d) | 小数部分d位之后数字四舍五入,例如round(21.263,2),返回21.26 |
| BIGINT | floor(double a) | 对给定数据进行向下舍入最接近的整数。例如floor(21.2),返回21。 |
| BIGINT | ceil(double a), ceiling(double a) | 将参数向上舍入为最接近的整数。例如ceil(21.2),返回23. |
| double | rand(), rand(int seed) | 返回大于或等于0且小于1的平均分布随机数(依重新计算而变) |
| double | exp(double a) | 返回e的n次方 |
| double | ln(double a) | 返回给定数值的自然对数 |
| double | log10(double a) | 返回给定数值的以10为底自然对数 |
| double | log2(double a) | 返回给定数值的以2为底自然对数 |
| double | log(double base, double a) | 返回给定底数及指数返回自然对数 |
| double | pow(double a, double p) power(double a, double p) | 返回某数的乘幂 |
| double | sqrt(double a) | 返回数值的平方根 |
| string | bin(BIGINT a) | 返回二进制格式 |
| string | hex(BIGINT a) hex(string a) | 将整数或字符转换为十六进制格式 |
| string | unhex(string a) | 十六进制字符转换由数字表示的字符。 |
| string | conv(BIGINT num, int from_base, int to_base) | 将 指定数值,由原来的度量体系转换为指定的试题体系。 |
| double | abs(double a) | 取绝对值 |
| int double | pmod(int a, int b) pmod(double a, double b) | 返回a除b的余数的绝对值 |
| double | sin(double a) | 返回给定角度的正弦值 |
| double | asin(double a) | 返回x的反正弦,即是X。如果X是在-1到1的正弦值,返回NULL。 |
| double | cos(double a) | 返回余弦 |
| double | acos(double a) | 返回X的反余弦,即余弦是X,,如果-1<= A <= 1,否则返回null. |
| int double | positive(int a) positive(double a) | 返回A的值,例如positive(2),返回2。 |
| int double | negative(int a) negative(double a) | 返回A的相反数,例如negative(2),返回-2。 |
②.2收集函数
| 返回类型 | 函数 | 说明 |
|---|---|---|
| int | size(Map<K.V>) | 返回的map类型的元素的数量 |
| int | size(Array) | 返回数组类型的元素数量 |
②.3类型转换函数
| 返回类型 | 函数 | 说明 |
|---|---|---|
| 指定 “type” | cast(expr as ) | 类型转换。例如将字符”1″转换为整数:cast(’1′ as bigint),如果转换失败返回NULL。 |
②.4日期函数
| 返回类型 | 函数 | 说明 |
|---|---|---|
| string | from_unixtime(bigint unixtime[, string format]) | UNIX_TIMESTAMP参数表示返回一个值’YYYY- MM – DD HH:MM:SS’或YYYYMMDDHHMMSS.uuuuuu格式,这取决于是否是在一个字符串或数字语境中使用的功能。该值表示在当前的时区。 |
| bigint | unix_timestamp() | 如果不带参数的调用,返回一个Unix时间戳(从’1970- 01 – 0100:00:00′到现在的UTC秒数)为无符号整数。 |
| bigint | unix_timestamp(string date) | 指定日期参数调用UNIX_TIMESTAMP(),它返回参数值’1970- 01 – 0100:00:00′到指定日期的秒数。 |
| bigint | unix_timestamp(string date, string pattern) | 指定时间输入格式,返回到1970年秒数:unix_timestamp(’2009-03-20′, ‘yyyy-MM-dd’) = 1237532400 |
| string | to_date(string timestamp) | 返回时间中的年月日: to_date(“1970-01-01 00:00:00″) = “1970-01-01″ |
| string | to_dates(string date) | 给定一个日期date,返回一个天数(0年以来的天数) |
| int | year(string date) | 返回指定时间的年份,范围在1000到9999,或为”零”日期的0。 |
| int | month(string date) | 返回指定时间的月份,范围为1至12月,或0一个月的一部分,如’0000-00-00′或’2008-00-00′的日期。 |
| int | day(string date) dayofmonth(date) | 返回指定时间的日期 |
| int | hour(string date) | 返回指定时间的小时,范围为0到23。 |
| int | minute(string date) | 返回指定时间的分钟,范围为0到59。 |
| int | second(string date) | 返回指定时间的秒,范围为0到59。 |
| int | weekofyear(string date) | 返回指定日期所在一年中的星期号,范围为0到53。 |
| int | datediff(string enddate, string startdate) | 两个时间参数的日期之差。 |
| int | date_add(string startdate, int days) | 给定时间,在此基础上加上指定的时间段。 |
| int | date_sub(string startdate, int days) | 给定时间,在此基础上减去指定的时间段。 |
②.5条件函数
| 返回类型 | 函数 | 说明 |
|---|---|---|
| T | if(boolean testCondition, T valueTrue, T valueFalseOrNull) | 判断是否满足条件,如果满足返回一个值,如果不满足则返回另一个值。 |
| T | COALESCE(T v1, T v2, …) | 返回一组数据中,第一个不为NULL的值,如果均为NULL,返回NULL。 |
| T | CASE a WHEN b THEN c [WHEN d THEN e]* [ELSE f] END | 当a=b时,返回c;当a=d时,返回e,否则返回f。 |
| T | CASE WHEN a THEN b [WHEN c THEN d]* [ELSE e] END | 当值为a时返回b,当值为c时返回d。否则返回e。 |
②.6字符函数
| 返回类型 | 函数 | 说明 |
|---|---|---|
| int | length(string A) | 返回字符串的长度 |
| string | reverse(string A) | 返回倒序字符串 |
| string | concat(string A, string B…) | 连接多个字符串,合并为一个字符串,可以接受任意数量的输入字符串 |
| string | concat_ws(string SEP, string A, string B…) | 链接多个字符串,字符串之间以指定的分隔符分开。 |
| string | substr(string A, int start) substring(string A, int start) | 从文本字符串中指定的起始位置后的字符。 |
| string | substr(string A, int start, int len) substring(string A, int start, int len) | 从文本字符串中指定的位置指定长度的字符。 |
| string | upper(string A) ucase(string A) | 将文本字符串转换成字母全部大写形式 |
| string | lower(string A) lcase(string A) | 将文本字符串转换成字母全部小写形式 |
| string | trim(string A) | 删除字符串两端的空格,字符之间的空格保留 |
| string | ltrim(string A) | 删除字符串左边的空格,其他的空格保留 |
| string | rtrim(string A) | 删除字符串右边的空格,其他的空格保留 |
| string | regexp_replace(string A, string B, string C) | 字符串A中的B字符被C字符替代 |
| string | regexp_extract(string subject, string pattern, int index) | 通过下标返回正则表达式指定的部分。regexp_extract(‘foothebar’, ‘foo(.*?)(bar)’, 2) returns ‘bar.’ |
| string | parse_url(string urlString, string partToExtract [, string keyToExtract]) | 返回URL指定的部分。parse_url(‘http://facebook.com/path1/p.php?k1=v1&k2=v2#Ref1′, ‘HOST’) 返回:’facebook.com’ |
| string | get_json_object(string json_string, string path) | select a.timestamp, get_json_object(a.appevents, ‘ .eventname’) from log a; |
| string | space(int n) | 返回指定数量的空格 |
| string | repeat(string str, int n) | 重复N次字符串 |
| int | ascii(string str) | 返回字符串中首字符的数字值 |
| string | lpad(string str, int len, string pad) | 返回指定长度的字符串,给定字符串长度小于指定长度时,由指定字符从左侧填补。 |
| string | rpad(string str, int len, string pad) | 返回指定长度的字符串,给定字符串长度小于指定长度时,由指定字符从右侧填补。 |
| array | split(string str, string pat) | 将字符串转换为数组。 |
| int | find_in_set(string str, string strList) | 返回字符串str第一次在strlist出现的位置。如果任一参数为NULL,返回NULL;如果第一个参数包含逗号,返回0。 |
| array<array> | sentences(string str, string lang, string locale) | 将字符串中内容按语句分组,每个单词间以逗号分隔,最后返回数组 |
| array<struct<string,double>> | ngrams(array<array>, int N, int K, int pf) | SELECT ngrams(sentences(lower(tweet)), 2, 100 [, 1000]) FROM twitter; |
| array<struct<string,double>> | context_ngrams(array<array>, array, int K, int pf) | SELECT context_ngrams(sentences(lower(tweet)), array(null,null), 100, [, 1000]) FROM twitter; |
③.内置的聚合函数(UDAF)
| 返回类型 | 函数 | 说明 |
|---|---|---|
| bigint | count(*) , count(expr), count(DISTINCT expr[, expr_., expr_.]) | 返回记录条数。 |
| double | sum(col), sum(DISTINCT col) | 求和 |
| double | avg(col), avg(DISTINCT col) | 求平均值 |
| double | min(col) | 返回指定列中最小值 |
| double | max(col) | 返回指定列中最大值 |
| double | var_pop(col) | 返回指定列的方差 |
| double | var_samp(col) | 返回指定列的样本方差 |
| double | stddev_pop(col) | 返回指定列的偏差 |
| double | stddev_samp(col) | 返回指定列的样本偏差 |
| double | covar_pop(col1, col2) | 两列数值协方差 |
| double | covar_samp(col1, col2) | 两列数值样本协方差 |
| double | corr(col1, col2) | 返回两列数值的相关系数 |
| double | percentile(col, p) | 返回数值区域的百分比数值点。0<=P<=1,否则返回NULL,不支持浮点型数值。 |
| array | percentile(col, array(p~1,\ [, p,2,]…)) | 返回数值区域的一组百分比值分别对应的数值点。0<=P<=1,否则返回NULL,不支持浮点型数值。 |
| double | percentile_approx(col, p[, B]) | 返回组中数值列(包括浮点类型)的近似pth百分位数 |
| array | percentile_approx(col, array(p~1, [, p,2_]…) [, B]) | 接受并返回百分位值数组 |
| array<struct{‘x’,'y’}> | histogram_numeric(col, b) | 使用b非均匀间隔的b in计算组中数值列的柱状图。输出是一个双值(x,y)坐标大小为b的数组 |
| array | collect_set(col) | 返回无重复记录 |
④.内置表生成函数(UDTF)
| 返回类型 | 函数 | 说明 |
|---|---|---|
| 数组 | explode(array a) | 数组一条记录中有多个参数,将参数拆分,每个参数生成一列。 |
| json_tuple | get_json_object 语句:select a.timestamp, get_json_object(a.appevents, ‘ .eventname’) from log a; json_tuple语句: select a.timestamp, b.* from log a lateral view json_tuple(a.appevent, ‘eventid’, ‘eventname’) b as f1, f2 |
六:hbase
1.HBASE的定义:
开源的,分布式和版本化。
2.hbase使用场景:
随机实时读写的情况。
3.hbase数据结构:
①行键(rowkey):按照字典顺序排序,最多存储64k。======》行键
②列族(column family):列族必须为表的模式定义的一部分,最多三个列族。
③时间戳(timestamp):用于区分版本。类型是64位整型。
④单元格(cell):单元格的内容是未解析的字节数组,cell中没有类型,全是字节码形式存在.
4.hbase的特点:
无模式,稀疏,多版本,列式存储。
5.hbase的体系结构:
思路线:client–>zookeeper–>hmaster—>hregionserver—>region–>store–>memstore和storefile
①client:负责与hmaster和hregionserver的通讯。
②zookeeper:负责监控hmaster的状态,主备选举(hmaster监控hregionserver的状态,然后hregionserver注册到zookeeper中)来记录root表。
③hmaster:管理用户对表的增删改查和管理hregionserver的负载均衡,调整region分布
④hregionserver:负责数据读写操作,管理region。
⑤region:默认大于10G时会进行切块;region由多个store组成。
⑥store:用于列族的存储,由memstore和storefile组成。
⑦memstore和storefile:写数据时先放入到memstore,并且写memstore时会进行日志的写入,防止数据的丢失(预写日志),然后再写入到storefile中(数量达到一定大小会进行合并(compact),再达到一定大小(默认10G大小)时会进行split)。
注意:
root表:就是meta表的索引,root表的位置信息存在ZK上,root表不会再拆分
meta表:存的是region的索引信息。
6.hbase与关系型数据库的关系:
| hbase非关系型数据库 | 关系型数据库 | |
|---|---|---|
| 存储方式 | 按列存储 | 按行存储 |
| 索引 | 数据就是索引 | 无索引查询,耗费大量IO,需要手动建立索引和视图 |
7.hbase寻址过程:
client–>Zookeeper–>-ROOT-表–>.META.表–>RegionServer–>Region–>client
8.hbase的rowkey的设计原则:
唯一原则:rowkey是按照字典顺序排序存储。
长度原则:不要超过16个字节。
散列原则:Rowkey是按时间戳的方式递增。
9.解决热点写入问题的方法:
反转写入方法,加盐写入方法和hash写入。
10.解决读取问题的方法:
①二级索引
②原表
③索引表rowkey设计:通过条件字段拼接
④数据:原表的rowkey。
⑤协处理器:相当于MySQL中触发器。
行键设计+二级索引配合使用来解决。
11.hbase的调优
①是否开启写日志
②是否立即刷写到磁盘
③关闭该关闭的对象,admin,hbaseadmin,htable…
④写数据的时候尽量批量去写入
⑤hbase的列族不要过多,2个就已经很多了。
⑥rowkey的设计越短越好
⑦将数据写入到缓存
12.hbase基本操作:
⑴常用命令:
开启hbase用start-hbase.sh 关闭hbase用stop-hbase.sh
①进入hbase的命令状态:hbase shell。
②退出hbase的命令状态:quit
③帮助:help《======》查看状态:status。
⑵DDL操作(数据定义)===>表的操作
❶命名空间(namespace)之操作
①查看帮助信息:help 'create_namespace’
②创建namespace:create_namespace 'nstest’
③删除namespace:drop_namespace 'nstest’
④修改命名空间:alter_namespace ‘ns1’, {METHOD => ‘set’, ‘GP_NAME’ => ‘GP1919’}
⑤描述查看namespace的结构:describe_namespace 'nstest’
⑥查看所有命名空间:list_namespace。
⑦list_namespace_tables ‘ns1’;
❷表之操作(DDL)
①创建表:必须指定列族名。其中列族名f1,f2和f3,命名空间ns1。
⑴create ‘ns1:t1’, {NAME => ‘f1’, VERSIONS => 5}
⑵create ‘stu_test’,'f1’
⑶create ‘t1’, ‘f1’, ‘f2’, 'f3’
(4)create ‘ns1:t1’,'f1’
②删除表:先禁用后删除(disable ‘t1’====>drop ‘t1’)
禁用disable, disable_all
启用enable, enable_all
③修改表:
alter ‘ns1:t_userinfo’,‘addr_info’ //增加一个列族
alter ‘t1’, ‘f1’, {NAME => ‘f2’, IN_MEMORY => true}, {NAME => ‘f3’, VERSIONS => 5}//修改列族属性
③查看表:list查看所有表。list ’t1‘ 查看t1表。
④查看表之描述:desc/describe ‘s1’
⑤检查表是否存在:exists ’t1’
(3)DML操作(数据管理)====》数据的操作
①数据的添加:put ‘ns1:t1’, ‘r1’, ‘c1’, ‘value’ 其中ns1命名空间,t1表名,r1是行键,c1是列族。
②删除
deleteall ‘ns1:t1’,'20170521_10003’
delete ‘ns1:t1’,‘20170521_10001’,'info:name’
③更新数据:
put ‘ns1:t_userinfo’,‘rk00001’,‘addr_info:name’,‘zhaomin’
put ‘ns1:t_userinfo’,‘rk00002’,‘addr_info:name’,‘taozi’
③查询数据:get ‘ns1:t1’, 'r1’
④扫描表:scan 'ns1:t1’
⑤表判断:exists ‘ns1:t_userinfo’
注意:hbase必须配合zookeeper,hdfs配合使用。
13.配置:
①配置前准备:jdk,zookeeper安装,ssh免密登录,时间同步,防火墙关闭,局域网搭建
②配置hbase文件:
1.vi hbase-env.sh
export JAVA_HOME=/apps/jdk1.8.0_60/
export HBASE_MANAGES_ZK=false//使用外部zookeeper
2.vi hbase-site.xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--
/**
*
* Licensed to the Apache Software Foundation (ASF) under one
* or more contributor license agreements. See the NOTICE file
* distributed with this work for additional information
* regarding copyright ownership. The ASF licenses this file
* to you under the Apache License, Version 2.0 (the
* "License"); you may not use this file except in compliance
* with the License. You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
-->
<configuration>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<property>
<name>hbase.rootdir</name>
<value>hdfs://hry1:9000/hbase</value>
</property>
<property>
<name>hbase.zookeeper.quorum</name>
<value>hry1,hry2,hry3</value>
</property>
<property>
<name>hbase.zookeeper.property.dataDir</name>
<value>/hbase/zookeeper</value>
</property>
</configuration>
3.配置全局变量vi /etc/profile
4.把hbase和profile文件分发到hry2和hry3上
5.加载etc/profile
6.启动zookeeper:zoozkServer.sh start
7.启动hdfs:start-dfs.sh
8.启动hbase:start-hbase.sh
9.网页测试:hry1:60010
14.启动和端口:
start-hbase.sh可以看到HMaster和HRegionServer
七:flume
1.定义:
是一个分布式、可靠、和高可用的海量日志采集、聚合和传输的系统。
2.作用:
用于收集数据。
3.应用场景:
海量数据的收集。
4.重要角色:
①:agent
用于采集数据,agent是flume中产生数据流的地方,同时,agent会将产生的数据流传输到collector,Agent由Source(完成对日志数据的收集)、Sink(ource提供中的数据进行简单的缓存)和Channel(Ø 取出Channel中的数据,进行相应的存储文件系统,数据库,或者提交到远程服务器)三大组件构成
Source类型:Avro ,Thrift ,Exec ,Spooling 等。
Channel类型:Memory(Event数据存储在内存中),JDBC (Event数据存储在持久化存储中),File(Event数据存储在内存中和磁盘上)。
sink类型:hdfs,logger,avro,thrift,hbase。
②:collector
collector的作用是将多个agent的数据汇总后,加载到storage中。
③:storage
storage是存储系统,可以是一个普通file,也可以是HDFS,HIVE,HBase等。
④:Master
Master是管理协调agent和collector的配置等信息,是flume集群的控制器。
在Flume中,最重要的抽象是data flow(数据流),data flow描述了数据从产生,传输、处理并最终写入目标的一条路径。
6.特性:可靠性,可扩展性,可管理性,功能可可扩展性。
6.配置:
①解压
②配置全局环境变量:
export FLUME_HOME=/data/sysdir/flume-distribution-0.9.4
export PATH=$PATH$FLUME_HOME/bin
③重载环境变量:source /etc/profile
④vi flume-env
export JAVA_HOME= /apps/jdk1.8.0_60/
④测试:flume-ng version
7.启动和端口:
8.应用案例:
八:sqoop
1.定义:
是用来实现结构型数据(如关系数据库)和Hadoop之间进行数据迁移的工具。
2.作用:
关系型数据库和Hadoop直接的数据迁移。
3.应用场景:
①关系型数据库 <—> hdfs
②关系型数据库 —> hive (逆向用sqoop不行)
③关系型数据库 —> hbase (逆向用sqoop不行)
4.优缺点:
优点:将跨平台的数据进行转移整合;扩展性还好,可以和oozie等进行结合。
缺点:命令不是很灵活;功能不是很丰富。sqoop 0.x 容易报错。
5.重要角色
①列出mysql的数据库:
sqoop list-databases --connect jdbc:mysql://hry1:3306/ \
-username hive-password hive \
;
②列出某个数据库下的表:
sqoop list-tables --connect jdbc:mysql://hry1:3306/ywp \
-username hive -password hive \
;
③将mysql中的数据导入到hdfs中:
-m 指定mapper数量,
--fields-terminated-by '\t' 指定分割
sqoop import --connect jdbc:mysql://hry1:3306/ywp \
-username hive -password hive -table 'hfile'
--target-dir '/sq/im/01' \
;
sqoop import --connect jdbc:mysql://hry1:3306/ywp \
-username hive -password hive -table 'hfile' -m 1 \
--fields-terminated-by '\t' --target-dir '/sq/im/03' \
;
④将mysql中的数据导入的hive表中:
sqoop import --connect jdbc:mysql://hry1:3306/ywp \
-username hive -password hive -table 'hfile' -m 1 \
--fields-terminated-by '\t' --lines-terminated-by '\n' \
--create-hive-table
--hive-import --hive-table 'qf1603.hfile1' \
;
sqoop import --connect jdbc:mysql://hry1:3306/ywp \
-username hive -password hive -table 'user' -m 1 \
--fields-terminated-by '\t' --lines-terminated-by '\n' \
--create-hive-table --hive-overwrite --hive-import \
--hive-table 'qf1603.squser4' --delete-target-dir \
--null-string '\\N' --null-non-string '\\N' \
;
⑤将mysql中指定的列导出到hdfs中:
-column ‘uid,uname,size’
sqoop import --connect jdbc:mysql://hry1:3306/ywp \
-username hive -password hive -table 'user' \
--fields-terminated-by '\t' --lines-terminated-by '\n' \
--columns 'uid,uname,size' --target-dir '/sq/im/06' \
--null-string '\\N' --null-non-string '\\N' \
;
⑥将mysql中指定过滤数据导入hdfs中:
–where ‘’
sqoop import --connect jdbc:mysql://hry1:3306/ywp \
-username hive -password hive -table 'user' -m 1 \
--fields-terminated-by '\t' --lines-terminated-by '\n' \
--columns 'uid,uname,size' --where 'uid%2=0' \
--target-dir '/sq/im/07' \
--null-string '\\N' --null-non-string '\\N' \
;
⑦指定复杂查询:
–query ‘’
Cannot specify --query and --table together.
Query [select uid,uname,size from user ] must contain ‘$CONDITIONS’ in WHERE clause
–where ‘uid%2=0’ \
sqoop import --connect jdbc:mysql://hry1:3306/ywp \
-username hive -password hive -m 1 \
--fields-terminated-by '\t' --lines-terminated-by '\n' --where 'uid%2=0' \
--query 'select uid,uname,size from user where $CONDITIONS' \
--target-dir '/sq/im/10' \
--null-string '\\N' --null-non-string '\\N' \
;
⑧–split-by ##通常和-m 搭配使用
sqoop import --connect jdbc:mysql://hry1:3306/ywp \
-username hive -password hive -m 2 --table 'user' \
--fields-terminated-by '\t' --lines-terminated-by '\n' --where 'uid%2=0' \
--columns "uid,uname" --split-by 'uid' \
--target-dir '/sq/im/11' \
--null-string '\\N' --null-non-string '\\N' \
;
9、将hdfs中的的数据导出到mysql中:
CREATE TABLE `user1` (
`uid` bigint(20) NOT NULL AUTO_INCREMENT,
`uname` varchar(45) DEFAULT NULL,
PRIMARY KEY (`uid`)
) ENGINE=InnoDB AUTO_INCREMENT=0 DEFAULT CHARSET=utf8;
sqoop export --connect jdbc:mysql://hry1:3306/ywp \
-username hive -password hive -m 1 --table 'user1' \
--fields-terminated-by '\t'
--lines-terminated-by '\n' \
--export-dir '/user/hive/warehouse/qf1603.db/user1' \
--input-null-string '\\N'
--input-null-non-string '\\N' \
;
6.数据整合本质:
将sqoop 命令转换mapreduce的job,然后进行数据的转移。
7.导入的方式:
①全量导入:
②增量导入:
8.配置
①解压配置环境变量
②mv ./conf/sqoop-env-template.sh ./conf/sqoop-env.sh
③配置文件:vi ./conf/sqoop-env.sh
vi sqoop-env.sh
export HADOOP_COMMON_HOME=/apps/hadoop-2.6.4/
export HADOOP_MAPRED_HOME=/apps/hadoop-2.6.4/
export HBASE_HOME=/apps/hbase-1.2.1/
export HIVE_HOME=/apps/hive-1.2.1/
export ZOOCFGDIR=/apps/zookeeper-3.4.5/ //高可用集群、hbase都需要依赖zookeeper,所有,如果是这两种情况之一,需要配置zookeeper的conf路径
④将mysql的驱动包导入到sqoop安装目录下的lib包下面
cp /home/mysql-connector-java-5.1.18.jar ./lib/
⑤需要把hive lib 包下面的hive-common-1.1.0-cdh5.13.2.jar和hive-exec-1.1.0-cdh5.13.2.jar r复制到sqoop lib 包下)
⑤启动测试:sqoop version或者sqoop help
9.启动和端口:
重点:
import : 从关系型数据库导入到hadoop
export : 从hadoop导出到关系型数据库
九:oozie
1.定义:
基于工作流引擎的服务器。
2.作用:
按照DAG(有向无环图)调度一系列的Map/Reduce或者Pig任务。
3.应用场景:
4.重要角色:
5.常用命令:
①oozied.sh start(后台执行) 或者 oozied.sh run (前台执行)
②oozied.sh stop 停止oozie
③export OOZIE_URL=http://hry1:11000/oozie 导出oozie的URL
④列出可用的包:oozie admin --shareliblist
⑤查看工作流是否可用:oozie validate workflow.xml
⑥查看oozie状态:oozie admin -oozie http:/hry1:11000/o ozie -status
⑦查看全部任务:oozie jobs
⑧提交任务,提交后的任务是prep状态
oozie job --oozie http://hry1:11000/oozie -config job.properties -submit
⑨运行提交的任务
oozie job -oozie http://hry1:11000/oozie -start jobid
⑩直接运行任务 running状态
oozie job --oozie http://hry1:11000/oozie -config job.properties -run
⑩重新运行任务
oozie job -oozie http://hry1:11000/oozie -config job.properties -rerun jobid
⑩暂停/挂起任务
oozie job -oozie http://hry1:11000/oozie -suspend jobid
⑩改变作业参数
oozie job -oozie http://hry1:11000/oozie -change jobid -value concurrency=1000;endtime=2012-12-01
⑩查看任务信息
oozie job -oozie http://hry:11000/oozie -info jobid
⑩查看任务日志
oozie job -oozie http://hry1:11000/oozie -log jobid
⑩提交MR任务
oozie mapreduce -oozie http://hry1:11000/oozie -config job.properties
⑩杀死任务
oozie job -oozie http://hry1:11000/oozie -kill jobid
杀死僵尸任务
kill掉,更新数据库(update wf_jobs set status=‘killed’ where id=‘jobid’)
6.配置:
下载oozie和ext-2.2.zip
1.上传至/bigdata下,解压至/apps
tar -zxvf /bigdata/oozie-4.1.0-cdh5.13.2.tar.gz -C /apps
2.配置环境变量
export OOZIE_HOME=/apps/oozie-4.1.0-cdh5.13.2
export PATH=$PATH:$OOZIE_HOME/bin
3.刷新环境变量
source /etc/profile
4.设置Oozie使用的数据库
这里提到的数据库是关系型数据库,用来存储Oozie的数据。Oozie自带一个Derby,
不过Derby只能拿来实验的,这里我选择mysql作为Oozie的数据库
mysql -uroot -p123456
create database oozie; ###可以不用创建oozie会自动生成
mysql>create user 'oozie' identified by 'oozie'
mysql>grant all privileges on oozie.* to 'oozie'@'localhost' identified by 'oozie' with grant option;
mysql>grant all privileges on oozie.* to 'oozie'@'%' identified by 'oozie' with grant option;
mysql>flush privileges;
5.编辑 oozie-site.xml 配置mysql的连接属性
rm -rf /apps/oozie-4.1.0-cdh5.13.2/conf/oozie-site.xml
将准备好的oozie-site.xml文件上传至/apps/oozie-4.1.0-cdh5.13.2/conf
6.可以在/apps/oozie-4.1.0-cdh5.13.2/conf/oozie-env.sh中进行参数修改,比如修改端口号,默认端口号为11000.
7.oozie根目录创建libext文件夹,复制mysql的driver压缩包到libext文件夹中,也可以做一个软连接(libext是lib的扩展目录,好多软件都有)
mkdir /apps/oozie-4.1.0-cdh5.13.2/libext
cp /apps/hive-1.1.0-cdh5.13.2/lib/mysql-connector-java-5.1.32.jar /apps/oozie-4.1.0-cdh5.13.2/libext
8.创建oozie需要的表结构
命令:ooziedb.sh create -sqlfile oozie.sql -run
9.使用mysql客户端查看是否生成oozie的数据库和表
10.设置hadoop代理用户。hadoop.proxyuser.root.hosts&hadoop.proxyuser.root.groups
vi /apps/hadoop-2.6.0-cdh5.13.2/etc/hadoop/core-site.xml
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>
启动或者重新启动HDFS+YARN
11.在hdfs上创建公用文件夹:
执行命令oozie-setup.sh sharelib create -fs hdfs://hadoop01:8020 -locallib /apps/oozie-4.1.0-cdh5.13.2/oozie-sharelib-4.1.0-cdh5.13.2-yarn.tar.gz
12.创建war文件(需安装unzip和zip yum-y install unzip;yum -y install zip)
执行addtowar.sh -inputwar $OOZIE_HOME/oozie.war -outputwar $OOZIE_HOME/oozie-server/webapps/oozie.war -hadoop 2.6.0 $HADOOP_HOME -jars $OOZIE_HOME/libext/mysql-connector-java-5.1.32.jar -extjs /bigdata/ext-2.2.zip
或者 将hadoop相关包,mysql相关包和ext压缩包放到libext文件夹中,运行oozie-setup.sh prepare-war也可以创建war文件
13.运行:oozied.sh run 或者 oozied.sh start(前者在前端运行,后者在后台运行)
14.jps 看见bootstrap说明oozie启动起来了###使用 oozied.sh stop 停止服务
15.查看web界面&查看状态oozie admin -oozie http://hadoop01:11000/oozie -status ##显示normal属于正常
16.web页面查看地址:http://hadoop01:11000/oozie
oozie-site.xml的配置
<?xml version="1.0"?>
<configuration>
<property>
<name>oozie.service.HadoopAccessorService.hadoop.configurations</name>
<value>*=/usr/local/hadoop-2.6.0-cdh5.13.2/etc/hadoop</value>
</property>
<property> <name>oozie.service.JPAService.create.db.schema</name>
<value>true</value>
</property>
<property>
<name>oozie.service.JPAService.jdbc.driver</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<property>
<name>oozie.service.JPAService.jdbc.url</name>
<value>jdbc:mysql://hry1:3306/oozie?createDatabaseIfNotExist=true</value>
</property>
<property>
<name>oozie.service.JPAService.jdbc.username</name>
<value>oozie</value>
</property>
<property>
<name>oozie.service.JPAService.jdbc.password</name>
<value>oozie</value>
</property>
<property>
<name>oozie.processing.timezone</name>
<value>GMT+0800</value>
</property>
</configuration>
7.启动和端口:oozied.sh run(前端启动)和oozied.sh start(后台启动),网页测试http://hry1:11000
十:kettle
1.定义:
是一款跨平台的纯Java开发的ETL工具。
2.作用:
数据库的数据导入到另外一个数据库中。
3.应用场景:
①表视图模式:这种情况我们经常遇到,就是在同一网络环境下,我们对各种数据源的表数据进行抽取、过滤、清洗等,例如历史数据同步、异构系统数据交互、数据对称发布或备份等都归属于这个模式;传统的实现方式一般都要进行研发(一小部分例如两个相同表结构的表之间的数据同步,如果sqlserver数据库可以通过发布/订阅实现),涉及到一些复杂的一些业务逻辑如果我们研发出来还容易出各种bug;
②前置机模式:这是一种典型的数据交换应用场景,数据交换的双方A和B网络不通,但是A和B都可以和前置机C连接,一般的情况是双方约定好前置机的数据结构,这个结构跟A和B的数据结构基本上是不一致的,这样我们就需要把应用上的数据按照数据标准推送到前置机上,这个研发工作量还是比较大的;
③文件模式: 数据交互的双方A和B是完全的物理隔离,这样就只能通过以文件的方式来进行数据交互了,例如XML格式,在应用A中我们开发一个接口用来生成标准格式的XML,然后用优盘或者别的介质在某一时间把XML数据拷贝之后,然后接入到应用B上,应用B上在按照标准接口解析相应的文件把数据接收过来;
4.重要角色:
①转换: 用来配置ETL 链路信息,及工作方式。
②作业: 用来启动和控制转换工作。
5.工作流程:
①转换使用教程:
(1)新建转换
(2)新建转换下建立DB连接用以连接数据库。
(3)核心对象下输入:新建表输入
(4)输入表书写sql语句
(5)输出:插入\更新
(6)选中输入表按住shift键拖动线条与输出表进行连接。注意这里可以进行数据的清洗功能。
(7)核心对象下的通用拖入start:设置定时或周期性的执行转换。
(8))核心对象下的通用拖入转换:点中转换输入转换名。
②kettle使用时间戳增量输出数据:通过触发器和时间戳两种方式进行增量输出数据。
6.配置:
①安装jdk。配置jdk的全局环境变量
②把mysql的驱动包导入到kettle的lib下面。
③Spoon.bat启动kettle
7.启动和端口:
Spoon.bat是windows启动,spoon.sh是Linux系统。
十一:数据建模
1.定义:powerdesigner,支持软件开发生命周期所有阶段的模型设计工作。
2.作用:用于对数据库建模工具
3.应用场景:对管理信息系统进行分析设计。
4.重要角色:
①概念模型CDM:表现数据库的全部逻辑的结构,与任何的软件或数据储藏结构无关。
②物理模型PDM:叙述数据库的物理实现。
③面向对象模型 (OOM):包含一系列包,类,接口 , 和他们的关系,本质上是静态的概念模型。
④业务程序模型 (BPM):描述业务的各种不同内在任务和内在流程
5.工作流程:
6.配置:
7.启动和端口:
十二:综合项目
1.定义:
2.作用:
3.应用场景:
4.重要角色
5.工作流程:
6.配置:
7.启动和端口: