上一节了解了主构造器、附属构造器。现在看一下父类和子类。
父类和子类
new 子类() 会先触发 new 父类()
子类 extends 父类
object ExtendsApp {
def main(args: Array[String]): Unit = {
val youngPerson = new YoungPerson("dashu","beijing",200.0f)
}
}
class YoungPerson(name:String,city:String,money:Float)
extends Person(name,city){ //定义一个子类YoungPerson,继承的是父类Person
println("YoungPerson enter....")
println("YoungPerson leave....")
}
class Person(val name:String,val city:String){ //父类
println("person enter....")
var age:Int =_
//附属构造器 第一行必须要调用主构造器或者其他附属构造器
def this(name:String,city:String,age:Int){
this(name,city)
this.age = age
}
println("person leave....")
}
运行结果:
person enter....
person leave....
YoungPerson enter....
YoungPerson leave....
Process finished with exit code 0
由此可知,new 子类() 会先触发 new 父类() ,所以从上面输出结果可以看出,先跑了父类的构造器,再跑了子类的构造器。
重写
Animal : eat
Dog eat
Cat eat
Pig eat
父类Animal定义了一个 吃
但子类 每个具体动物 吃的东西不一样,所以需要去重写父类的吃的方法。
重写:父类有一个方法,子类中也有一个一样的方法。
override 用来在子类中重写父类的方法或者属性。
调用的时候,默认走的是父类的方法,如果子类重写了,那么调用的就是子类的方法
object ExtendsApp {
def main(args: Array[String]): Unit = {
val youngperson = new YoungPerson("dashu","beijing",200.0f)
//默认走的是父类的方法,如果子类重写了,那么调用的就是子类的方法
println(youngperson.toString())
}
}
class YoungPerson(name:String,city:String,money:Float)
extends Person(name,city){
println("YoungPerson enter....")
override def toString() = "toString......"
println("YoungPerson leave....")
}
class Person(val name:String,val city:String){ //父类
println("person enter....")
var age:Int =_
//附属构造器 第一行必须要调用主构造器或者其他附属构造器
def this(name:String,city:String,age:Int){
this(name,city)
this.age = age
}
println("person leave....")
}
运行结果:
person enter....
person leave....
YoungPerson enter....
YoungPerson leave....
toString......
Process finished with exit code 0
在父类中并没有找到toString方法,Java最顶层是object,它里面就有toString方法。
如果把 override def toString() = “toString…” 这句话注释掉,那么在main方法中就会调用父类的方法,这里调用的是object的方法。注释掉这一行之后,运行结果如下:
person enter....
person leave....
YoungPerson enter....
YoungPerson leave....
com.ruozedata.bigdata.scala03.YoungPerson@643b1d11
Process finished with exit code 0
object中的toString方法如下:
public String toString() {
return getClass().getName() + "@" + Integer.toHexString(hashCode());
}
一般在框架中,都是定义一些接口,或者抽象类,并没有写具体的实现,具体的实现都是在子类中去实现。这样对于一个框架来说非常容易扩展。
抽象类
用关键字abstract修饰
①Class function 没有具体的实现
②抽象类不能直接new,而是通过子类(不能还是抽象的)来new
除了以上两个特点,抽象类和普通的类基本上没有什么区别,该做什么就做什么。
比如:
abstract class A{
def speak()
val name:String
}
抽象类定义和使用举例:
object AbstractApp {
def main(args: Array[String]): Unit = {
val a = new(B)
a.speak()
}
}
abstract class A{
def speak()
val name:String
}
class B extends A { //B继承A,并具体实现A,包括属性和方法
override def speak(): Unit = {
println("B speak.....")
}
val name = "xiaoming"
}
trait(类似Java中的接口)
Scala中的trait:基本上可以等同于Java中的接口
trait和抽象类一样,也不能new的
如果D是trait,C来继承它,可以这样写:
class D extends C 在Scala中第一个继承用extends,后面再继承的话都用with
如果D是trait,A是类,C来继承它,可以这样写:
class D extends A with D
但是不能这样写:
class D extends D with A //类写在前面,trait写在后面
extends后面跟的一定是抽象类吗?不是,也可以是trait
但是with后面跟的都是trait
abstract class A{
def speak()
val name:String
}
class B extends A {
override def speak(): Unit = {
println("B speak.....")
}
val name = "xiaoming"
}
trait C{ //定义一个trait
def c()
}
class D extends A with C {
override def c(): Unit = {
println("D jicheng C")
}
override def speak(): Unit = {
println("D extends A")
}
override val name: String = _
}
Scala之高阶函数(重要)
首先了解一下map
map可以理解为映射,就像曾经学的y = f(x) 这样的函数一样,x作用于函数f,结果变成了y。
如果对一个集合内的每个元素都做一个相同的操作,就可以理解为映射。
f:Int => B 这个Int指的是集合里面元素的类型
现在来看一个例子:
现在有一个集合:l 里面有9个元素1~9

object FunctionApp {
def main(args: Array[String]): Unit = {
val l = List(1,2,3,4,5,6,7,8,9) //这里暂时先把 l 理解为一个集合,里面有9个元素1~9
println( l.map((x:Int) => x*2) )
}
}
现在来看这行代码:l.map((x:Int) => x*2)
map 是对 l 集合里面的每个元素进行操作
(x:Int) 这个就是集合里面的每个元素 x这个名字可以随便写,Int这个指的是集合里元素的类型 (x:Int) 这个就是函数的入参 (就和 y = f(x) 这样的函数一样x是入参)
然后把入参(x:Int) 就是每一个元素 把它变成 x*2这个元素 就是每个元素乘以2
其实我感觉 l.map((x:Int) => x2) 这个就是使用map这个函数,对立面的每个元素,进行操作,操作是x2,操作完成后,拿出来就是乘以2的结果了。
上面运行的结果:
List(2, 4, 6, 8, 10, 12, 14, 16, 18)
Process finished with exit code 0
然后再看这个代码:l.map((x:Int) => x*2)
其实那个Int类型 Scala是可以自动推导出来的,
所以可以这样写:l.map((x) => x*2)
然后x的括号也可以去掉,所以可以这样写:
l.map(x => x*2) //可以很明显的看出来,是把里面的元素每个都乘以2
然后 还可以这样写:*l.map(_2)
这个下划线表示 l 集合里面的每一个元素
所以就可以这样了:
object FunctionApp {
def main(args: Array[String]): Unit = {
val l = List(1,2,3,4,5,6,7,8,9)
println( l.map(_*2) )
}
}
现在如果要求筛选出集合里面大于10的元素,如何筛选?
有个函数: filter(p: A => Boolean) 进来一个A,出来一个布尔型
比如进来一个 100,出来一个 100>0 ,100>0 的结果是true,那么结果就是true
源码里面对这个filter函数的描述是:Selects all elements of this $coll which satisfy a predicate 选择集合里面满足条件的元素
所以就可以这样筛选了:
l.map(_*2).filter(_ > 10)
这个其实就是链式编程
先用map对l集合里面的没个元素乘以2,然后再用filter对前面的结果进行筛选,大于10的。
object FunctionApp {
def main(args: Array[String]): Unit = {
val l = List(1,2,3,4,5,6,7,8,9)
println( l.map(_*2) )
println( l.map(_*2).filter(_ > 10) )
}
}
输出的结果为:
List(2, 4, 6, 8, 10, 12, 14, 16, 18)
List(12, 14, 16, 18)
Process finished with exit code 0
现在如果再进行筛选,取集合里前面2个元素呢?
有个 take(n: Int) 函数,就是取集合里面前n个元素。
所以:
object FunctionApp {
def main(args: Array[String]): Unit = {
val l = List(1,2,3,4,5,6,7,8,9)
//println( l.map((x:Int) => x*2) )
println( l.map(_*2) )
println( l.map(_*2).filter(_ > 10) )
println( l.map(_*2).filter(_ > 10).take(2) ) //take
}
}
运行结果:
List(2, 4, 6, 8, 10, 12, 14, 16, 18)
List(12, 14, 16, 18)
List(12, 14)
Process finished with exit code 0
那现在如果求两两相邻的数字加起来,求和,如何写?
List(1,2,3,4,5,6,7,8,9)
1+2+3+4+5+6+7+8+9=?
实现:
1+2=3
3+3=6
6+4=10
10+5=15
…
Scala中,两两操作,比如两两相加,可以借助于reduce这个函数。
reduce(op: (A1, A1) => A1) 进去两个值,进行一番操作后,出来一个值
相加的话就可以这样写了,
l.reduce( (x:Int,y:Int) => x+y) 进去x y 出来 x+y
在这基础上,可以简写:
l.reduce(_ + _)
再举例:
这个函数 l.reduceLeft((x:Int,y:Int) => x-y)
进行扩展之后可以这样:
l.reduceLeft((x:Int,y:Int) => {
println(x + “,” + y)
x-y
})
object FunctionApp {
def main(args: Array[String]): Unit = {
val l = List(1,2,3,4,5,6,7,8,9)
//l.reduceLeft((x:Int,y:Int) => x-y)
l.reduceLeft((x:Int,y:Int) => {
println(x + "," + y)
x-y
})
}
}
输出结果:
1,2
-1,3
-4,4
-8,5
-13,6
-19,7
-26,8
-34,9
Process finished with exit code 0
再看一个函数:
def fold[A1 >: A](z: A1)(op: (A1, A1) => A1): A1 = foldLeft(z)(op)
使用: l.fold(10)((x:Int,y:Int) => x-y)
有两个括号 两个参数
object FunctionApp {
def main(args: Array[String]): Unit = {
val l = List(1,2,3,4,5,6,7,8,9)
l.fold(10)((x:Int,y:Int) => x-y)
l.fold(10)((x:Int,y:Int) => {
println(x + "," + y)
x+y
})
}
}
运行结果:
10,1
11,2
13,3
16,4
20,5
25,6
31,7
38,8
46,9
Process finished with exit code 0
从上面可以看出,给了它一个初始值10,从10开始相加的。
另外对于集合 val l = List(1,2,3,4,5,6,7,8,9)
可以直接这样:
scala> val l = List(1,2,3,4,5,6,7,8,9)
l: List[Int] = List(1, 2, 3, 4, 5, 6, 7, 8, 9)
scala> l.max
res0: Int = 9
scala> l.min
res1: Int = 1
scala> l.sum
res2: Int = 45
scala> l.count(_ >3)
res3: Int = 6
scala>
高阶函数2
spark中Scala写的WordCount源码:
https://github.com/apache/spark/blob/master/examples/src/main/scala/org/apache/spark/examples/streaming/HdfsWordCount.scala
这个复杂一些:
List里面套 List:
val a = List(List(1,2),List(3,4),List(5,6),List(7,8))
再调用a.flatten 这个,效果如下:

然后
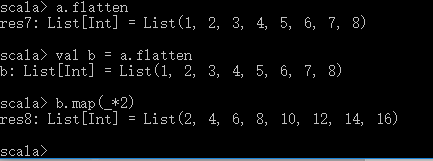
下面看这个函数:flatMap
flatMap ==等价于 flatten + map
val a = List(List(1,2),List(3,4),List(5,6),List(7,8))
a.flatMap(.map(*2))
_下划线 表示里面每个元素,每个元素都是一个List,先压扁,然后每个元素乘以2
效果如下:
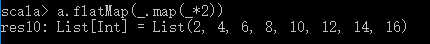
WordCount
现在假如有个List,这个List叫做line,List里面还是List
#line=
hello hello world
count china
hello count
love
val words = lines.flatMap(_.split(" "))
表示先把它压扁,压扁之后,按照空格进行分割,
这个操作之后变成这样:
#words =
hello hello world count china hello count love
words.map(x => (x, 1))
这个是对里面元素,每个元素赋上一个1,
变成了这样:
(hello,1) (hello,1) (world,1) (count,1) (china,1) (hello,1) (count,1) (love,1)
备注:做reduce的时候,入参是(key,<1,1,1…>),
按照上面就是reduce(hello,<1,1,1>) 输出的结果是 (hello,3)
reduceByKey(_ + _) 这个是根据相同的key进行相加求和
所以:
val wordCounts = words.map(x => (x, 1)).reduceByKey(_ + _)
输出结果就是:
(hello,4) (world,1) (count,2) (china,1)(love,1)
以上只是简单分析一下,后面还要详细进行分析。