参考资料:
本系列博客主要参考资料有CUUG冉乃纲老师数据库教学笔记,《SQL优化核心思想》(罗炳森,黄超,钟侥著),《PostgreSQL技术内幕:查询优化深度探索》(张树杰著),排名不分先后。
1 半连接和内连接转换
1.1 环境准备
create table tests1 as select * from dba_objects;
create table tests2 as select * from dba_objects;
1.2 问题SQL
EXPLAIN PLAN FOR SELECT DISTINCT A.OWNER
FROM tests1 A
WHERE A.OWNER IN (SELECT B.OWNER FROM tests2 B);
这条SQL在Oracle 11g环境下,如果没有收集统计信息,在我的电脑上是跑不出来结果的,是一条问题SQL。
1.3 原因分析
SQL很简单,为什么不出结果呢?首先我们看执行计划,

那么问题来了,我们的SQL是in查询,理论上是半连接,但是这里却是hash连接后去重复,优化器为什么这么做,我们稍后讨论,现在,为了解决问题,我们先把执行计划按照我们的想法调整一下。
第一招,我们加hint hash_sj,
EXPLAIN PLAN FOR SELECT DISTINCT A.OWNER
FROM tests1 A
WHERE A.OWNER IN (SELECT /*+ HASH_SJ(B)*/ B.OWNER FROM tests2 B);

结果是,并没有什么用。
第二招,SQL改写
WITH TMP AS
(SELECT A.OWNER
FROM tests1 A
WHERE A.OWNER IN (SELECT B.OWNER FROM tests2 B)
AND ROWNUM>0)
SELECT DISTINCT T.OWNER FROM TMP T ;
2秒内出结果,赶紧看执行计划,

Hash连接变成了哈希半连接,结果就秒出了,我们回想一下内连接和半连接的区别,就是hash半连接在连接列值有重复时不会翻倍,用下图说明
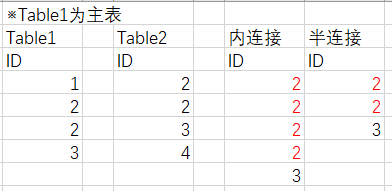
我们离问题原因越来越近了,就是连接列的值有重复,内连接后数据翻倍了,我们开始看连接列的值分布情况
SELECT T.OWNER,COUNT(*) CNT
FROM tests1 T
GROUP BY T.OWNER
ORDER BY CNT DESC;

tests2数据和tests1相同,很明显,数据列倾斜严重,sys用户的数据和public用户的数据如果走内连接,返回数据会非常庞大,问题就出在优化器把半连接改成了内连接。
那么问题又来了,优化器为什么这么做,关系数据库已经发展了很多年,也有完整的数学基础,像主流的大数据厂商不可能在优化器上乱来,之所以改,必有原因。
首先,我们最后返回的结果有distinct,这样优化器会先内连接两个表,最后结果去重,因为转换为内连接后,驱动表的选择会更加灵活。
虽然上面是执行计划改写的一个原因,但是优化器还是比较智能,并不会因为单纯因为上面的一个原因就会更改执行计划,执行计划被改写的比较差,还有一个重要原因是数据库统计信息过期,那么我们看看统计信息收集后执行计划会怎样。
BEGIN
DBMS_STATS.GATHER_TABLE_STATS(OWNNAME=>'SCOTT',
TABNAME=>'TESTS1',
ESTIMATE_PERCENT=>100,
METHOD_OPT=>'FOR COLUMNS OWNER SIZE SKEWONLY',
NO_INVALIDATE=>FALSE,
DEGREE=>1,
CASCADE=>TRUE);
END;
/
※TESTS2统计信息收集方法相同
统计信息收集后,结果秒出,执行计划变成了下面这样

执行计划先去重复,再hash连接,这就引出了另一个改写方法,就是先去重,再连接,既满足了驱动表选择的灵活性,还用去重减少了连接的成本,但是,去重是消耗成本的操作,结合具体情形使用。
1.4 优化方法
通过原因分析,我们得出了连接列重复值较多,优化器将半连接改内连接出现性能问题的优化方法有如下两种
1.4.1 SQL改写,改回半连接
改回原来的半连接,可以取消数据翻倍增长,参考原因分析,这里不再多说。
但是,网上有人说子查询加group by 也可以优化,但是我的实验环境并没有成功,具体如下
首先我们为了还原实验场景,删除统计信息
exec dbms_stats.delete_table_stats('SCOTT','TESTS1');
exec dbms_stats.delete_table_stats('SCOTT','TESTS2');
EXPLAIN PLAN FOR SELECT DISTINCT A.OWNER
FROM tests1 A
WHERE A.OWNER IN (SELECT B.OWNER FROM tests2 B GROUP BY B.OWNER);

1.4.2 先去重复,再内连接
首先,我们在子查询加distinct,
SELECT DISTINCT A.OWNER
FROM tests1 A
WHERE A.OWNER IN (SELECT DISTINCT B.OWNER FROM tests2 B);

期望满满,失望也是满满,优化器并没有按照我们所期待的改写执行计划。
那我们只能改写SQL,满足先去重,后连接。
SELECT DISTINCT A.OWNER
FROM (SELECT DISTINCT OWNER FROM TESTS1) A,
(SELECT DISTINCT OWNER FROM TESTS2) B
WHERE A.OWNER=B.OWNER;

视图合并了,还是不行,那我们用 NO_MERGE hint阻止视图合并。
SELECT DISTINCT A.OWNER
FROM (SELECT /*+ NO_MERGE*/ DISTINCT OWNER FROM TESTS1) A,
(SELECT /*+ NO_MERGE*/ DISTINCT OWNER FROM TESTS2) B
WHERE A.OWNER=B.OWNER;

千呼万唤,总算出来了,虽然优化成功,但是去重复操作可能加大查询成本。要结合具体场景使用。
1.5半连接消除
本章节,截止到目前,我们分析解决的是因为连接列倾斜较大产生时,半连接改为内连接所产生的数据翻倍问题,但是半连接消除,在一些场景下是优化改写,例如以下实验
首先我们建立索引
create index ix_tests1_id on tests1(object_id);
create index ix_tests2_id on tests2(object_id);
SELECT A.OWNER
FROM tests1 A
WHERE A.OBJECT_ID IN (SELECT B.OBJECT_ID
FROM tests2 B
where B.OWNER='SCOTT') ;

SELECT A.OWNER
FROM tests1 A ,
(SELECT DISTINCT t.OBJECT_ID
FROM tests2 t
where t.OWNER='SCOTT') B
WHERE A.OBJECT_ID = B.OBJECT_ID;

两种写法都对子查询去重复(sort unique和hash unique)后走了内连接,第一种是优化器自己改写,第二种是自己改写,虽然第二种写法比第一种写法看上去性能稍差一些,不同点在sort unique和hash unique上,此时的半连接改内连接,是优化改写。
本案例还有一个知识点,就是半连接反向驱动主表,因为半连接筛选后数据量较小,可以作为驱动的结果集,做嵌套循环。
1.6 总结
本章节总结如下:
(1)连接列数据倾斜较大,半连接改为内连接,数据翻倍,会产生性能瓶颈,改为原来的半连接数据量不会翻倍,可以改善性能;
(2)子查询数据量较小时,半连接消除,也就是把子查询去重复后再内连接,可与改善性能;
(3)如果能够确定子连接连接列的唯一性,可以写成内连接的方式,以满足内连接驱动表选择的灵活性(参考《PostgreSQL技术内幕:查询优化深度探索》 4.7 Semi Join消除)。
(4)子查询返回数据量较小时,可以让子查询的结果集驱动主表,实现性能优化。