sklearn是python机器学习最重要的库之一,用于数据挖掘,实现各种算法,sklearn框架概览。
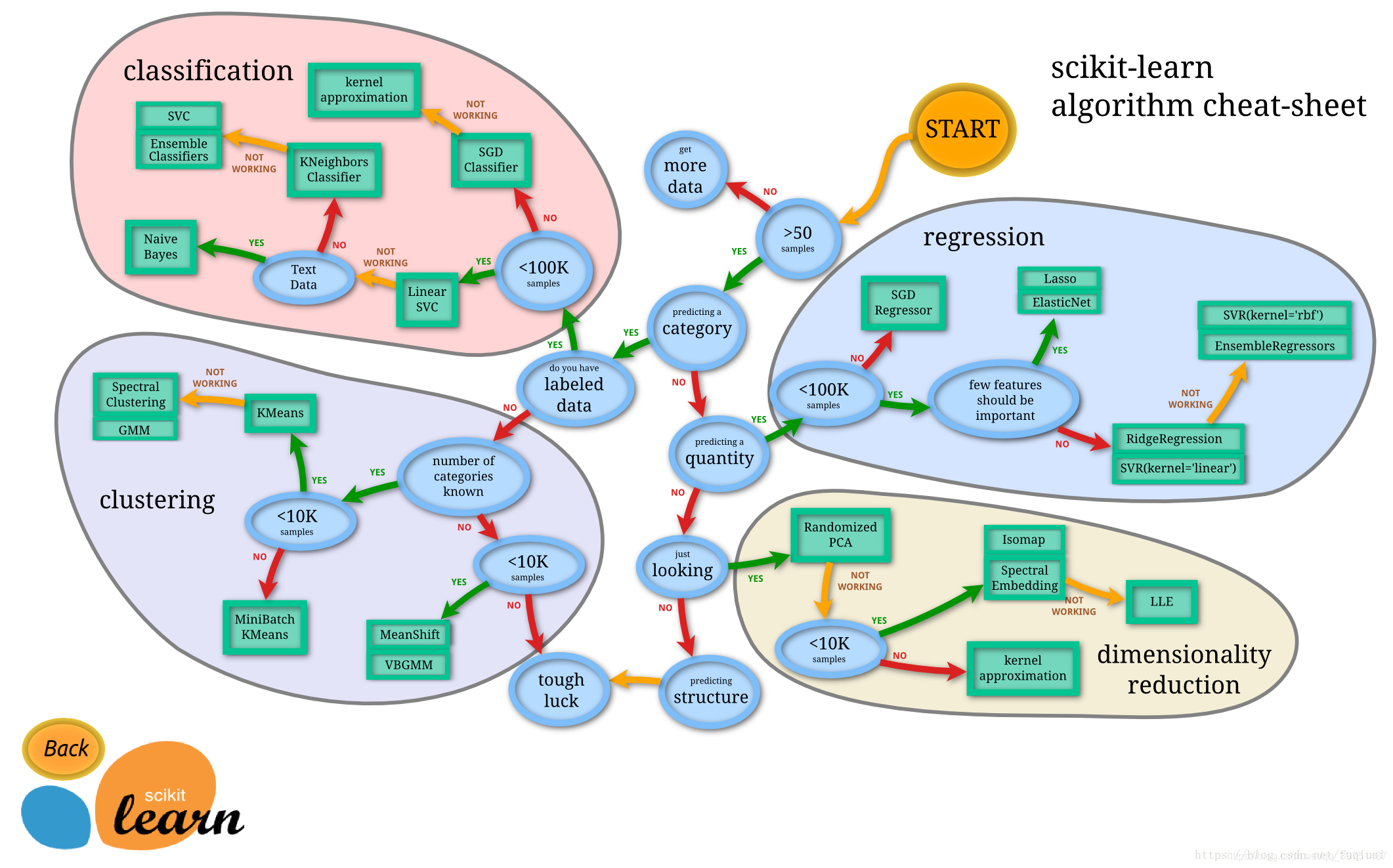
一、sklearn实现算法:
由图中,可以看到库的算法主要有四类:分类,回归,聚类,降维。其中:
- 常用的回归:线性、决策树、SVM、KNN ;集成回归:随机森林、Adaboost、GradientBoosting、Bagging、ExtraTrees
- 常用的分类:线性、决策树、SVM、KNN,朴素贝叶斯;集成分类:随机森林、Adaboost、GradientBoosting、Bagging、ExtraTrees
- 常用聚类:k均值(K-means)、层次聚类(Hierarchical clustering)、DBSCAN
- 常用降维:LinearDiscriminantAnalysis、PCA
二、机器学习主要步骤中sklearn应用
(1)导入数据集
一般数据集分为三种,sklearn自带的,通过方法加载;另一种sklearn可以生成数据;还有就是自己导入自己的数据集

(2)数据预处理/特征工程/数据可视化
数据可视化和特征工程,数据预处理都是数据部分最重要的操作,对于适配模型有重要的作用。
数据预处理包括:
- 降维(sklearn.decomposition)
- 缺失值处理
- 数据归一化(from sklearn import preprocessing)
- 数据集的标准化( preprocessing.StandardScaler().fit(traindata))
- 数据集拆分(from sklearn.mode_selection import train_test_split)
- 特征选择(sklearn.feature_selection)
- 特征转换(one-hot)等
这在sklearn里面有很多方法,具体查看api,一般有三种方法
fit():训练算法,设置内部参数。
transform():数据转换。
fit_transform():合并fit和transform两个方法。
主要在sklearn.preprcessing包下。
规范化:
- MinMaxScaler :最大最小值规范化
- Normalizer :使每条数据各特征值的和为1
- StandardScaler
:为使各特征的均值为0,方差为1
编码:
- LabelEncoder :把字符串类型的数据转化为整型
- OneHotEncoder :特征用一个二进制数字来表示
- Binarizer :为将数值型特征的二值化
- MultiLabelBinarizer:多标签二值化
(3)模型选择
根据数据来选择模型
常用的回归:线性、决策树、SVM、KNN ;集成回归:随机森林、Adaboost、GradientBoosting、Bagging、ExtraTrees
常用的分类:线性、决策树、SVM、KNN,朴素贝叶斯;集成分类:随机森林、Adaboost、GradientBoosting、Bagging、ExtraTrees
常用聚类:k均值(K-means)、层次聚类(Hierarchical clustering)、DBSCAN
常用降维:LinearDiscriminantAnalysis、PCA
model一般有两个属性:
fit():训练算法,设置内部参数。接收训练集和类别两个参数。
predict():预测测试集类别,参数为测试集。
(4)模型评估
交叉验证与模型评分
(from sklearn.model_selection import cross_val_score)
包:sklearn.cross_validation
KFold:K-Fold交叉验证迭代器。接收元素个数、fold数、是否清洗
LeaveOneOut:LeaveOneOut交叉验证迭代器
LeavePOut:LeavePOut交叉验证迭代器
LeaveOneLableOut:LeaveOneLableOut交叉验证迭代器
LeavePLabelOut:LeavePLabelOut交叉验证迭代器
常用方法
train_test_split:分离训练集和测试集(不是K-Fold)
cross_val_score:交叉验证评分,可以指认cv为上面的类的实例
cross_val_predict:交叉验证的预测。
处理过拟合问题
- 学习曲线from sklearn.model_selection import learning_curve
- 检验曲线from sklearn.model_selection import validation_curve
包:sklearn.metrics
sklearn.metrics包含评分方法、性能度量、成对度量和距离计算。
分类结果度量
参数大多是y_true和y_pred。
accuracy_score:分类准确度
condusion_matrix :分类混淆矩阵
classification_report:分类报告
precision_recall_fscore_support:计算精确度、召回率、f、支持率
jaccard_similarity_score:计算jcaard相似度
hamming_loss:计算汉明损失
zero_one_loss:0-1损失
hinge_loss:计算hinge损失
log_loss:计算log损失
回归结果度量
explained_varicance_score:可解释方差的回归评分函数
mean_absolute_error:平均绝对误差
mean_squared_error:平均平方误差
(5)模型保存
- 保存为pickle文件
# 保存模型
with open('model.pickle', 'wb') as f:
pickle.dump(model, f)
# 读取模型
with open('model.pickle', 'rb') as f:
model = pickle.load(f)
model.predict(X_test)
- sklearn自带方法joblib
from sklearn.externals import joblib
# 保存模型
joblib.dump(model, 'model.pickle')
#载入模型
model = joblib.load('model.pickle')
三、sklearn 使用技巧
(1)网格搜索
能够网格搜索最佳参数
包:sklearn.grid_search
网格搜索最佳参数
GridSearchCV:搜索指定参数网格中的最佳参数
ParameterGrid:参数网格
ParameterSampler:用给定分布生成参数的生成器
RandomizedSearchCV:超参的随机搜索
通过best_estimator_.get_params()方法,获取最佳参数。
代码示例
from sklearn import datasets,model_selection
iris=datasets.load_iris() # scikit-learn 自带的 iris 数据集
X=iris.data
y=iris.target
X_train,X_test,y_train,y_test=train_test_split(X,y,test_size=0.3,random_state=0)
alg=DecisionTreeClassifier()
parameters={'max_depth':range(1,100),'min_samples_split':range(2,30)}#参数空间
def fit_model(alg,parameters):
X= X_train
y= y_train
scorer=make_scorer(roc_auc_score)
grid = GridSearchCV(alg,parameters,scoring=scorer,cv=5)
grid = grid.fit(X,y)
print (grid.best_params_)
print (grid.best_score_)
return grid
fit_model(alg,parameters)
(2)流水线处理(Pipeline)
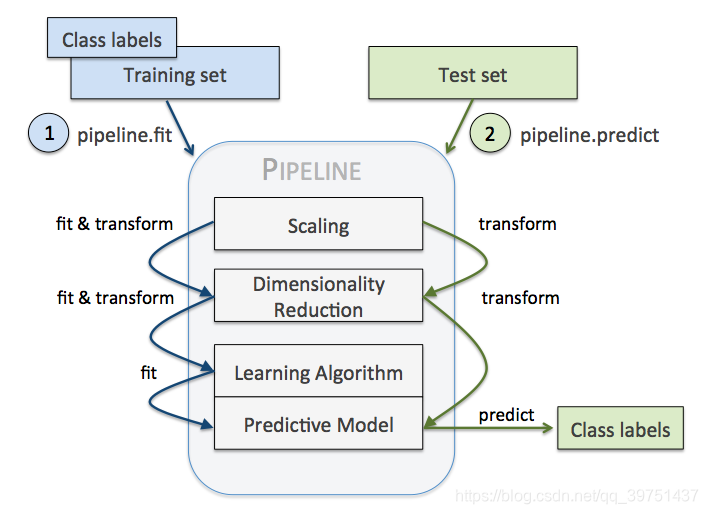
sklearn.pipeline包
流水线的功能与好处:
pipeline 实现了对全部步骤的流式化封装和管理,可以很方便地使参数集在新数据集上被重复使用。
跟踪记录各步骤的操作(以方便地重现实验结果)
对各步骤进行一个封装
确保代码的复杂程度不至于超出掌控范围
可以结合grid search对参数进行选择
直接调用fit和predict方法来对pipeline中的所有算法模型进行训练和预测。
基本使用方法
流水线的输入为一连串的数据挖掘步骤,其中最后一步必须是估计器,前几步是转换器。输入的数据集经过转换器的处理后,输出的结果作为下一步的输入。最后,用位于流水线最后一步的估计器(模型,有fit方法)对数据进行分类。
每一步都用元组( ‘名称’,步骤)来表示。现在来创建流水线。
from sklearn.pipeline import Pipeline
scaling_pipeline = Pipeline([
('scale', MinMaxScaler()),
('predict', KNeighborsClassifier())
(3)sklearn集成学习
sklearn集成学习有一些特别著名的集成方法,包括 bagging, boosting, stacking,能够实现模型融合,达到更好的效果。
详见我的另一篇集成学习博客