训练数据和测试数据的格式:
如上所示,”He reckons the current account deficit will narrow to only #1.8 billion in September .”代表一个训练句子xx,而CRF要求将这样的句子拆成每一个词一行并且是固定列数的数据,其中列除了原始输入,还可以包含一些其他信息,比如上面的例子第二列就包含了POS信息,最后一列是Label信息,也就是标准答案yy。而不同的训练序列与序列之间的相隔,就靠一个空白行来区分。
CRF训练的时候,要求我们提供特征模版,什么是特征模版呢,先来看如下图片:
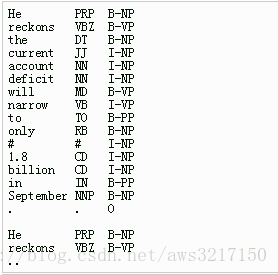
“%x[row, column]” 代表获得当前指向位置向上或向下偏移|row|行,并指向第column列的值。比如上图中,当前指向位置为 “the DT B-NP”,那么”%x[0,0]”代表获得当前指向偏移0行,第0列的值,也就是”the”,而”%x[0,1]”代表获得当前指向偏移0行,第1列的值,也就是”DT”,”%x[-2,1]”则代表获得当前指向向上偏移2行,第1列的值,也就是”PRP”,如此类推。
CRF中主要有两种特征模版,Unigram和Bigram 模版,注意Unigram和Bigram是相对于输出序列而言,而不是相对于输入序列。对于”U01:%x[0,1]”这样一个模版,上面例子的输入数据会产生如下的特征函数:
假如输出序列的集合大小为:LL,那么训练数据的每一行都会产生LL个特征函数,假如输入序列长度为NN,那么一个Unigram模版将会产生N∗LN∗L个特征函数。类似的,一个这样的Bigram模版”B01:%x[0,1]”,会考虑当前输出标签还有上一个输出标签,类似的会产生如下特征函数:
这样组合下将会产生N∗L∗LN∗L∗L个特征函数。



U模板, 状态特征, 即无向图中的点; 计算的cost即是其特征向量对应的权值
B模板, 转移特征, 即无向图中的边;(所谓转移指的是输出y的转移,而不是观测值x)
概率图中的每个节点, 每条边都对应着一个特征向量, 节点是U特征, 边是B特征
//将根据特征os,获取该特征的id,如果不存在该特征,生成新的id,将该id添加到feature变量中
private boolean buildFeatureFromTempl(List<Integer> feature, List<String> templs, int curPos, TaggerImpl tagger)
{
for (String tmpl : templs)
{
String featureID = applyRule(tmpl, curPos, tagger);
if (featureID == null || featureID.length() == 0)
{
System.err.println("format error");
return false;
}
//将提取的特征转化为数值,存入feature中,即feature代表一个节点(node或path)的特征向量
int id = getID(featureID);//获取该特征的id,如果不存在该特征,生成新的id
if (id != -1)
{
feature.add(id);
}
}
return true;
}
public boolean buildFeatures(TaggerImpl tagger)
{
List<Integer> feature = new ArrayList<Integer>();
List<List<Integer>> featureCache = tagger.getFeatureCache_();//存放是每个节点或者边对应的特征向量,节点便是node[i][j],边的概念后续会接触
tagger.setFeature_id_(featureCache.size());//做个标记,以后要取该句子的特征,可以从该id的位置取
for (int cur = 0; cur < tagger.size(); cur++)//遍历每个词,计算每个词的特征
{
if (!buildFeatureFromTempl(feature, unigramTempls_, cur, tagger))//函数根据当前词(cur)以及当前的特征(如: %x[-2,0]),生成一个特征向量feature
{
return false;
}
feature.add(-1);
featureCache.add(feature);//将该词的特征添加到feature_cache中,add方法会将feature拷贝一份并将最后添加-1,方便后续读取
feature = new ArrayList<Integer>();
}
for (int cur = 1; cur < tagger.size(); cur++)//遍历每条边,计算每条边的特征
{
if (!buildFeatureFromTempl(feature, bigramTempls_, cur, tagger))
{
return false;
}
feature.add(-1);
featureCache.add(feature);
feature = new ArrayList<Integer>();
}
return true;
}