41. Defer
Defer 被用来确保一个函数调用在程序执行结束前执行。同样用来执行一些清理工作。 defer 用在像其他语言中的ensure 和 finally用到的地方。
package main
import (
"os"
"fmt"
)
//假设我们想要创建一个文件,向它进行写操作,然后在结束时关闭它。
// 这里展示了如何通过 defer 来做到这一切。
func main() {
//假设我们想要创建一个文件,向它进行写操作,然后在结束时关闭它。
// 这里展示了如何通过 defer 来做到这一切。
f := createFile("C:/amyfile/defer.txt")
defer closeFile(f)
writeFile(f)
}
func createFile(p string) *os.File {
fmt.Println("creating")
f, err := os.Create(p)
if err != nil {
panic(err)
}
return f
}
func writeFile(f *os.File) {
fmt.Println("writing")
fmt.Fprintln(f, "data ok")
}
func closeFile(f *os.File) {
fmt.Println("closing")
f.Close()
}
执行结果如下图所示:
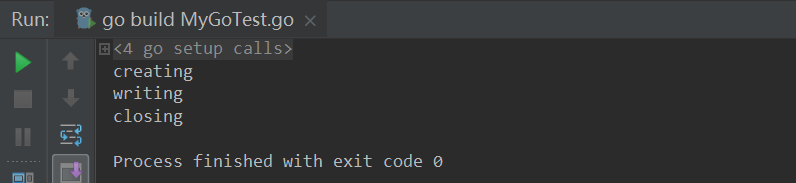
执行程序,确认这个文件在写入后是已关闭的。该目录下的数据也是写入成功的。

42. 组合函数
我们经常需要程序在数据集上执行操作,比如选择满足给定条件的所有项,或者将所有的项通过一个自定义函数映射到一个新的集合上。
在某些语言中,会习惯使用泛型。Go 不支持泛型,在 Go 中,当你的程序或者数据类型需要时,通常是通过组合的方式来提供操作函数。
这是一些 strings 切片的组合函数示例。你可以使用这些例子来构建自己的函数。注意有时候,直接使用内联组合操作代码会更清晰,而不是创建并调用一个帮助函数。
package main
import (
"fmt"
"strings"
)
//返回目标字符串 t 出现的的第一个索引位置,或者在没有匹配值时返回 -1。
func Index(vs []string, t string) int {
for i, v := range vs {
if v == t {
return i
}
}
return -1
}
//如果目标字符串 t 在这个切片中则返回 true。
func Include(vs []string, t string) bool {
return Index(vs, t) >= 0
}
//如果这些切片中的字符串有一个满足条件 f 则返回true。
func Any(vs []string, f func(string) bool) bool {
for _, v := range vs {
if f(v) {
return true
}
}
return false
}
//如果切片中的所有字符串都满足条件 f 则返回 true。
func All(vs []string, f func(string) bool) bool {
for _, v := range vs {
if !f(v) {
return false
}
}
return true
}
//返回一个包含所有切片中满足条件 f 的字符串的新切片。
func Filter(vs []string, f func(string) bool) []string {
vsf := make([]string, 0)
for _, v := range vs {
if f(v) {
vsf = append(vsf, v)
}
}
return vsf
}
//返回一个对原始切片中所有字符串执行函数 f 后的新切片。
func Map(vs []string, f func(string) string) []string {
vsm := make([]string, len(vs))
for i, v := range vs {
vsm[i] = f(v)
}
return vsm
}
func main() {
var strs = []string{"peach", "apple", "pear", "plum"}
fmt.Println(Index(strs, "pear"))
fmt.Println(Include(strs, "grape"))
fmt.Println(Any(strs, func(v string) bool {
return strings.HasPrefix(v, "p")
}))
fmt.Println(All(strs, func(v string) bool {
return strings.HasPrefix(v, "p")
}))
fmt.Println(Filter(strs, func(v string) bool {
return strings.Contains(v, "e")
}))
//上面的例子都是用的匿名函数,但是你也可以使用类型正确的命名函数
fmt.Println(Map(strs, strings.ToUpper))
}
执行结果如下图所示:

43. 字符串函数
标准库的 strings 包提供了很多有用的字符串相关的函数。这里是一些用来让你对这个包有个初步了解的例子。
package main
import (
"fmt"
s "strings"
)
//我们给 fmt.Println 一个短名字的别名,我们随后将会经常用到。
var p = fmt.Println
func main() {
//这是一些 strings 中的函数例子。注意他们都是包中的函数,不是字符串对象自身的方法,
// 这意味着我们需要考虑在调用时传递字符作为第一个参数进行传递。
p("Contains: ", s.Contains("test", "es"))
p("Count: ", s.Count("test", "t"))
p("HasPrefix: ", s.HasPrefix("test", "te"))
p("HasSuffix: ", s.HasSuffix("test", "st"))
p("Index: ", s.Index("test", "e"))
p("Join: ", s.Join([]string{"a", "b"}, "-"))
p("Repeat: ", s.Repeat("a", 5))
p("Replace: ", s.Replace("foo", "o", "0", -1))
p("Replace: ", s.Replace("foo", "o", "0", 1))
p("Split: ", s.Split("a-b-c-d-e", "-"))
p("ToLower: ", s.ToLower("TEST"))
p("ToUpper: ", s.ToUpper("test"))
p()
//你可以在 strings包文档中找到更多的函数
//虽然不是 strings 的一部分,但是仍然值得一提的是获取字符串长度和通过索引获取一个字符的机制。
p("Len: ", len("hello"))
p("Char:", "hello"[1])
}
执行结果如下图所示:

44. 字符串格式化
Go 在传统的printf 中对字符串格式化提供了优异的支持。这里是一些基本的字符串格式化的人物的例子。
package main
import (
"fmt"
"os"
)
type point struct {
x, y int
}
func main() {
//Go为常规Go值的格式化设计提供了多种打印方式。例如,这里打印了point结构体的一个实例。
p := point{1, 2}
fmt.Printf("%v\n", p)
//如果值是一个结构体,%+v 的格式化输出内容将包括 结构体的字段名。
fmt.Printf("%+v\n", p)
//%#v 形式则输出这个值的 Go 语法表示。例如,值的运行源代码片段。
fmt.Printf("%#v\n", p)
//需要打印值的类型,使用 %T。
fmt.Printf("%T\n", p)
//格式化布尔值是简单的。
fmt.Printf("%t\n", true)
//格式化整形数有多种方式,使用 %d进行标准的十进制格式化。
fmt.Printf("%d\n", 123)
//这个输出二进制表示形式。
fmt.Printf("%b\n", 14)
//这个输出给定整数的对应字符。
fmt.Printf("%c\n", 33)
//%x 提供十六进制编码。
fmt.Printf("%x\n", 456)
//对于浮点型同样有很多的格式化选项。使用 %f 进行最基本的十进制格式化。
fmt.Printf("%f\n", 78.9)
//%e 和 %E 将浮点型格式化为(稍微有一点不同的)科学技科学记数法表示形式。
fmt.Printf("%e\n", 123400000.0)
fmt.Printf("%E\n", 123400000.0)
//使用 %s 进行基本的字符串输出。
fmt.Printf("%s\n", "\"string\"")
//像 Go 源代码中那样带有双引号的输出,使用 %q。
fmt.Printf("%q\n", "\"string\"")
//和上面的整形数一样,%x 输出使用 base-16 编码的字符串,每个字节使用 2 个字符表示。
fmt.Printf("%x\n", "hex this")
//要输出一个指针的值,使用 %p。
fmt.Printf("%p\n", &p)
//当输出数字的时候,你将经常想要控制输出结果的宽度和精度,
// 可以使用在 % 后面使用数字来控制输出宽度。
// 默认结果使用右对齐并且通过空格来填充空白部分。
fmt.Printf("|%6d|%6d|\n", 12, 345)
//你也可以指定浮点型的输出宽度,同时也可以通过 宽度.精度 的语法来指定输出的精度。
fmt.Printf("|%6.2f|%6.2f|\n", 1.2, 3.45)
//要左对齐,使用 - 标志。
fmt.Printf("|%-6.2f|%-6.2f|\n", 1.2, 3.45)
//你也许也想控制字符串输出时的宽度,特别是要确保他们在类表格输出时的对齐。
// 这是基本的右对齐宽度表示。
fmt.Printf("|%6s|%6s|\n", "foo", "b")
//要左对齐,和数字一样,使用 - 标志。
fmt.Printf("|%-6s|%-6s|\n", "foo", "b")
//到目前为止,我们已经看过 Printf了,它通过 os.Stdout输出格式化的字符串。
// Sprintf 则格式化并返回一个字符串而不带任何输出。
s := fmt.Sprintf("a %s", "string")
fmt.Println(s)
//你可以使用 Fprintf 来格式化并输出到 io.Writers而不是 os.Stdout。
fmt.Fprintf(os.Stderr, "an %s\n", "error")
}
执行结果如下图所示:

45. 正则表达式
Go 提供内置的正则表达式。这里是 Go 中基本的正则相关功能的例子。
package main
import (
"regexp"
"fmt"
"bytes"
)
func main() {
//这个测试一个字符串是否符合一个表达式。
match, _ := regexp.MatchString("p([a-z]+)ch", "peach")
fmt.Println(match)
//上面我们是直接使用字符串,但是对于一些其他的正则任务,
// 你需要 Compile 一个优化的 Regexp 结构体。
r, _ := regexp.Compile("p([a-z]+)ch")
//这个结构体有很多方法。这里是类似我们前面看到的一个匹配测试。
fmt.Println(r.MatchString("peach"))
//这是查找匹配字符串的。
fmt.Println(r.FindString("peach punch"))
//这个也是查找第一次匹配的字符串的,但是返回的匹配开始和结束位置索引,而不是匹配的内容。
fmt.Println(r.FindStringIndex("peach punch"))
//Submatch 返回完全匹配和局部匹配的字符串。例如,这里会返回 p([a-z]+)ch 和 `([a-z]+) 的信息。
fmt.Println(r.FindStringSubmatch("peach punch"))
//类似的,这个会返回完全匹配和局部匹配的索引位置。
fmt.Println(r.FindStringSubmatchIndex("peach punch"))
//带 All 的这个函数返回所有的匹配项,而不仅仅是首次匹配项。例如查找匹配表达式的所有项。
fmt.Println(r.FindAllString("peach punch pinch", -1))
//All 同样可以对应到上面的所有函数。
fmt.Println(r.FindAllStringSubmatchIndex("peach punch pinch", -1))
//这个函数提供一个正整数来限制匹配次数。
fmt.Println(r.FindAllString("peach punch pinch", 2))
//上面的例子中,我们使用了字符串作为参数,并使用了如 MatchString 这样的方法。
// 我们也可以提供 []byte参数并将 String 从函数命中去掉。
fmt.Println(r.Match([]byte("peach")))
//创建正则表示式常量时,可以使用 Compile 的变体MustCompile 。
// 因为 Compile 返回两个值,不能用于常量。
r = regexp.MustCompile("p([a-z]+)ch")
fmt.Println(r)
//regexp 包也可以用来替换部分字符串为其他值。
fmt.Println(r.ReplaceAllString("a peach", "<fruit>"))
//Func 变量允许传递匹配内容到一个给定的函数中,
in := []byte("a peach")
out := r.ReplaceAllFunc(in, bytes.ToUpper)
fmt.Println(string(out))
}
执行结果如下图所示:

46 JSON
Go 提供内置的 JSON 编解码支持,包括内置或者自定义类型与 JSON 数据之间的转化。
package main
import (
"fmt"
"encoding/json"
"os"
)
//下面我们将使用这两个结构体来演示自定义类型的编码和解码。
type Response1 struct {
Page int
Fruits []string
}
type Response2 struct {
Page int `json:"page"`
Fruits []string `json:"fruits"`
}
func main() {
//首先我们来看一下基本数据类型到 JSON 字符串的编码过程。这里是一些原子值的例子。
bolB, _ := json.Marshal(true)
fmt.Println(string(bolB))
intB, _ := json.Marshal(1)
fmt.Println(string(intB))
fltB, _ := json.Marshal(2.34)
fmt.Println(string(fltB))
strB, _ := json.Marshal("gopher")
fmt.Println(string(strB))
//这里是一些切片和 map 编码成 JSON 数组和对象的例子。
slcD := []string{"apple", "peach", "pear"}
slcB, _ := json.Marshal(slcD)
fmt.Println(string(slcB))
mapD := map[string]int{"apple": 5, "lettuce": 7}
mapB, _ := json.Marshal(mapD)
fmt.Println(string(mapB))
//JSON 包可以自动的编码你的自定义类型。
// 编码仅输出可导出的字段,并且默认使用他们的名字作为 JSON 数据的键。
res1D := &Response1{
Page: 1,
Fruits: []string{"apple", "peach", "pear"}}
res1B, _ := json.Marshal(res1D)
fmt.Println(string(res1B))
//你可以给结构字段声明标签来自定义编码的 JSON 数据键名称。
// 在上面 Response2 的定义可以作为这个标签这个的一个例子。
res2D := Response2{
Page: 1,
Fruits: []string{"apple", "peach", "pear"}}
res2B, _ := json.Marshal(res2D)
fmt.Println(string(res2B))
//现在来看看解码 JSON 数据为 Go 值的过程。这里是一个普通数据结构的解码例子。
byt := []byte(`{"num":6.13,"strs":["a","b"]}`)
//我们需要提供一个 JSON 包可以存放解码数据的变量。
// 这里的 map[string]interface{} 将保存一个 string 为键,值为任意值的map。
var dat map[string]interface{}
//这里就是实际的解码和相关的错误检查。
if err := json.Unmarshal(byt, &dat); err != nil {
panic(err)
}
fmt.Println(dat)
//为了使用解码 map 中的值,我们需要将他们进行适当的类型转换。
// 例如这里我们将 num 的值转换成 float64类型。
num := dat["num"].(float64)
fmt.Println(num)
//访问嵌套的值需要一系列的转化。
strs := dat["strs"].([]interface{})
str1 := strs[0].(string)
fmt.Println(str1)
//我们也可以解码 JSON 值到自定义类型。
//这个功能的好处就是可以为我们的程序带来额外的类型安全加强,并且消除在访问数据时的类型断言。
str := `{"page": 1, "fruits": ["apple", "peach"]}`
res := &Response2{}
json.Unmarshal([]byte(str), &res)
fmt.Println(res)
fmt.Println(res.Fruits[0])
//在上面的例子中,我们经常使用 byte 和 string 作为使用标准输出时数据和 JSON 表示之间的中间值。
//我们也可以和os.Stdout 一样,直接将 JSON 编码直接输出至 os.Writer流中,或者作为 HTTP 响应体。
enc := json.NewEncoder(os.Stdout)
d := map[string]int{"apple": 5, "lettuce": 7}
enc.Encode(d)
}
执行结果如下图所示:

47. 时间
Go 对时间和时间段提供了大量的支持;这里是一些例子。
package main
import (
"fmt"
"time"
)
func main() {
p := fmt.Println
//得到当前时间。
now := time.Now()
p(now)
//通过提供年月日等信息,你可以构建一个 time。时间总是关联着位置信息,例如时区。
then := time.Date(
2009, 11, 17, 20, 34, 58, 651387237, time.UTC)
p(then)
//你可以提取出时间的各个组成部分。
p(then.Year())
p(then.Month())
p(then.Day())
p(then.Hour())
p(then.Minute())
p(then.Second())
p(then.Nanosecond())
p(then.Location())
//输出是星期一到日的 Weekday 也是支持的。
p(then.Weekday())
//这些方法来比较两个时间,分别测试一下是否是之前,之后或者是同一时刻,精确到秒。
p(then.Before(now))
p(then.After(now))
p(then.Equal(now))
//方法 Sub 返回一个 Duration 来表示两个时间点的间隔时间。
diff := now.Sub(then)
p(diff)
//我们计算出不同单位下的时间长度值。
p(diff.Hours())
p(diff.Minutes())
p(diff.Seconds())
p(diff.Nanoseconds())
//你可以使用 Add 将时间后移一个时间间隔,或者使用一个 - 来将时间前移一个时间间隔。
p(then.Add(diff))
p(then.Add(-diff))
}
执行结果如下图所示:

48. 时间戳
一般程序会有获取 Unix 时间的秒数,毫秒数,或者微秒数的需要。来看看如何用 Go 来实现。
package main
import (
"fmt"
"time"
)
func main() {
//分别使用带 Unix 或者 UnixNano 的 time.Now来获取从自协调世界时起到现在的秒数或者纳秒数。
now := time.Now()
secs := now.Unix()
nanos := now.UnixNano()
fmt.Println(now)
//注意 UnixMillis 是不存在的,所以要得到毫秒数的话,你要自己手动的从纳秒转化一下。
millis := nanos / 1000000
fmt.Println(secs)
fmt.Println(millis)
fmt.Println(nanos)
//你也可以将协调世界时起的整数秒或者纳秒转化到相应的时间。
fmt.Println(time.Unix(secs, 0))
fmt.Println(time.Unix(0, nanos))
}
执行结果如下图所示:

49. 时间的格式化和解析
Go 支持通过基于描述模板的时间格式化和解析。
package main
import (
"fmt"
"time"
)
func main() {
p := fmt.Println
//这里是一个基本的按照 RFC3339 进行格式化的例子,使用对应模式常量。
t := time.Now()
p(t.Format(time.RFC3339))
//时间解析使用同 Format 相同的形式值。
t1, e := time.Parse(
time.RFC3339,
"2012-11-01T22:08:41+00:00")
p(t1)
//Format 和 Parse 使用基于例子的形式来决定日期格式,
// 一般你只要使用 time 包中提供的模式常量就行了,但是你也可以实现自定义模式。
// 模式必须使用时间 Mon Jan 2 15:04:05 MST 2006来指定给定时间/字符串的格式化/解析方式。
// 时间一定要按照如下所示:2006为年,15 为小时,Monday 代表星期几,等等。
p(t.Format("3:04PM"))
p(t.Format("Mon Jan _2 15:04:05 2006"))
p(t.Format("2006-01-02T15:04:05.999999-07:00"))
form := "3 04 PM"
t2, e := time.Parse(form, "8 41 PM")
p(t2)
//对于纯数字表示的时间,你也可以使用标准的格式化字符串来提出出时间值得组成。
fmt.Printf("%d-%02d-%02dT%02d:%02d:%02d-00:00\n",
t.Year(), t.Month(), t.Day(),
t.Hour(), t.Minute(), t.Second())
//Parse 函数在输入的时间格式不正确是会返回一个错误。
ansic := "Mon Jan _2 15:04:05 2006"
_, e = time.Parse(ansic, "8:41PM")
p(e)
}
执行结果如下图所示:

50. 随机数
Go 的 math/rand 包提供了伪随机数生成器(英)。
package main
import (
"fmt"
"time"
"math/rand"
)
func main() {
//例如,rand.Intn 返回一个随机的整数 n,0 <= n <= 100。
fmt.Print(rand.Intn(100), ",")
fmt.Print(rand.Intn(100))
fmt.Println()
//rand.Float64 返回一个64位浮点数 f,0.0 <= f <= 1.0。
fmt.Println(rand.Float64())
//这个技巧可以用来生成其他范围的随机浮点数,例如5.0 <= f <= 10.0
fmt.Print((rand.Float64()*5)+5, ",")
fmt.Print((rand.Float64() * 5) + 5)
fmt.Println()
//默认情况下,给定的种子是确定的,每次都会产生相同的随机数数字序列。
// 要产生变化的序列,需要给定一个变化的种子。需要注意的是,
// 如果你出于加密目的,需要使用随机数的话,请使用 crypto/rand 包,此方法不够安全。
s1 := rand.NewSource(time.Now().UnixNano())
r1 := rand.New(s1)
//调用上面返回的 rand.Source 的函数和调用 rand 包中函数是相同的。
fmt.Print(r1.Intn(100), ",")
fmt.Print(r1.Intn(100))
fmt.Println()
//如果使用相同的种子生成的随机数生成器,将会产生相同的随机数序列。
s2 := rand.NewSource(42)
r2 := rand.New(s2)
fmt.Print(r2.Intn(100), ",")
fmt.Print(r2.Intn(100))
fmt.Println()
s3 := rand.NewSource(42)
r3 := rand.New(s3)
fmt.Print(r3.Intn(100), ",")
fmt.Print(r3.Intn(100))
}
执行结果如下图所示:

上一篇:学习Go语言必备案例 (4)
下一篇:学习Go语言必备案例 (6)