今天看了贺思远老师写的《数据蜂巢架构演进之路》有些感触。首先写到功能整合,各个功能如何实现离线同步:可理解为将根据一个sql查询出的数据同步到其它目标存储上;实时订阅:通过实时解析mysql-binlog,将数据的变动封装成事件存于消息队列,供用户订阅消费;实时同步:提供一些常见的订阅客户端料现,实时消费消息,将数据的变动应用于目标存储上。讲述了将三个功能架构在一个平台下的方法:将离线同步,实时订阅,实时同步三个需求抽象为三种作业,分别为BatchJob,StreamJob,PieJob。i. BatchJob参考Sqoop的模式,将需同步的数据先根据指定的规则进行分片,然后将作业根据分片拆分成多个任务,每个任务只同步本分片的数据,多个任务可同时运行,以加快同步效率;ii. 以BatchJob的模式为基础,StreamJob也可根据需要采集的mysql实例分成多个任务,每个任务负责采集解析一个mysql的binlog,并将解析后的事件封装成消息存于本地供订阅者消费iii. PieJob是对订阅客户端的封装,每一个订阅客户端即可看作一个任务。三种不同的作业最终都可以通过分片分成多个任务去运行,使用统一的模型。
集群:
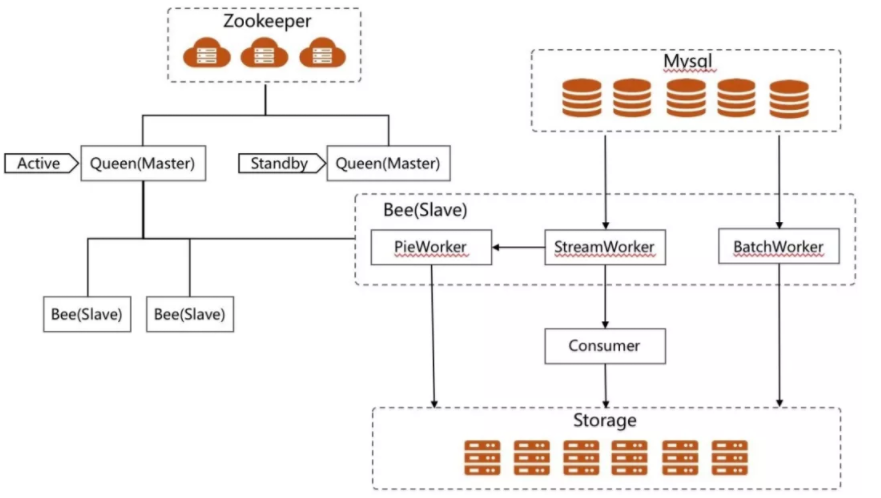
Binlog采集解析后的消息存于本地hhl文件中,一但主机发生HA切换后,之前的消息会全部丢失。方案一:复本,缺点:占用大量磁盘资源,实现逻辑复杂,放弃使用;方案二:数据补全,因本身mysql为满足运维需要,binlog会存储N天,丢失消息完全可以重新抽取解析binlog获得,此时不再需要对消息做复本,丢失的消息如果被请求可以重新生成Binlog中并不记录字段名等相关信息,导致生成的消息只有数据,没有结构。方案一:通过查询数据库获得,缺点:在解析存在延迟情况下,表结构可能不正确,弃用;
方案二:快照,StreamJob在初次启动时会对mysql中所有的表做一份快照,此后在运行期间当解析到DDL操作时会将原快照取出生成一个新的复本,并在该复本上应用对应的DDL操作,最后生成一个新快照。保证任何时刻的binlog都可以找到其对应的元数据。同时每个StreamTask会提供一个元数据服务,消息在传输时不存储字段等信息,客户端需要时直接请求元数据服务即可,以减少带宽占用。第一版采用的是分布式线程池的模式,同一个Bee上跑的多个任务在一个进程内以多线程的形式存在。但因系统为满足各种需求,提供了自己定义业务逻辑,上传jar包的方式提交作业,部分用户作业结束后忘记释放相关资源,以及一些作业占用资源过多影响其它任务的执行。随后弃用线程池,使用进程池。用子进程保障不同的作业之间有一个资源隔离。架构图如下:
原架构高度依赖Queen,当Bee与Queen断开连接后任务会立刻停止(防止Queen重新调度,进行多次执行)。但在库房环境下,当库房内部网络正常但与Queen网络不通时,因为库房的Bee全为同一分组,同时库房的任务只能分到对应库房内,此时同步任务将无法运行。为适应该场景,使用了子集群方案,具有特定分组信息的Bee启动时会和同一分组的机器先自发组建子集群,并推选Master,随后由子集群的Master与Queen进行交互。此时,对于需要发送给子集群的作业,Queen下放调度权限给子集群,由子集群的master负责调度。而Queen只负责作业状态的监控及生命周期的全局控制。同时该版本去除了对Zookeeper的依赖。