首先在神经网络中,每一层网络结构都会有一个激活函数,以我们比较常见的sigmoid函数为例,我们可以看看sigmoid激活函数的图像如图所示:
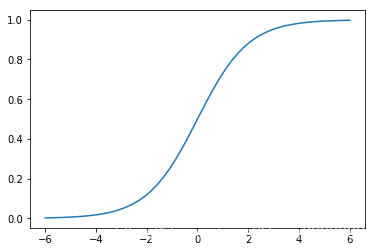
我们试想一下,如果这个时候某个神经元的输入为4,那么经过sigmoid函数之后,这个神经元的输出是
,如果神经元的输入为20,经过sigmoid函数之后,神经元的输出是
。可以看出这个时候神经元的输出已经对输入不敏感了,输入从4增加到20,然而输出只增加了0.01,几乎没有变化。我们可以通过sigmoid函数的导数函数更加直观的看出神经元对输入的敏感程度,如下是sigmoid函数的导数函数图像:
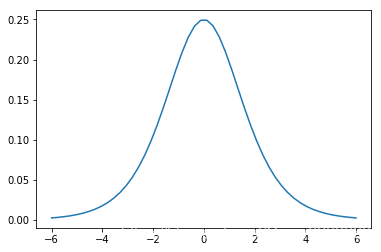
可以看出sigmoid函数在两端的梯度几乎为0了,对数据敏感的区域集中在
,所以我们就希望神经元的输入集中在激活函数的敏感区域,所以我们就需要在全连接层和激活函数之间加上一个batch normalization,来调整输入数据的分布。也就是说,对于每个隐层的神经元来说,BN就是把逐渐向非线性函数映射后向饱和区靠拢的输入分布变化到均值为0方差为1的正态分布上来,使输入的分布落在神经元对数据比较敏感的区域,以此来避免梯度消失的问题。有了BN,那么神经网络的梯度一直都能保持比较大的状态,那么神经网络也能保持比较好的收敛速度。我们来看看batch normalization的过程是怎么样子的:
输入:
输入的分布数据:
,需要学习的参数:
这里的
表示数据分布的缩放系数,
表示数据分布的偏移量
输出:
BN之后的数据分布:
过程:
1.计算输入数据的均值(mini-batch mean):
2.计算输入数据的方差(mini-batch variance):
3.标准化(normalization):
这里首先是将我们的数据分布减去均值再除以方差来进行标准化。
4.缩放和平移(scale and shift):
经过了前三步的操作之后某个神经元的激活输入分布
成了均值为0方差为1的正太分布,目的是将数据输入分布落在激活函数敏感区域,加快神经网络训练收敛的速度。但是这么做会导致网络的表达能力下降,所以我们需要进行第四步操作缩放和平移来学习
和
这两个参数,用来对变换后的激活进行反变换,来提高网络的表达能力,也就是变换的反操作:
所以以上就是BN的流程,有了BN,神经网络就有如下一些优点:
- 可以很大提升神经网络收敛的速度。
- 可以增加分类的效果,防止过拟合。
- 调参相对简单,初始化要求低,可以适当增加学习率。
上面就是我们BN的一些总结,所以现在在神经网络中经常加入BN,希望这边博文也可以加深大家对BN的理解,谢谢。