版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/weixin_38750084/article/details/91346212
Union:对两个结果集进行并集操作,不包括重复行,同时进行默认规则的排序;
Union All:对两个结果集进行并集操作,包括重复行,不进行排序;
下面我在hive中创建两张表测试一下:
先本地创建数据文件:
/usr/local/hive/hiveTestFile/student.txt
1 zhangsan
2 lisi
3 wangwu/usr/local/hive/hiveTestFile/student2.txt
1 zhangsan2
2 lisi2
3 wangwu2本地数据导入hive:
student表:
load data local inpath '/usr/local/hive/hiveTestFile/student2.txt' into table db_hive_edu.student;

student2表:
load data local inpath '/usr/local/hive/hiveTestFile/student2.txt' into table db_hive_edu.student2;
测试1:使用union all
hive> select * from student union all select * from student2;
Total jobs = 1
Launching Job 1 out of 1
Number of reduce tasks is set to 0 since there's no reduce operator
Starting Job = job_1559981808383_0008, Tracking URL = http://sparkproject1:8088/proxy/application_1559981808383_0008/
Kill Command = /usr/local/hadoop/bin/hadoop job -kill job_1559981808383_0008
Hadoop job information for Stage-1: number of mappers: 2; number of reducers: 0
2019-06-08 17:45:18,077 Stage-1 map = 0%, reduce = 0%
2019-06-08 17:45:25,670 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 2.4 sec
MapReduce Total cumulative CPU time: 2 seconds 400 msec
Ended Job = job_1559981808383_0008
MapReduce Jobs Launched:
Stage-Stage-1: Map: 2 Cumulative CPU: 2.4 sec HDFS Read: 537 HDFS Write: 67 SUCCESS
Total MapReduce CPU Time Spent: 2 seconds 400 msec
OK
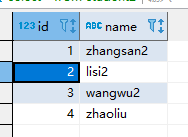
1 zhangsan2
2 lisi2
3 wangwu2
4 zhaoliu
1 zhangsan
2 lisi
3 wangwu
Time taken: 18.885 seconds, Fetched: 7 row(s)
hive> 测试2:使用union
hive>
> select * from student union select * from student2;
FAILED: ParseException line 1:28 missing ALL at 'select' near '<EOF>'
hive> 报错 了,hive 0.13版本可能还未支持 union
参考: