我们从 TestChangeMethod t = (TestChangeMethod) ct.getBean("A"); 开始分析。
首先我们要知道 getBean方法是哪个类中的。下面给出其类图。
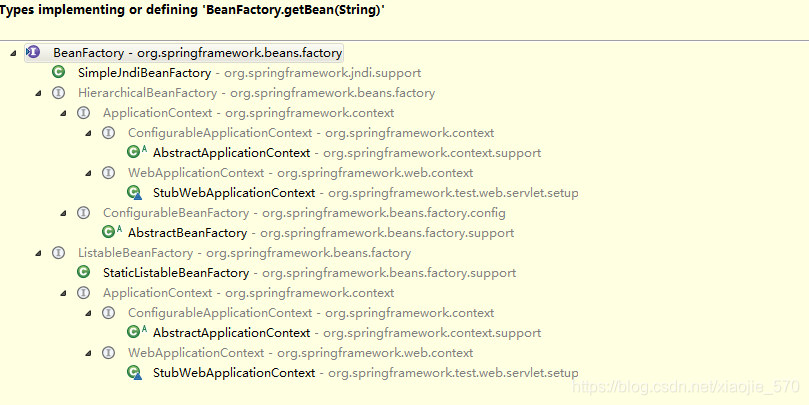
这里我们看 AbstractBeanFactory 中是如何实现该方法的,该类是org.springframework.beans.factory.support;包中的类。
一、bean的加载

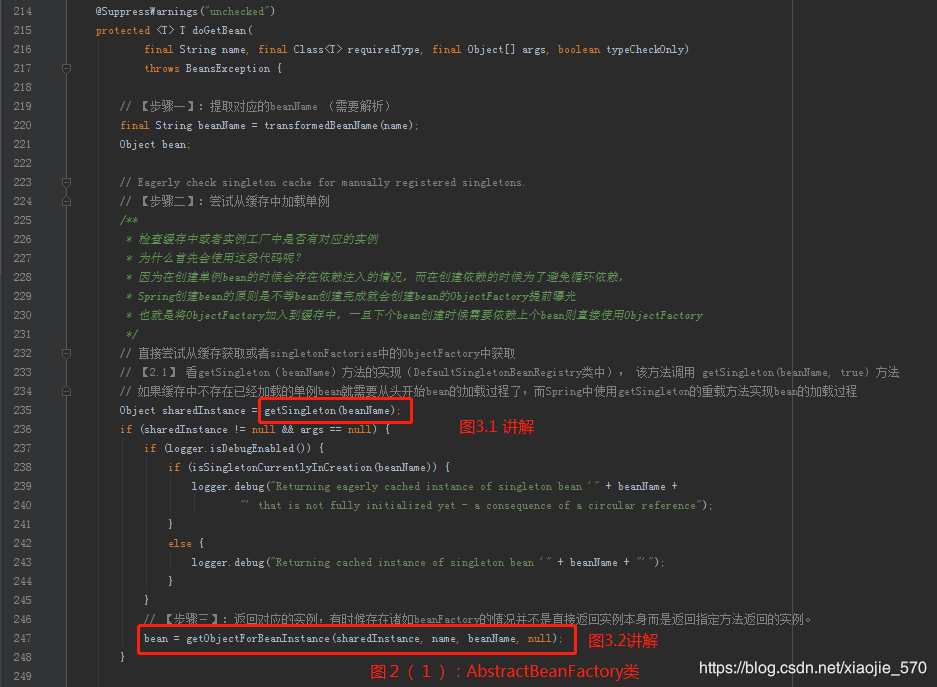
对于加载过程中所涉及的步骤大致如下:
-
【步骤一】转化对应的
beanName- 获取很多人不理解转换对应的
beanName是什么意思,传入的参数name不就是beanName吗? 其实不是,这里传入的参数可能是别名,也可能是FactoryBean,所以需要进行一系列的解析,这些解析内容包括如下内容。 - 去除
FactoryBean的修饰符,也就是如果name = "&aa",那么会首先去除 & 而使name = "aa"。 - 取指定
alias所表示的最终beanName,例如别名A指向名称为B的bean则返回B;若别名A指向别名B,别名B又指向名称为C的bean则返回C。
- 获取很多人不理解转换对应的
-
【步骤二】尝试从缓存中加载单例
- 单例在
Spring的同一个容器内只会被创建一次,后续再获取bean,就直接从单例缓存中获取了。当然这里也只是尝试加载,首先尝试从缓存中加载, 如果加载不成功则再次尝试从singletonFactories中加载。因为在创建单例bean的时候会存在依赖注入的情况,而在创建依赖的时候为了避免循环依赖,在Spring中创建bean的原则是不等bean创建完成就会将创建bean的ObjectFactory提早曝光加入到缓存中,一旦下一个bean创建时候需要依赖上一个bean则直接使用ObjectFactory。
- 单例在
-
【步骤三】
Bean的实例化- 如果从缓存中得到了
bean的原始状态,则需要对bean进行实例化。这里有必要强调一下,缓存中记录的只是最原始的bean状态,并不一定是我们最终想要的bean。举个栗子,假如我们需要对工厂bean进行处理,那么这里得到的其实是工厂bean的初始状态,但是我们真正需要的是工厂bean中定义的factory-method方法中返回的bean,而getObjectForBeanInstance就是完成这个工作的。
- 如果从缓存中得到了
-
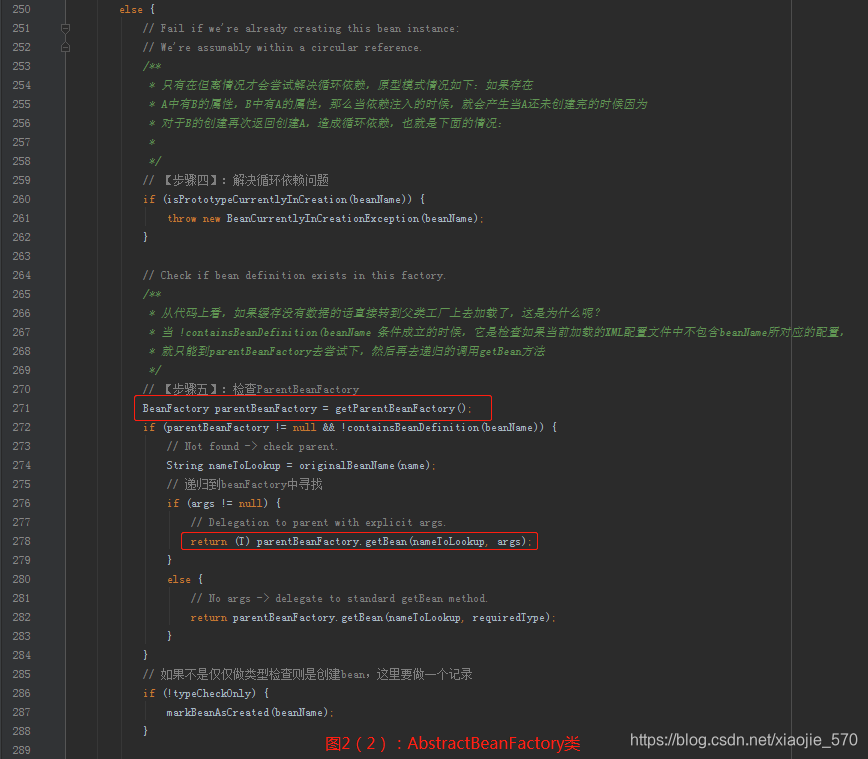
【步骤四】原型模式的依赖检查
- 只有在单例情况下才会尝试解决循环依赖。如果存在A中有B的属性,B中有A的属性,那么当依赖注入的时候,就会产生当A还未创建完的时候因为对B的创建再次返回创建A,造成循环依赖。
-
【步骤五】检查
parentBeanFactory- 如果缓存中没有数据的话直接转到父类工厂上去加载。
-
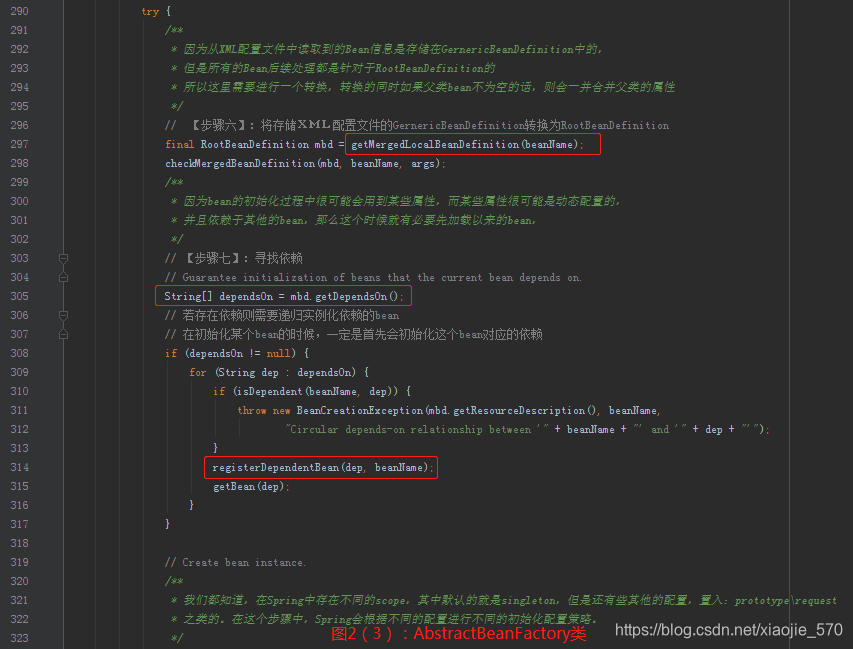
【步骤六】将存储
XML配置文件的GernericBeanDefinition转换为RootBeanDefinition- 因为从
XML配置文件中读取到的Bean信息是存储在GernericBeanDefinition中的,但是所有的bean后续处理都是针对于RootBeanDefinition的,所以这里需要进行一个转换,转换的同时如果父类bean不为空的话,则会一并合并父类的属性。
- 因为从
-
【步骤七】寻找依赖
- 因为
bean的初始化过程中很可能会用到某些属性,而某些属性很可能是动态配置的,并且配置成依赖于其他的bean,那么这个时候就有必要先加载依赖的bean,所以,在Spring的加载顺序中,在初始化某一个bean的时候首先会初始化这个bean所对应的依赖。
- 因为
-
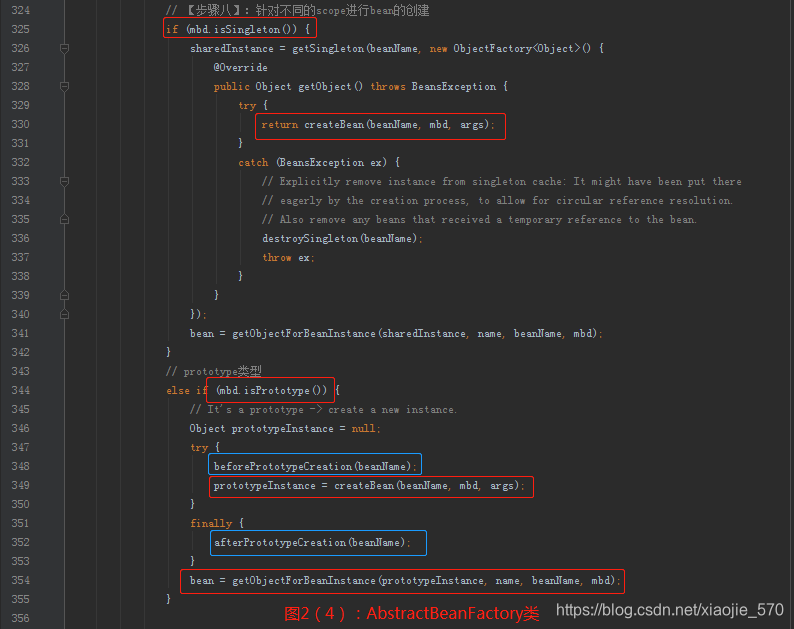
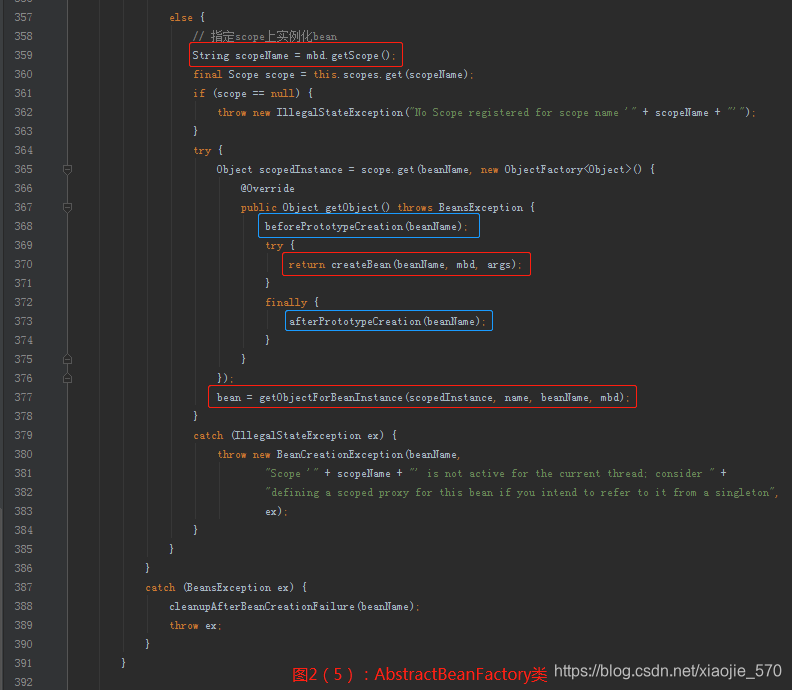
【步骤八】针对不同的
scope进行bean的创建- 我们都知道,在
Spring中存在着不同的scope,其中默认的是singleton,但是还有些其他的配置注入prototype、request之类的。在这个步骤中,Spring会根据不同的配置进行不同的初始化策略。
- 我们都知道,在
-
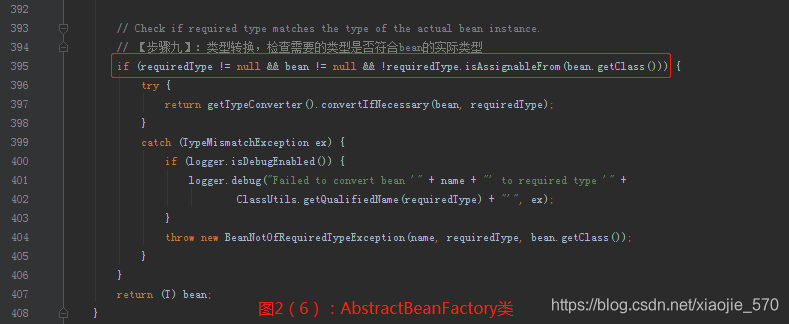
【步骤九】类型转换
二、FactoryBean 与 BeanFactory
1. FactoryBean 接口
一般情况下,Spring通过反射机制利用 bean 的 class 属性指定实现类来实例化 bean。在某些情况下,实力化 bean 过程比较复杂,如果按照传统的方式,则需要在<bean>中提供大量的配置信息,配置方式的灵活性是受限的,这时采用编码的方式可能会得到一个简单的方案。
FactoryBean 接口对于 Spring 框架来说占有重要的地位,Spring自身就提供了 70 多个 FactoryBean 的实现。它们隐藏了实例化一些复杂bean的细节,给上层应用带来了便利。
FactoryBean 接口的实现类

2. BeanFactory
BeanFactory 是 IOC最基本的容器,负责生产与管理 bean,它为其他具体的IOC容器提供了最基本的规范,如:DefaultListableBeanFactory、XMLBeanFactory、ApplicationContext等都实现了 BeanFactory,再在其基础上附加了其他的功能。
三、缓存中获取单例 bean
单例在 Spring 的同一个容器内只会被创建一次,后续再获取 bean 直接从单例缓存中获取,当然这里也只是尝试加载,首先尝试从缓存中加载,然后再次尝试从 singletonFactories 中加载。因为在创建单例 bean 的时候会存在依赖注入的情况,而在创建依赖的时候为了避免循环依赖, Spring 创建 bean 的原则是不等 bean 创建完成就会将创建 bean 的 ObjectFactory 提早曝光加入到缓存中,一旦下一个 bean 创建时需要依赖上一个 bean,则直接使用 ObjectFactory。
- 【步骤一】先尝试从缓存加载
- 【步骤二】再尝试从
singletonFactories加载 - 【步骤三】将创建的 bean 提早曝光到
ObjectFactory中
singletonObjects: 用于保存BeanName和创建bean实例之间的关系singletonFactories:用于保存BeanName和创建bean的工厂之间的关系earlySingletonObjects:也会保存BeanName和创建bean实例之间的关系,与SingletonObjects不同之处在于,当一个单例bean被放到这里面后,那么当bean还在创建过程中,就可以通过getBean方法获取到了,其目的是用来检测循环引用。
四、 从 bean 的实例中获取对象
我们得到 bean 的实例后要做的第一步就是调用这个方法来检测一下正确性,其实就是用于检测当前 bean 是否是 FactoryBean 类型的 bean,如果是,那么需要调用该 bean 对应的 FactoryBean 实例中的 getObject 作为返回值。
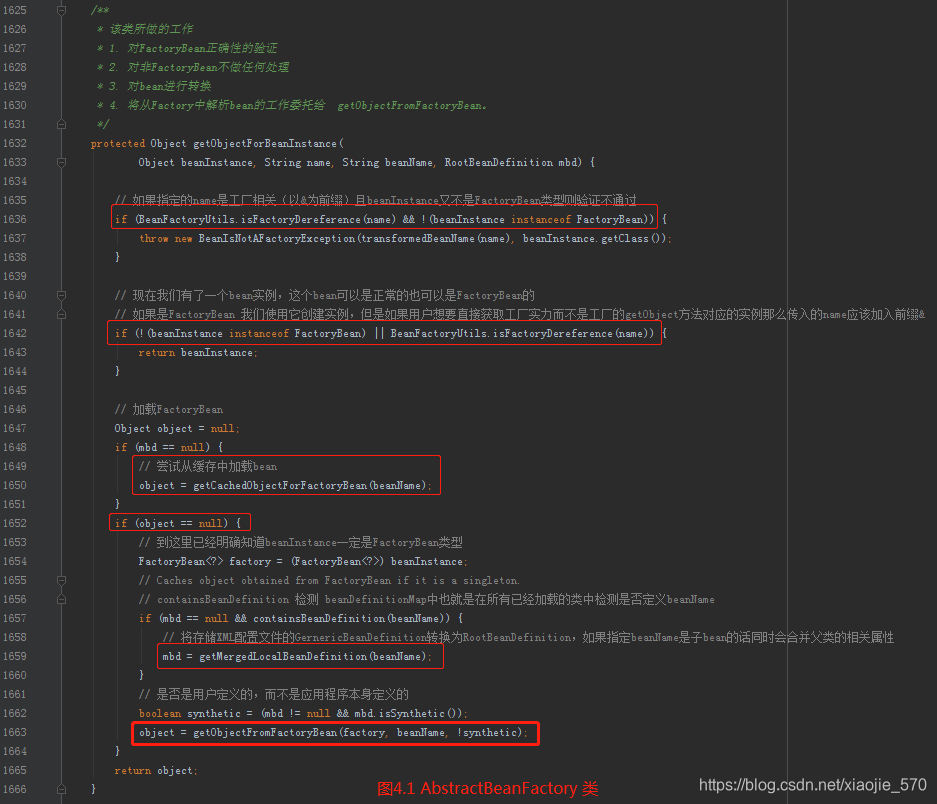
我们来分析一下 getObjectForBeanInstance 中所做的工作。
- 【步骤一】对
FactoryBean正确性的验证 - 【步骤二】对非
FactoryBean不做任何处理 - 【步骤三】从缓存中加载
bean,如果缓存中加载bean不成功则 从配置文件中获取(要将配置文件中的GernericBeanDefinition转换为RootBeanDefinition) - 将从
Factory中解析bean的工作委托给getObjectFromFactoryBean
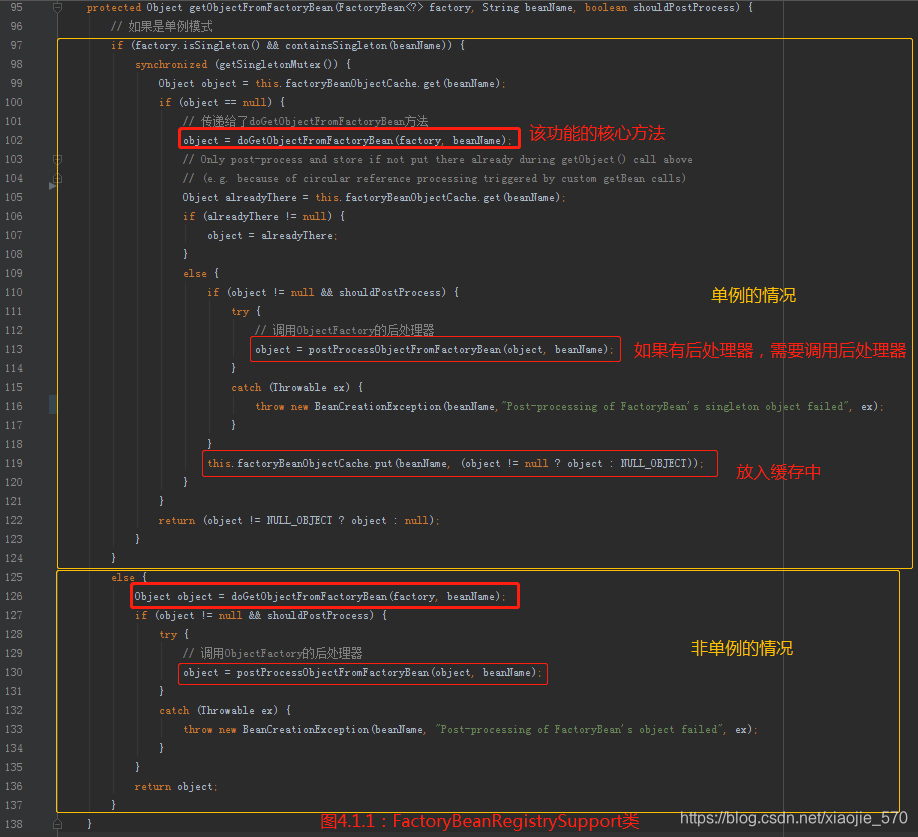
这里面主要分为两大块进行处理:是单例的还是非单例的。返回的 bean 如果是单例的,就必须保证全局唯一,同时,也因为是单例的,所以不必重复创建,可以使用缓存在提高性能,也就是说已经加载过就要记录下来以便下次复用(图中【第119行】),否则就直接获取了(【第136行】)。
接着我们看一下上图中【第102行】代码的具体实现。
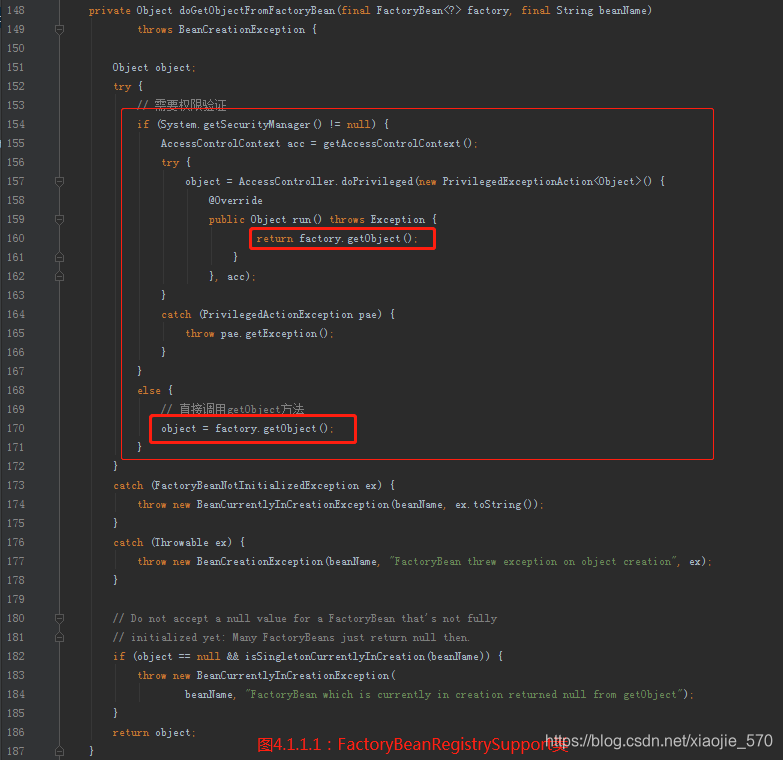
我们之前说过,如果 bean 声明为 FactoryBean 类型,则当提取 bean 时提取的并不是 FactoryBean,而是 FactoryBean 中对应的 getObject 方法返回的 bean,而【图4.1.1.1】实现的就是这个功能。
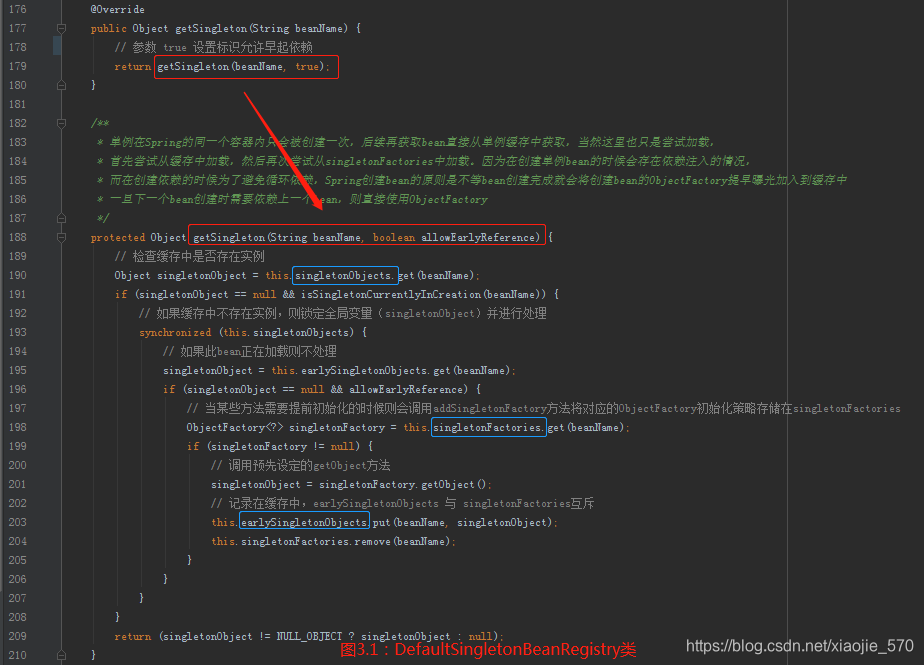
五、获取单例
之前我们已经讲解了从缓存中获取单例的过程,那么如果缓存中不存在已经加载的单例就需要从头开始 bean 的加载过程了,而Spring中使用 getSingleton 的重载方法实现了 bean 的加载过程。
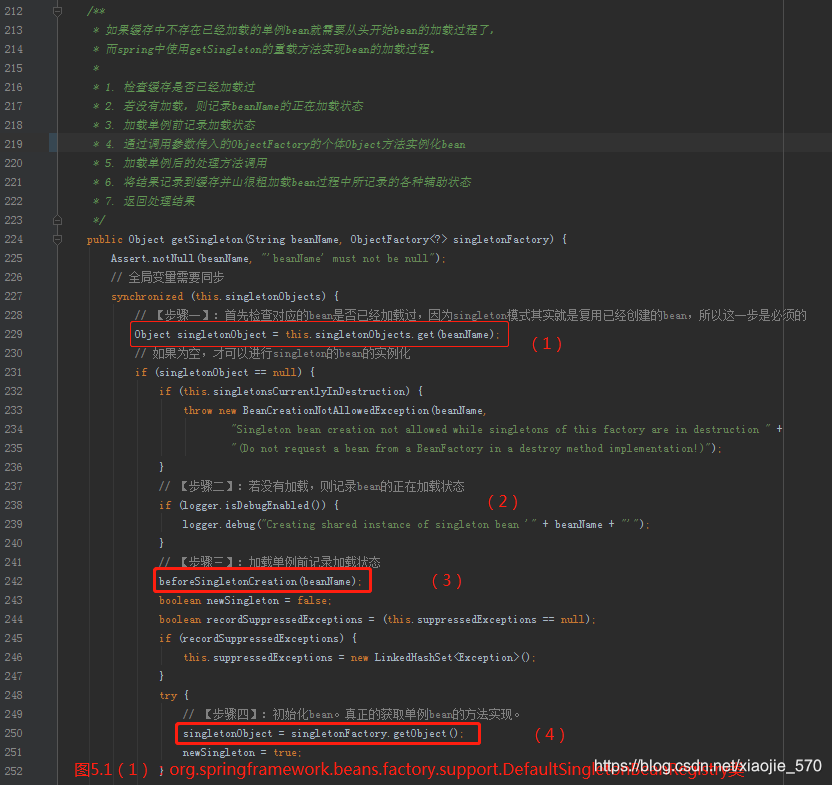
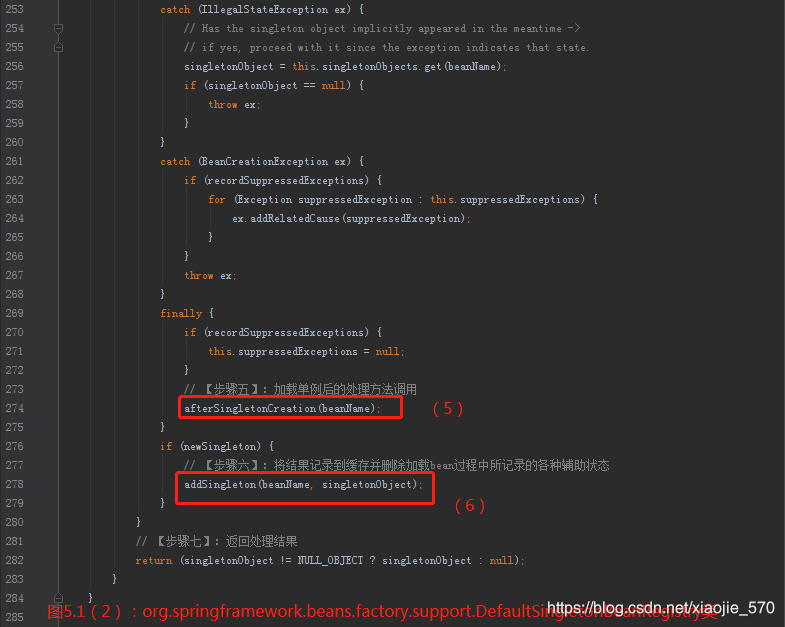
上述代码中其实是使用了回调方法,使得程序可以在单例创建的前后做一些准备及处理操作,而真正的获取单例 bean 的方法其实并不是在此方法中实现的,其实现逻辑是在 ObjectFactory 类型的 singletonFactory 中实现的。而这些准备及处理操作包括如下内容:
- 检查缓存是否已经加载过
- 若没有加载,则记录 beanName 的正在加载状态
- 加载单例前记录加载状态
- 通过调用参数传入的 ObjectFactory 的个体 Object 方法实例化 bean
- 加载单例后的处理方法调用
- 将结果记录至缓存并删除加载 bean 处理中所记录的各种辅助状态
- 返回处理结果
六、准备创建 bean
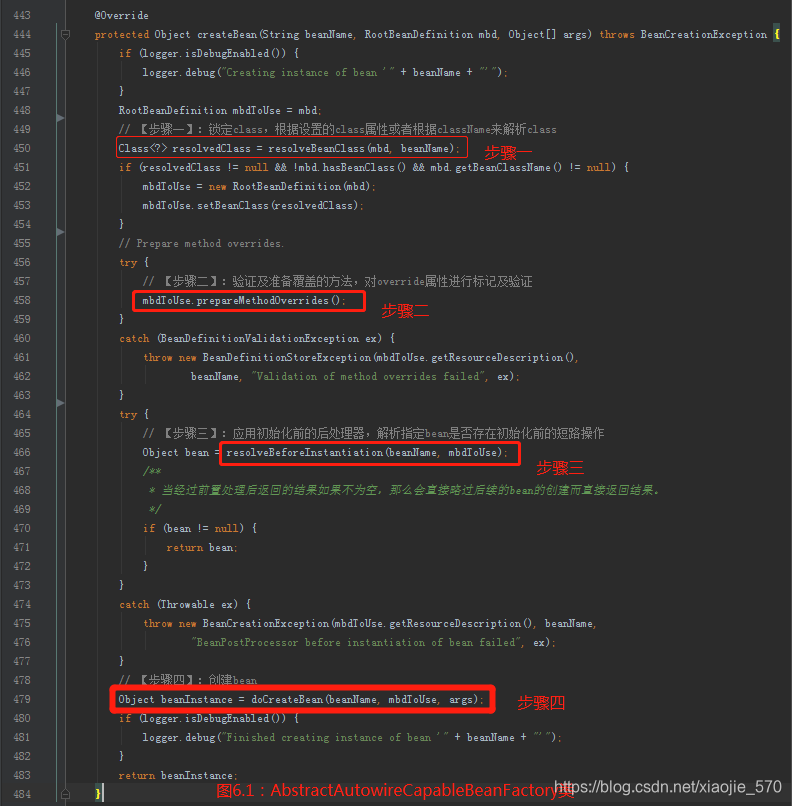
从代码中我们可以总结出函数完成的具体步骤与功能
- 【步骤一】根据设置的
class属性或者根据beanName来解析Class - 【步骤二】对
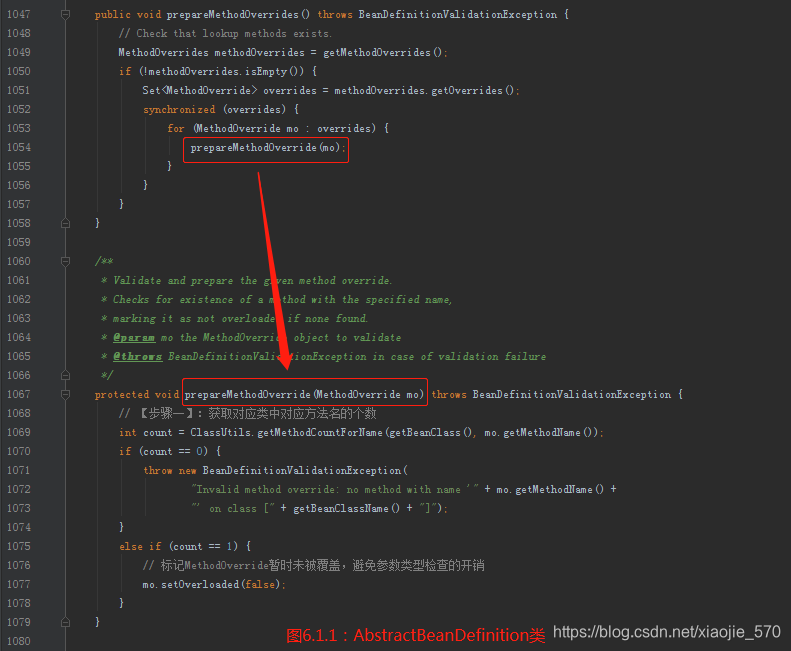
override属性进行标记及验证- 其实在
Spring中确实没有override-method这样的配置,但是在Spring配置中是存在lookup-method和replace-method的,而这两个配置的加载其实就是将配置统一存在在BeanDefinition中的methodOverrides属性里,而这个函数的操作其实就是针对于这两个配置的。
- 其实在
- 【步骤三】应用初始化前的后处理器,解析指定
bean是否存在初始化前的短路操作。 - 【步骤四】创建
bean
6.1 处理 override属性
6.2 实例化的前置处理
我们回到【图6.1】中,继续看bean创建前的准备工作。
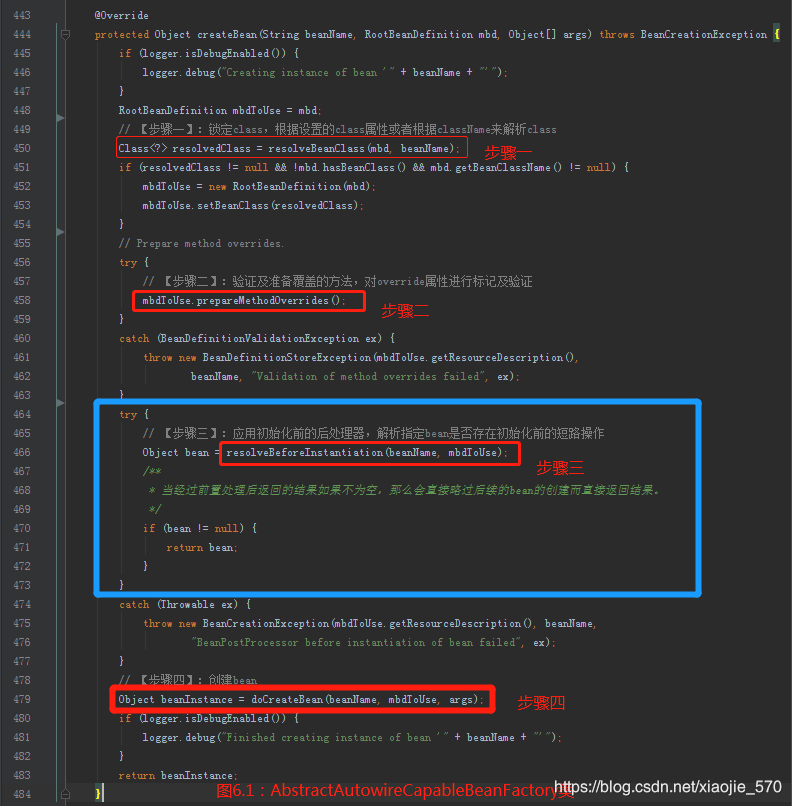
图中蓝色框标注的地方非常重要,我们看到步骤三中是堆bean进行初始化前的后处理操作,主要注意看【第470行】,当经过前置处理后返回的额结果如果不为空,那么会直接略过后续的 Bean的创建而直接返回结果。 这个特性非常重要,我们熟知的 AOP功能就是基于这里判断的。
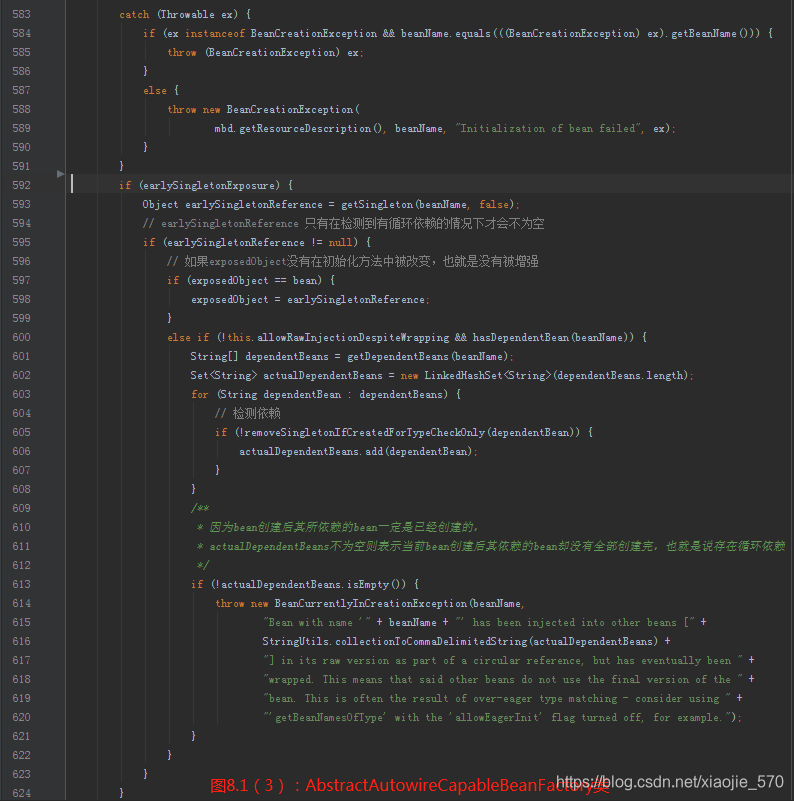
七、循环依赖
Spring 容器循环依赖包括 构造器循环依赖 和 setter循环依赖。
7.1 构造器循环依赖
表示通过构造器注入构成的循环依赖,此依赖是无法解决的,只能抛出 BeanCurrentlyInCreationException 异常表示循环依赖。
Spring 容器将每一个正在创建的 bean 标识符放在一个“当前创建 bean池”中, bean 标识符在创建过程中将一直保持在这个池中,因此如果在创建 bean 过程中发现自己已经在“当前创建 bean 池”里时,将抛出 BeanCurrentlyInCreationException 异常表示循环依赖;而对于创建完毕的 bean 将从“当前创建 bean 池”中清除掉。
7.2 setter 循环依赖
表示通过 setter 注入方式构成的循环依赖。对于 setter 注入造成的依赖是通过 Spring 容器提前暴露刚完成构造器注入但未完成其他步骤(如setter注入)的bean 来完成的,而且只能解决单例作用域的 bean 循环依赖。通过提前暴露一个单例工厂方法,从而使其他 bean 能引用到该 bean
7.3 prototype范围的依赖处理
对于 “prototype” 作用域 bean, Spring容器无法完成依赖注入,因为 Spring 容器不进行缓存“prototype”作用域的 bean,因此无法提前暴露一个创建中的 bean。
八、创建 bean
我们继续六中的处理过程。

现在已经走到了【步骤三】,走过步骤三之后,程序有两个选择,如果创建了代理或者在步骤三中改变了bean,则直接返回就可以了。否则,需要进行常规bean 的创建,这个常规 bean 的创建就是在 doCreateBean 中完成。
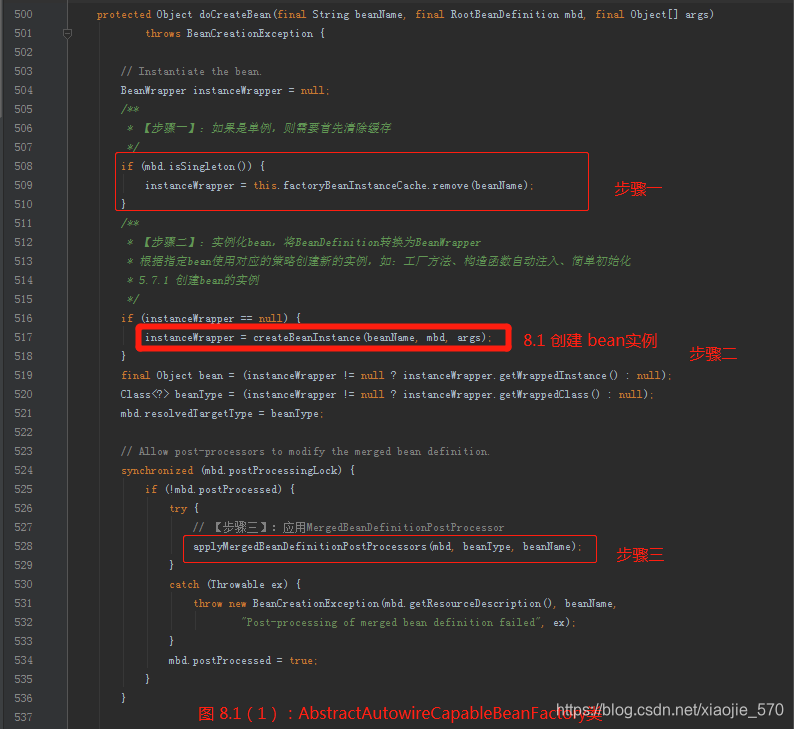
我们来看看整个函数的概要思路:
-
【步骤一】如果是单例,则需要首先清除缓存
-
【步骤二】实例化
bean,将BeanDefinition转换为BeanWrapper- 首先要来解释一下,为什么称
BeanDefinition为spring中的class。java开发者都很清除,对象通过 class 来进行实例化,因为class对象承载着对象所具有的属性、方法以及父子继承的关系等信息。在Spring 容器中管理着Bean组件,也是经过一个实例化的过程,而这个实例化过程,仅仅是依靠class 对象所拥有的信息是远远不够的,要知道,Bean组件要解决的还有作用域、实例化条件、组件依赖等一系列问题,Spring 将这样的一个对象封装在BeanDefinition对象中。 - 如果存在工厂方法则使用工厂方法进行初始化
- 一个类有多个构造函数,每个构造函数都有不同的参数,所以需要根据参数锁定构造函数并进行初始化
- 如果即不存在工厂方法也不存在带有参数的构造函数,则使用默认的构造函数进行
bean的实例化
- 首先要来解释一下,为什么称
-
【步骤三】
MergedBeanDefinitionPostProcessor的应用- bean 合并后的处理,Autowire 注解正式通过此方法实现注入类型的预解析。
-
【步骤四】依赖处理
- 在 Spring 中会有循环依赖的情况,例如,当A中含有B的属性,而B中又含有A的属性时就会构成一个循环依赖,此时如果A和B都是单例,那么在Spring中的处理方式就是当创建B的时候,涉及自动注入A的步骤时,并不是直接去再次创建A,而是通过放入缓存中的
ObjectFactory来创建实例,这样就解决了循环依赖的问题。
- 在 Spring 中会有循环依赖的情况,例如,当A中含有B的属性,而B中又含有A的属性时就会构成一个循环依赖,此时如果A和B都是单例,那么在Spring中的处理方式就是当创建B的时候,涉及自动注入A的步骤时,并不是直接去再次创建A,而是通过放入缓存中的
-
【步骤五】属性填充
- 将所有属性填充至
bean的实例中
- 将所有属性填充至
-
【步骤六】循环依赖检查
- 之前有提到过,在Spring中解决循环依赖只对单例有效,而对于
prototype的bean,Spring 没有好的解决方案,唯一要做的就是抛出异常。在这个步骤里面会检测已经加载的 bean 是否已经出现了循环依赖,并判断是否需要抛出异常。
- 之前有提到过,在Spring中解决循环依赖只对单例有效,而对于
-
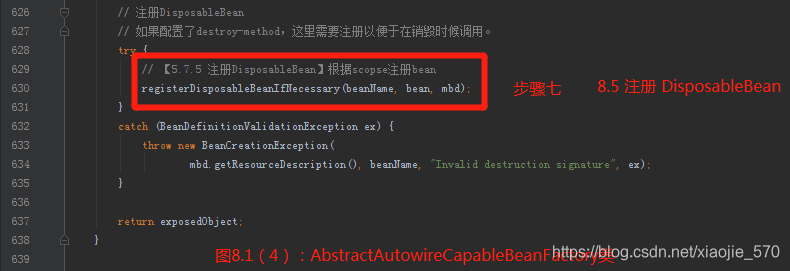
【步骤七】注册
DisposibleBean- 如果配置了
destroy-method,这里需要注册以便于在销毁时候调用。
- 如果配置了
-
【步骤八】完成创建并返回
8.1 创建 Bean 实例
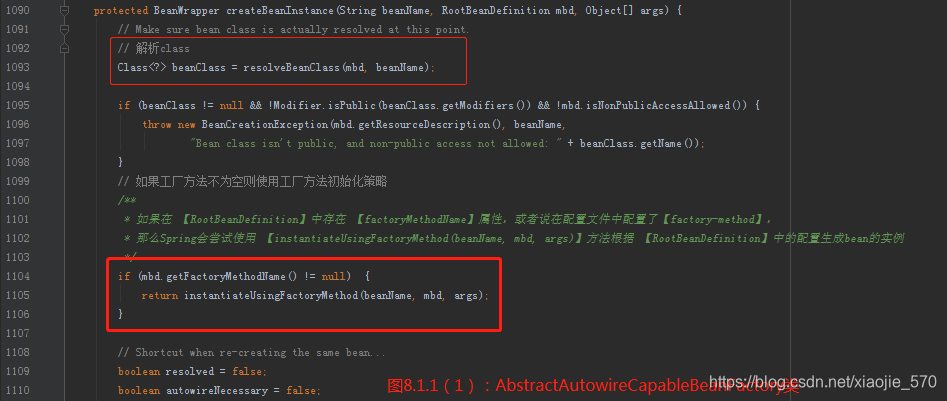
上述代码的逻辑:
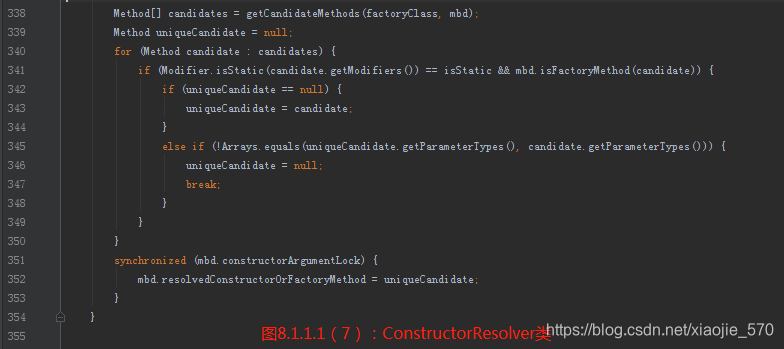
- 如果在
RootBeanDefinition中存在factoryMethodName属性,或者说在配置文件中配置了factory-method,那么spring 会尝试使用instantiateUsingFactoryMethod方法根据RootBeanDefinition中的配置生成 bean 的实例。 - 解析构造函数并进行构造函数的实例化。因为一个 bean 对应的类中可能会存在多个构造函数,而每个构造函数的参数不同,Spring 在根据参数及类型去判断最终会使用哪个构造函数进行实例化。但是判断的过程是一个比较消耗性能的步骤,所以采用缓存机制,如果已经解析过了则不需要重复解析而是直接从
RootBeanDefinition中的属性resolvedConstructorOrFactoryMethod缓存的值去取,否则需要再次解析,并将解析的结果添加至RootBeanDefinition中的属性resolvedConstructorOrFactoryMethod中。
===========================================================================================
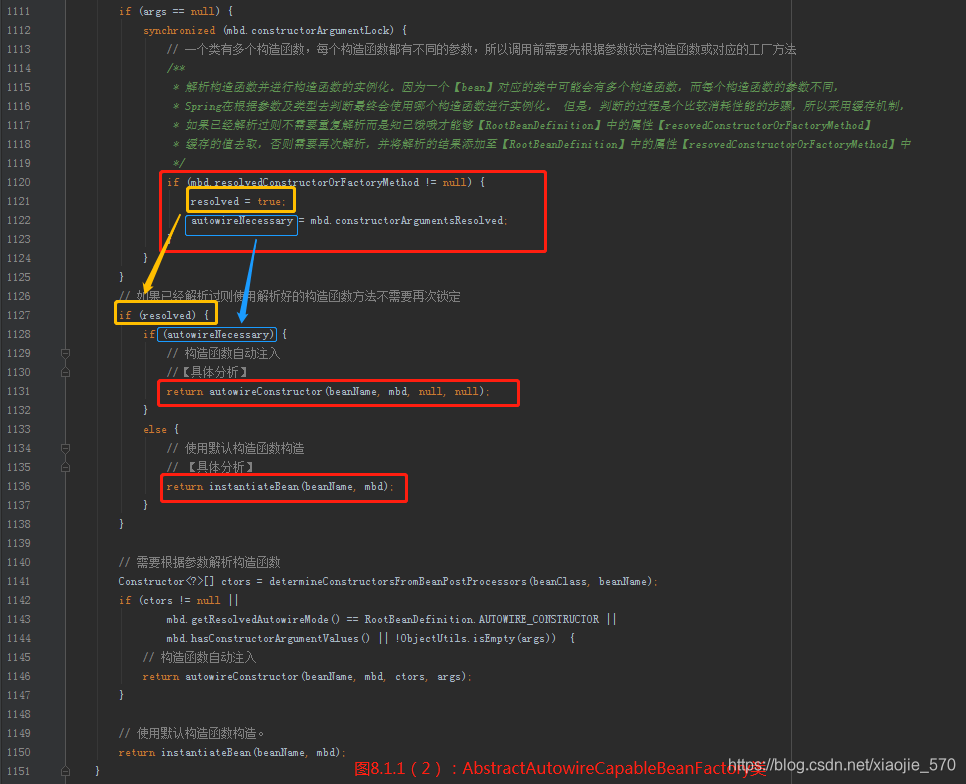
autowireConstructor方法
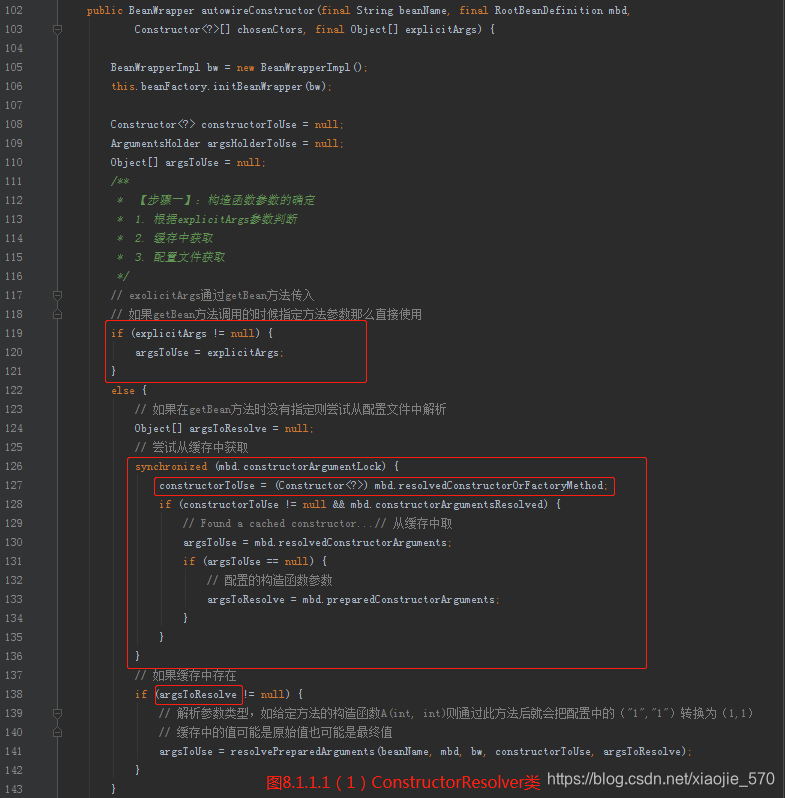
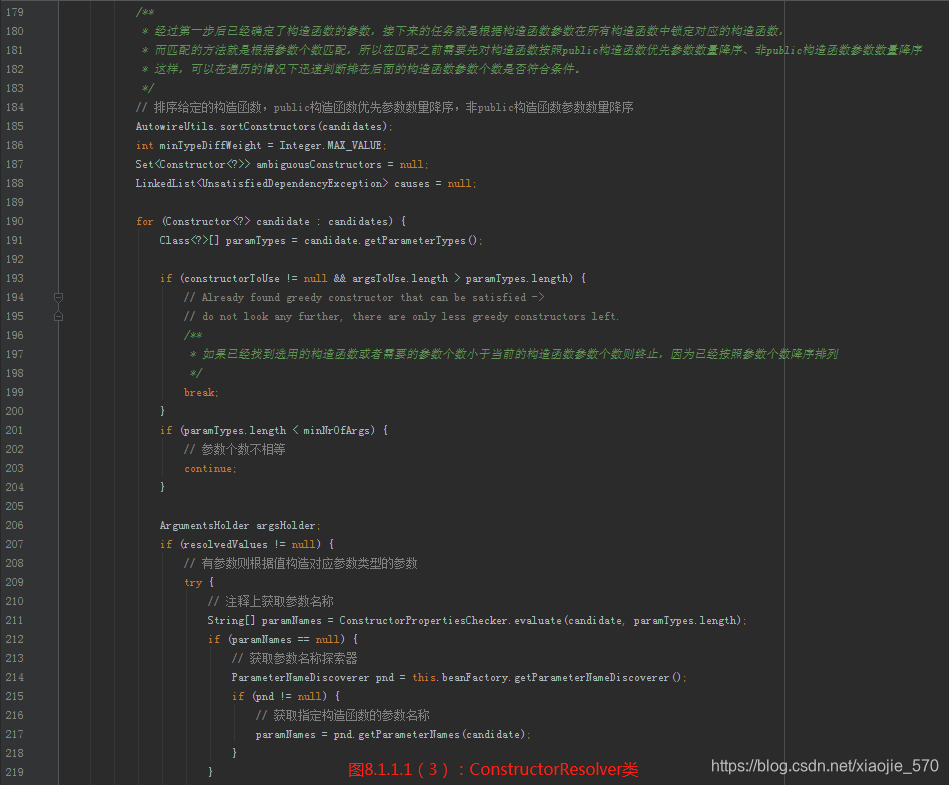
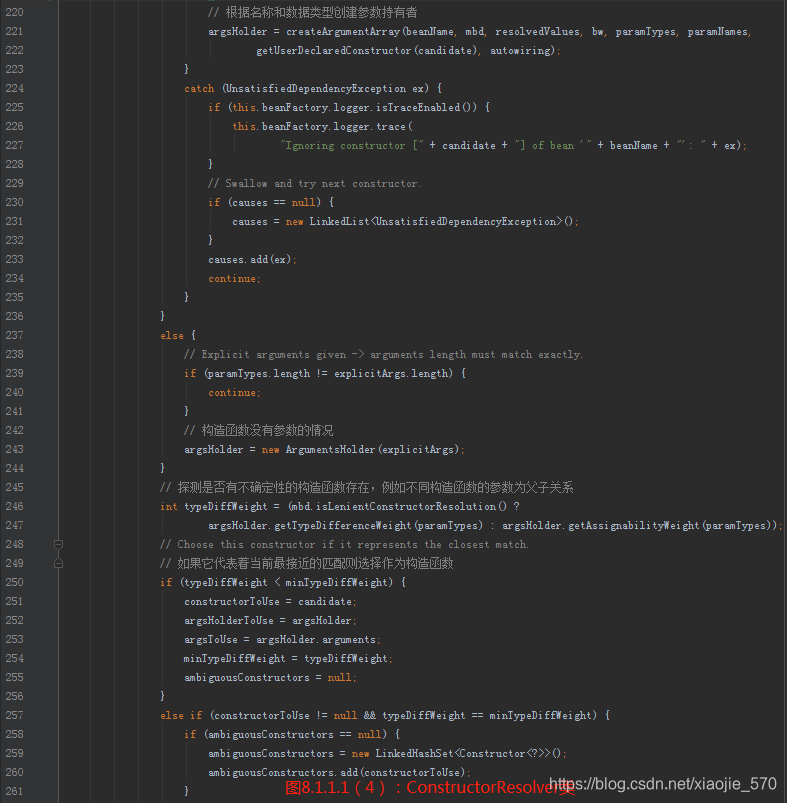
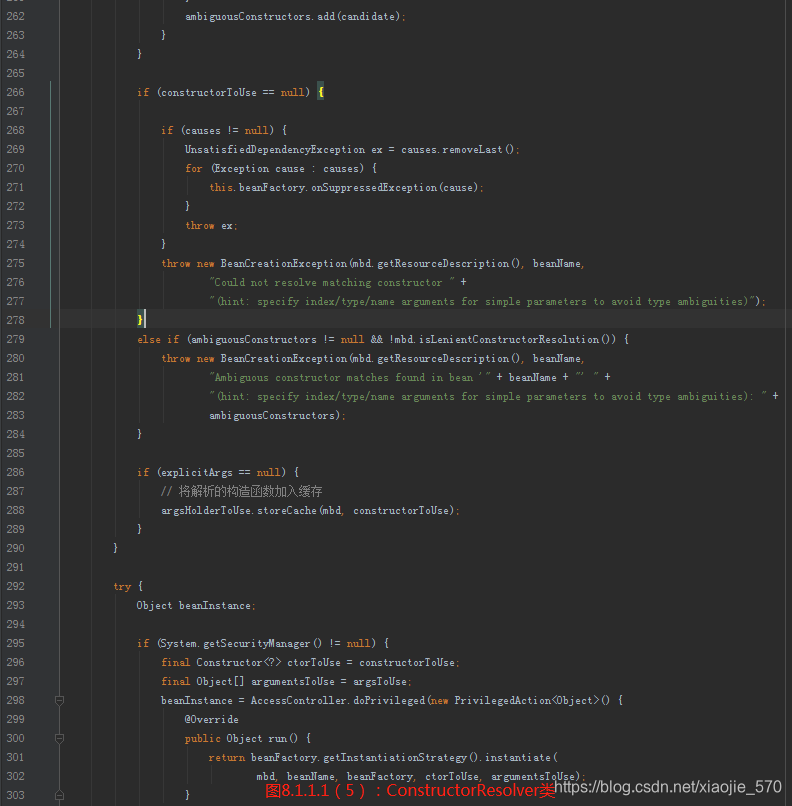
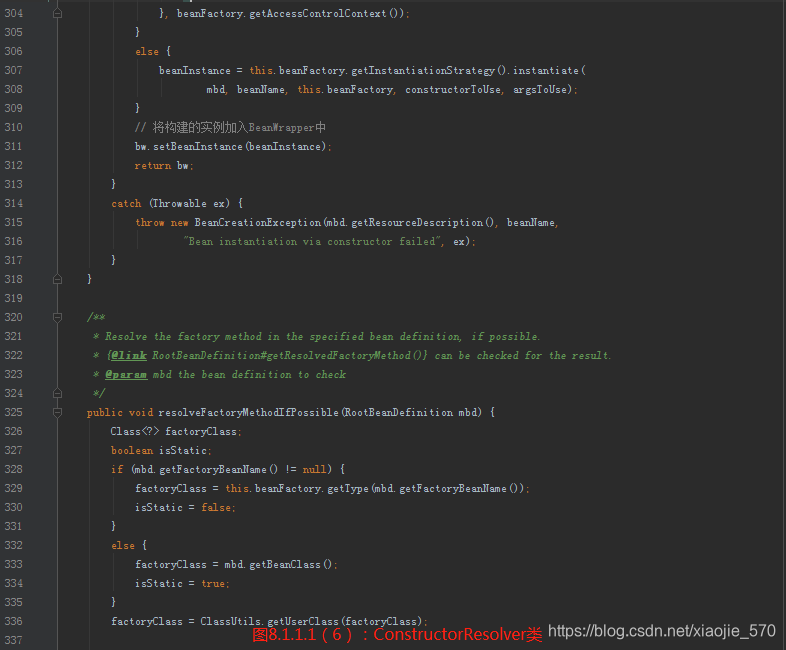
我们总览一下整个函数,其实现的功能考虑了以下几个方面:
-
【步骤一】构造函数参数的确定
-
根据 explicitArgs 参数判断: 如果传入的参数 explicitArgs 不为空,那么可以直接确定参数,因为 explicitArgs 参数是在调用 Bean的时候用户指定的,在BeanFactory 类中存在这样的方法。
Object getBean(String name, Object... args) throws BeansException;
在获取bean的时候,用户不但可以指定 bean 的名称还可以指定 bean 所对应类的构造函数或者工厂方法的方法参数,主要用于静态工厂方法的调用,而这里是需要给定完全匹配的参数的,所以,便于判断,如果传入参数 explicitArgs 不为空,则可以确定构造函数参数就是它。 -
缓存中获取: 除此之外,确定参数的办法如果之前已经分析过,也就是说构造函数参数已经记录在缓存中,那么便可以直接拿来使用。而且,这里要提到的是,在缓存中缓存的可能是参数的最终类型也可能是参数的厨师类型,例如:构造函数参数要求的是
int类型,但是原始的参数值可能是String类型的“1”,那么即使在缓存中得到了参数,也需要经过类型转换器的过滤以确保参数类型与对应的构造函数参数类型完全对应。 -
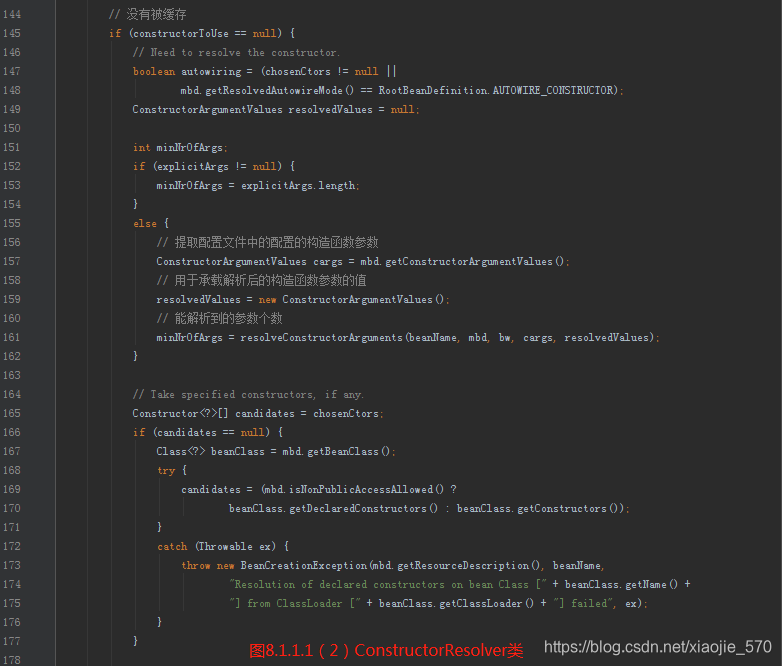
配置文件读取:如果不能根据传入的参数 explicitArgs 确定构造函数的参数也无法在缓存中得到相关信息,那么只能开始新的一轮的分析了。
分析从获取配置文件的构造函数信息开始,经过之前的分析,我们知道,Spring 配置文件中的信息经过转换都会经过BeanDefinition实例承载,也就是参数mbd中包含,那么可以通过调用mbd.getConstructorArgumentValues()来获取配置的构造函数信息。有了配置中的信息便可以获取对应的参数信息了,获取参数值的信息包括直接指定值,如:直接指定构造函数中某个值为原始类型 String 类型,或者是一个对其他 bean 的引用,而这一处理委托给了resolveConstructorArguments方法,并返回能解析到的参数的个数。
-
-
【步骤二】构造函数的确定
- 经过了第一步后已经确定了构造函数的参数,接下来的任务就是根据构造函数参数在所有构造函数中锁定对应的构造函数,而匹配的方法就是根据参数个数匹配,所以在匹配之前需要先对构造函数按照 public构造函数优先参数数量降序、非public构造函数参数数量降序。这样可以在遍历的情况下迅速判断在后面的构造函数参数个数是否符合条件。
- 获取参数名称有两种方式,一种是通过注解的方式直接获取,另一种就是使用Spring 中提供的工具类
ParameterNameDiscoverer来获取。
-
【步骤三】根据确定的构造函数转换对应的参数类型
-
【步骤四】构造函数不确定性的验证
-
【步骤五】根据实例化策略以及得到的构造函数及构造函数参数实例化
Bean。
=============================================================================================
instantiateBean方法

带有参数的实例构造中,Spring把经历都放在了构造函数以及参数的匹配上,所以如果没有参数的话那将是非常简单的一件事,直接调用实例化策略进行实例化就可以了。
=============================================================================================
实例化策略
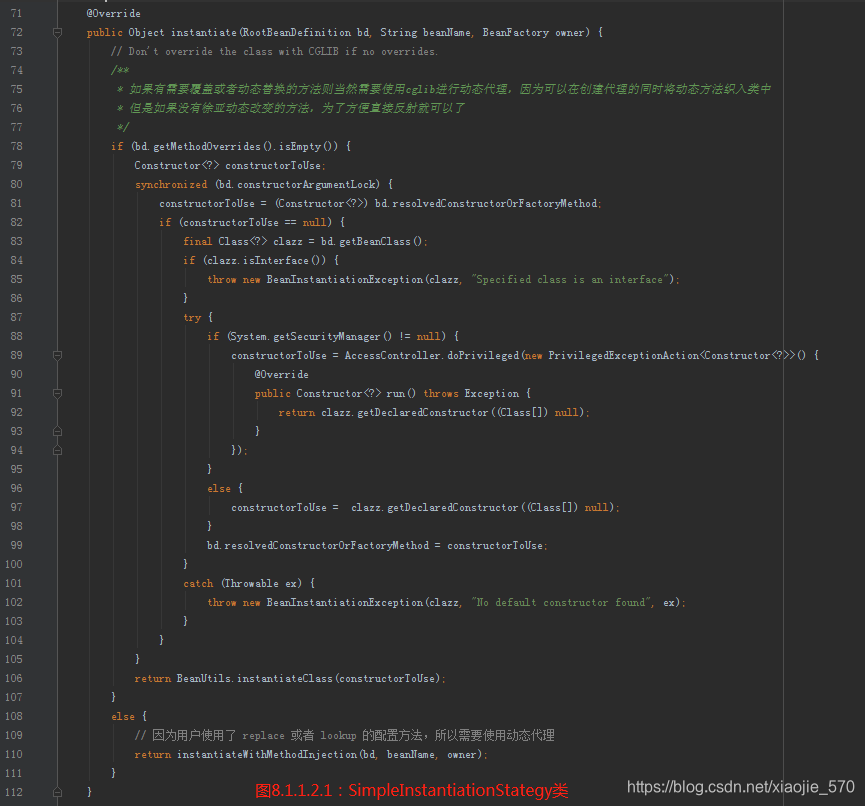
- 首先判断如果
beanDefinition.getMethodOverrides()为空也就是用户没有使用replace或者lookup的配置方法,那么直接使用反射方式。 - 如果用户使用了上面的两个特性,在直接使用反射的方式创建实例就不妥了,因为需要将这两个配置提供的功能切入禁区,所以就必须要使用动态代理的方式将包含两个特性所对应的逻辑的拦截增强器设置进去,这样才可以保证在调用方法的时候会被相应的拦截器增强,返回值为包含拦截器的代理实例。
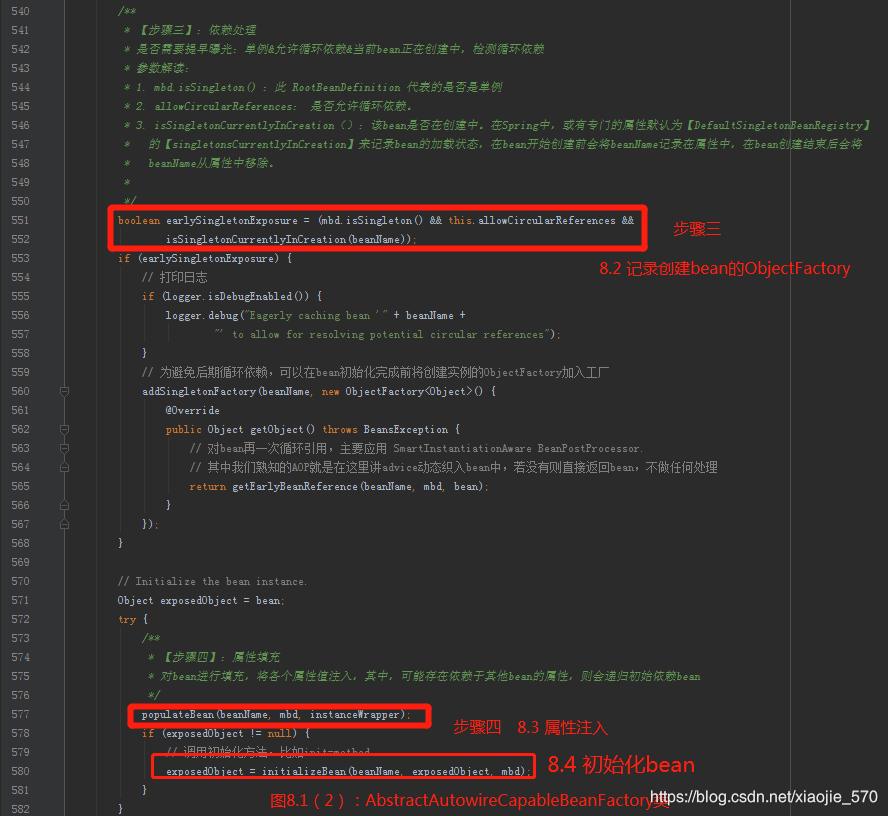
8.2 记录创建 bean 的 ObjectFactory
创建bean实例在8.1中完成了,现在我们回到【图8.1】中的一段代码,注意下图的步骤是三,在bean实例创建完成后,需要记录创建bean 的 ObjectFactory,这步骤主要是为了解决循环依赖的问题。
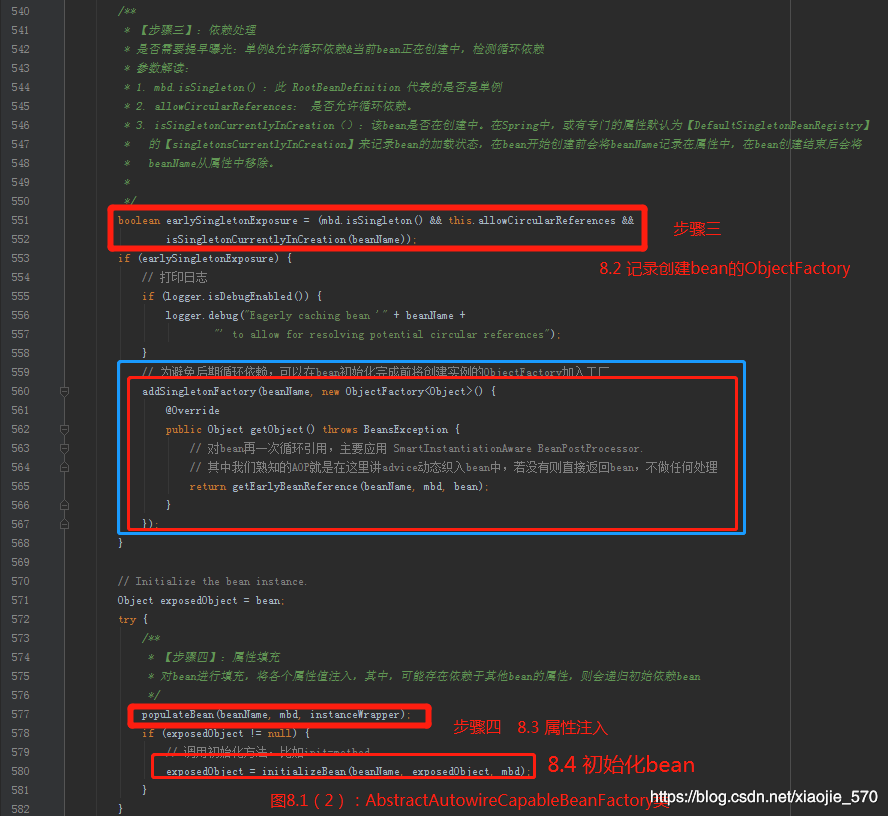
我们知道只有在单例模式下的循环依赖才能被正确处理。那么他是如何处理的呢?先看上图【第551-552行】,这是一个if条件语句,这里需要同时满足三个条件才能将 bean 添加到 ObjectFactory中,那么这三个条件是什么呢?
- 【条件一】是否是单例
- 【条件二】是否允许循环依赖
- 【条件三】是否对应的bean正在创建
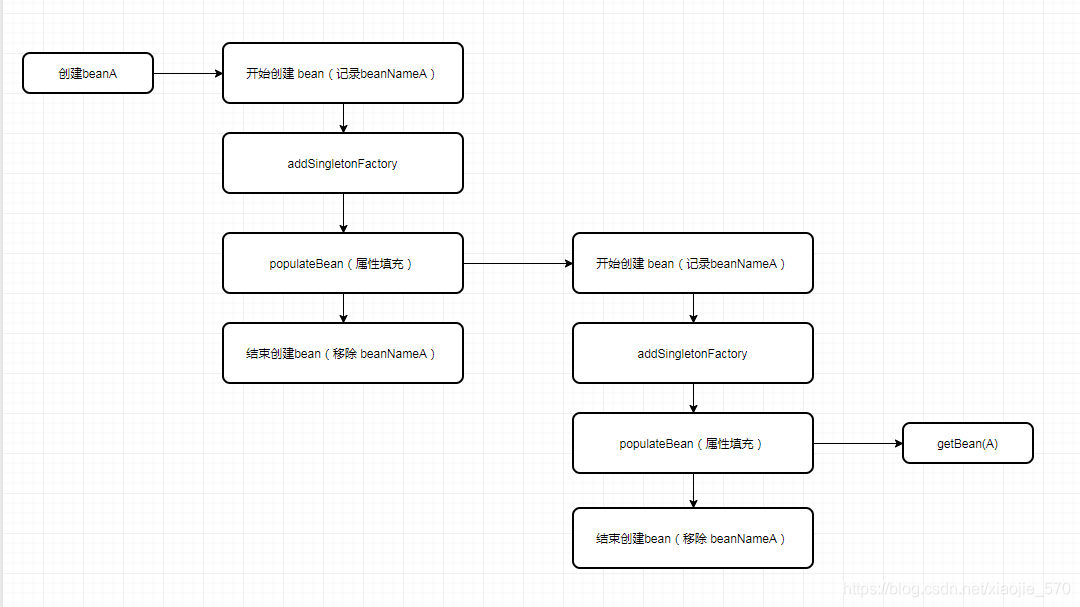
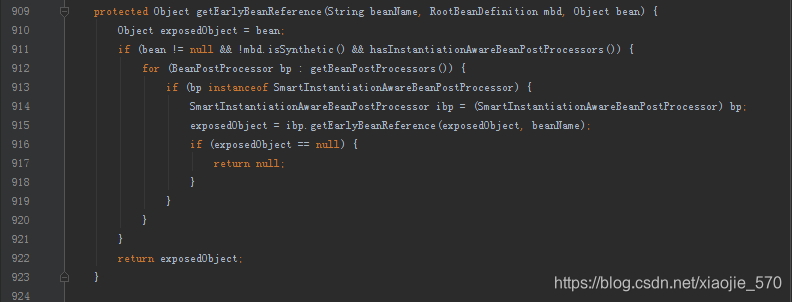
上面的函数没有什么太多的逻辑处理,根据以上分析,基本可以理清Spring处理循环依赖的解决办法,在B中创建依赖A时通过ObjectFactory提供的实例化方法来中断A中的属性填充,使B中持有的A仅仅是刚刚初始化并没有填充任何属性的A,而这正初始化A的步骤还是在最开始创建A的时候进行的,但是因为A与B中的A所表示的属性地址是一样的,所以在A中创建好的属性填充自然可以通过B中的A获取,这样就解决了循环依赖的问题。
8.3 属性注入
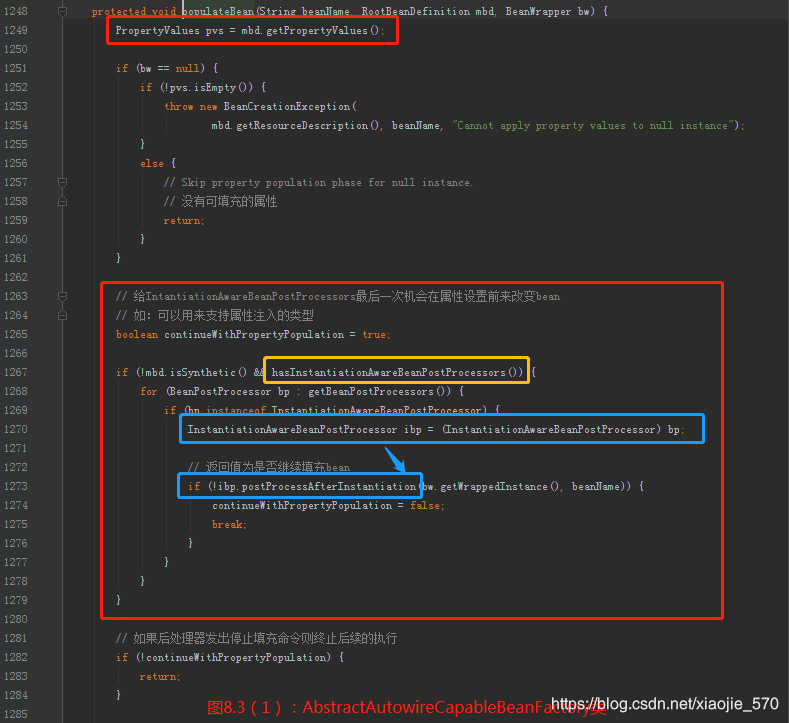
在populateBean 函数中提供了这样的处理流程。
- 【步骤一】
InstantiationAwareBeanPostProcessor处理器的postProcessAfterInstantiatin函数的应用,此函数可以控制程序是否继续进行属性填充 - 【步骤二】根据注入类型(
byName/ byType),提取依赖的 bean,并统一存入PropertyValues中。 - 【步骤三】应用
InstantiationAwareBeanPostProcessor处理器的postProcessPropertyValues方法,对属性获取完毕填充前对属性的再次处理,典型应用是RequiredAnnotationBeanPostProcessor类中对属性的验证 - 【步骤四】将所有
PropertyValues中的属性填充至BeanWrapper中。
=============================================================================================
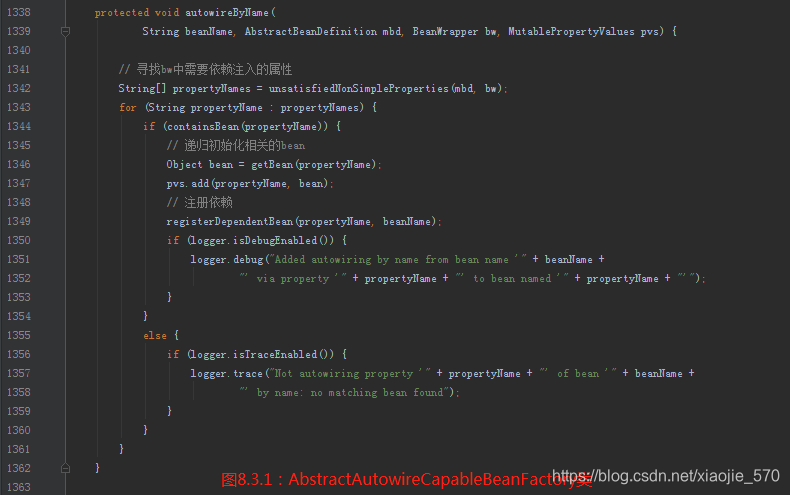
autowireByName方法
=============================================================================================
autowireByType方法
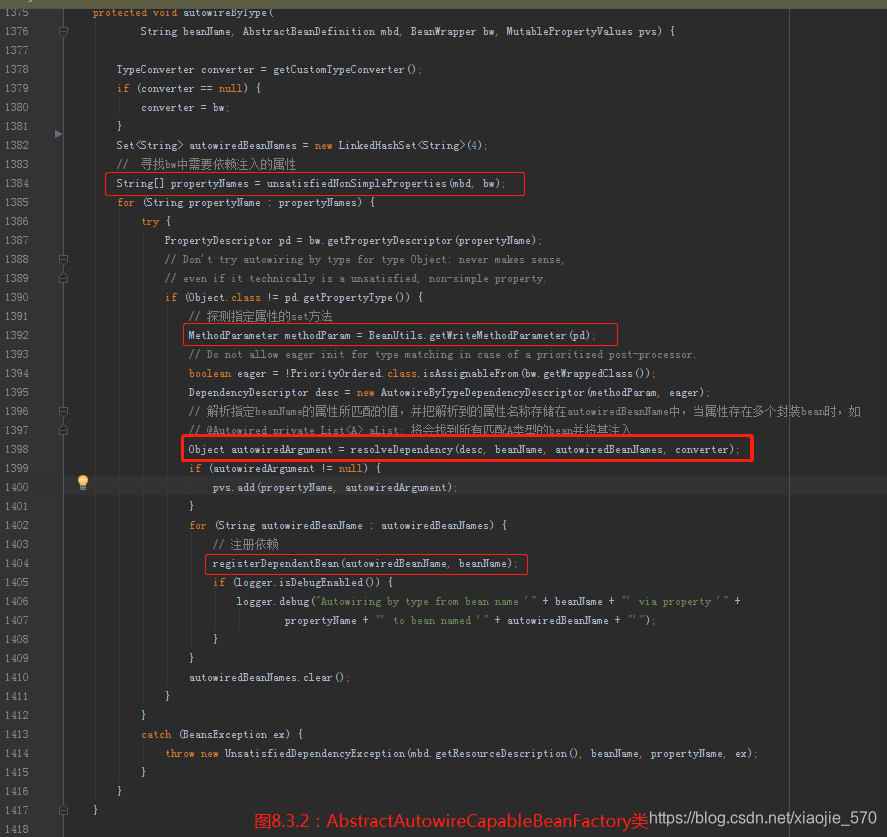
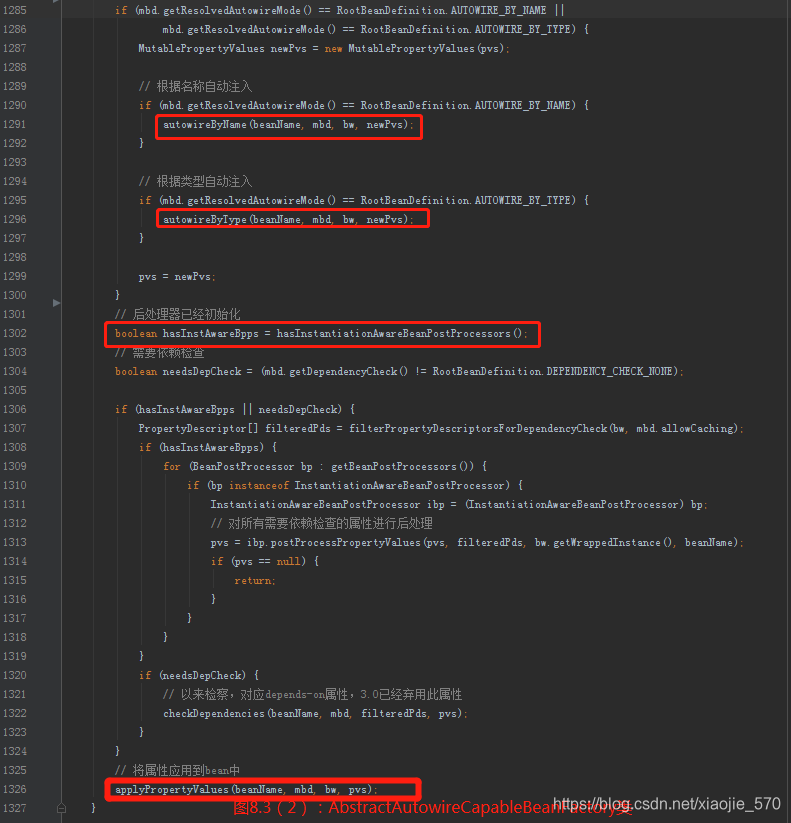
实现根据名称自动匹配的第一步就是寻找 bw 中需要依赖注入的属性,同样对于根据类型自动匹配的实现来讲第一步也是寻找 bw 中需要依赖注入的属性,然后遍历这些属性并寻找类型匹配的 bean。
寻找类型的匹配执行顺序时,首先尝试使用解析器进行解析,如果解析器没有成功解析,那么可能是使用默认的解析器没有做任何处理,或者是使用了自定义的解析器,但是对于集合等类型来说并不在解析范围之内,所以再次对不同类型进行不同情况的处理,虽说对于不同类型处理的方式不一致,但是大致的思路还是很相似的。
=============================================================================================
applyPropertyValues方法
程序运行到这里,已经完成了对所有注入属性的获取,但是获取的属性是以 PropertyValues 形式存在的,还并没有应用到已经实例化的 bean 中,这一工作是在applyPropertyValues中。
8.4 初始化 bean
现在我们已经执行过 bean 的初始化,进行了属性的填充,而就在这时将会调用用户设定的初始化方法。
大家应该记得在 bean 配置时 bean 中有一个 init-method属性,这个属性的作用是在 bean 实例化前调用 init-method 指定的方法来根据用户业务进行相应的实例化。
我们先回到【图8.1(2)】中,看一下初始化bean的调用位置,在【第580行】。
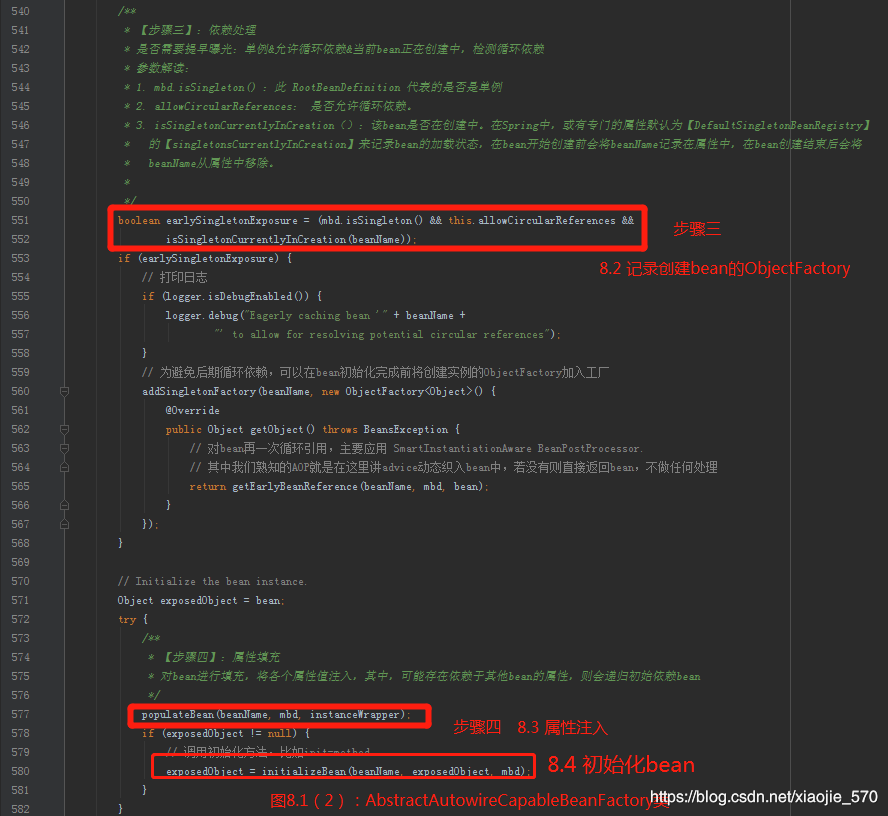
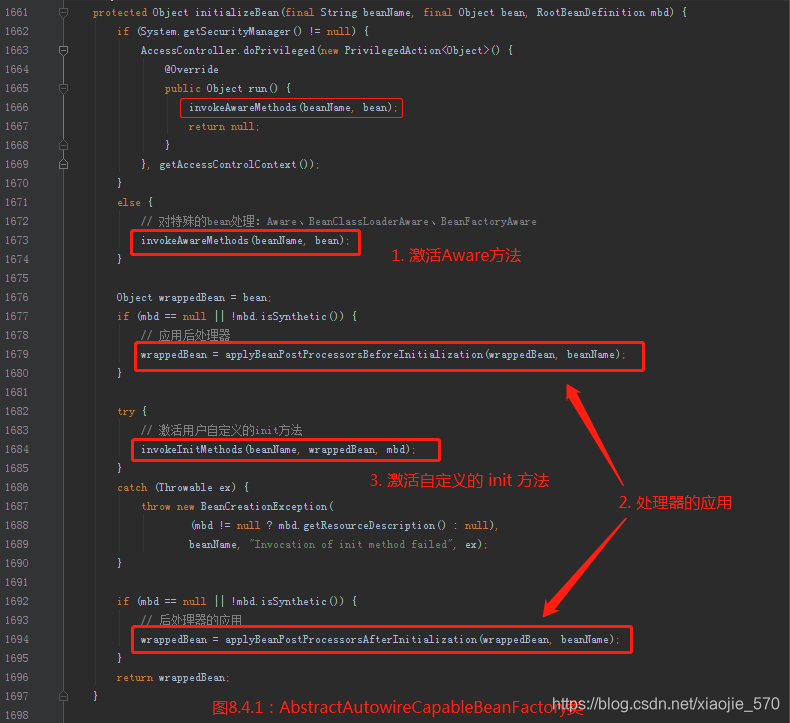
8.4.1 激活 Aware 方法
在分析其原理之前,我们先了解一下 Aware 的使用。Spring 中提供了一些 Aware相关接口,比如 BeanFactoryAware、ApplicationContextAware、ResourceLoaderAware、ServletContextAware等。实现这些 Aware接口的 bean 在初始化之后,可以取得一些相对应的资源。例如实现 BeanFactoryAware 的bean 在 初始化后,Spring 容器将会注入 BeanFactory的实例。
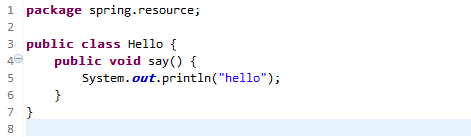
我们首先通过实例方法来了解一下 Aware 的应用。
(1)定义普通的bean
(2)定义 BeanFactoryAware类型的bean
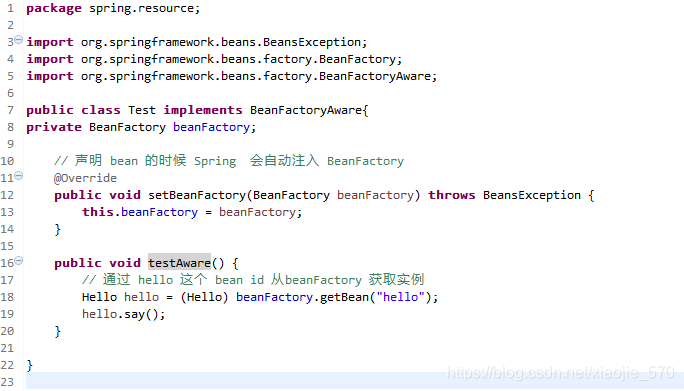
(3)配置文件

(4)使用main方法测试
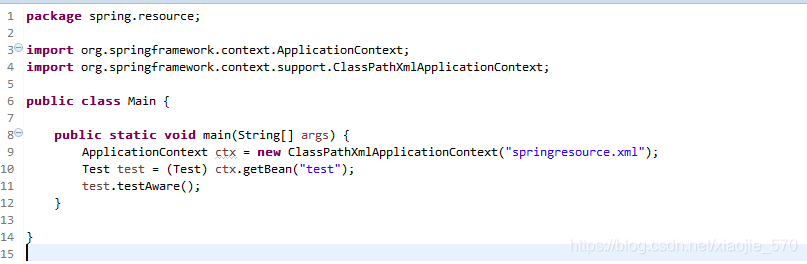
8.2 处理器的应用
BeanPostProcessor 相信大家都不陌生,这是 Spring 中开放式架构中一个必不可少的亮点,给用户充足的权限去更改或者扩展Spring,而除了BeanPostProcessor外还有很多其他的PostProcessor,当然大部分都是以此为基础,继承自BeanPostProcessor。BeanPostProcessor的使用位置就是这里,在调用客户自定义初始化方法前以及调用自定义初始化方法之后分别会调用BeanPostProcessor的 postProcessBeforeInitialization 和 postProcessAfterInitialization 方法,使用户可以根据自己的业务需求进行响应的处理。
8.3 激活自定义的init方法
客户定制的初始化方法除了我们熟知的使用配置init-method外,还有使自定义的 bean 实现 InitializingBean 接口,并在 afterPropertiesSet中实现自己的初始化业务逻辑。
init-method 与 afterPropertiesSet都是在初始化bean时执行,执行顺序是 afterPropertiesSet先执行,而 init-method后执行。