A Generative Entity-Mention Model for Linking Entities with Knowledge Base
主要方法:
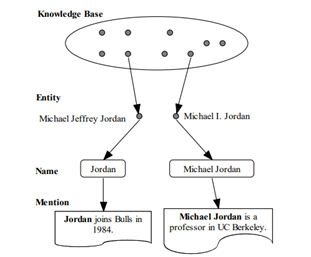
In our model, each name mention to be linked is modeled as a sample generated through a three-step generative story, and the entity knowledge is encoded in the distribution of entities in document P(e), the distribution of possible names of a specific entity P(s|e), and the distribution of possible contexts of a specific entity P(c|e). To find the referent entity of a name mention, our method combines the evidences from all the three distributions P(e), P(s|e) and P(c|e).
The P(e), P(s|e) and P(c|e) are respectively called the entity popularity model, the entity name model and the entity context model
The Generative Entity-Mention Model for Entity Linking
the probability of a name mention m (its context is c and its name is s) referring to a specific entity e can be expressed as the following formula (here we assume that s and c are independent given e):
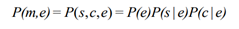
Given a name mention m, to perform entity linking, we need to find the entity e which maximizes the probability P(e|m). Then we can resolve the entity linking task as follows:
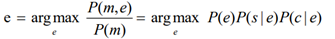
Candidate Selection.:
building a name-to-entity dictionary using the redirect links, disambiguation pages, anchor texts of Wikipedia, then the candidate entities of a name mention are selected by finding its name’s corresponding entry in the dictionary
Model Estimation
- Entity Popularity Model

where Count(e) is the count of the name mentions whose referent entity is e, and the |M| is the total name mention size.
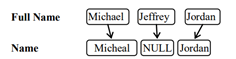
2.Entity Name Model
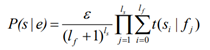
where e is a normalization factor, f is the full name of entity e, lf is the length of f, ls is the length of the name s, si the i th word of s, fj is the j th word of f and t(si|fj) is the lexical translation probability which indicates the probability of a word fj in the full name will be written as si in the output name.
3.Entity Context Model
given a context c containing n terms t1t2…tn, the entity context model estimates the probability P(c|e) as

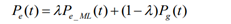
where Pg(t) is a general language model which is estimated using the whole Wikipedia data, and the optimal value of λ is set to 0.2
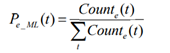
where Counte(t) is the frequency of occurrences of a term t in the contexts of the name mentions whose referent entity is e
4. The NIL Entity Problem
the referent entity may not be contained in the given knowledge base
first add a pseudo entity, the NIL entity, into the knowledge base
if the probability of a name mention is generated by the NIL entity is higher than all other entities in Knowledge base, we link the name mention to the NIL entity.
