资料:
深度学习基础课程
深度学习大讲堂 - 首期第三讲:深度学习基础
前置:
对深度学习基础知识有一定的了解,
进一步了解它们的内涵
概括图

基础结构单元
- 所有op得知道是什么意思
- 全连接层的op
- 卷积层的op
- …
激活函数
- 为什么说激活函数是神经网络非线性性的来源
- 激活函数的取值范围
- 激活函数的导数
损失函数
- 调整网络:
- 调网络结构
- 调损失函数
- eg:给损失函数加权
- 损失函数的物理意义
- 损失函数的导数
网络训练
- 误差反向传播算法
- 如何做参数更新
- Mini-batch SGD
- AdaGrad
- …
深度学习——优化器算法Optimizer详解
- 能不能不用SGD做参数更新呢?比如用 NAG,LSTM
- 如何控制学习率
- 学习率自适应算法
- 如何做参数更新
- 优化:
- 优化目标:
- 优化网络的准确率
- 优化网络的训练速度
- 优化手段:
- 样本加权
- 类别加权
- 损失函数加权
- …
- 优化目标:
全连接层
卷积层
- 稀疏连接
- 权值共享
- 极大地减少了参数数量
- 卷积计算
- 直观层面的理解
- 计算机中具体的实现
- 多通道卷积的快速实现(基于Im2Col操作)
- 根据实际需要编写反向传播过程
- 了解底层是创新的基础
反卷积
卷积的逆过程, 实现信号复原
-
具体用途:
- 全卷积网络(FCN)
- 目标分割,需要给每一个pixel进行分类
- 需要使用反卷积层进行上采样(upsamping)
- 全卷积网络(FCN)
-
生成对抗网络(GAN)
- 反卷积用来生成图片
Pooling层
特点:引入特征的不变性(这也是后面被诟病的原因)
可能存在的缺点:失去了对信息更精准的描述
-
为了提高特征表示的鲁棒性
- 什么是特征表示的鲁棒性
-
Pooling方式
- Max Pooling
- Mean Pooling
- 随机 Pooling (使用的是有就是加权平均 简称期望)
激活函数

sigmod导数的范围:(0, 1/4]
tanh导数范围:(0,1]
--> 使用tanh 梯度下降收敛速度比sigmod快
- 目前最通用的还是relu
- relu有比较好的数据表现一致性
- 其他激活函数在不同的网络结构,不同的数据集,表现效果可能会差别很大…

- 据说 relu 的使用,让 pre-training 失去了意义

- 论文里的原理性讨论还是非常有价值的
dropout

- BN的论文中提到,如果使用了BN,就不需要使用dropout,否则会降低收敛速度
思考:dropout是不是每次都要把一些连接丢掉
不是丢掉,而是让某些神经元输出变成0,但是神经元之间的连接还是保留的,即权重还是保留的
在反向传播的过程中,不调整那些被选中的w
思考:为啥 dropout 有效
- 需要进一步理解这个公式
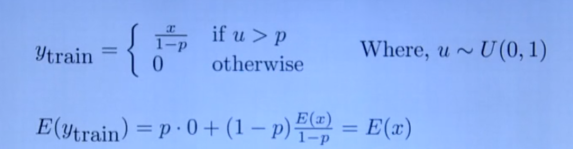
BN (批量归一化)

- 对每一个batch的数据进行标准归一化操作
- 减均值
- 除方差
思考:使用模型的时候,如何处理预测样本的数据
在训练的时候,会计算出平均的均值与方差 ~
实验表明,BN可以非常好的加速深度网络的收敛(应该就是加速 Loss 的收敛吧)
Batch Renormalization

随着深度网络的加深
每一batch的样本数越来越少
最后 moving average 计算出来的均值和方差就越来越不准了
moving average 思想